
mask rcnn解讀
阿新 • • 發佈:2019-01-07
整體框架
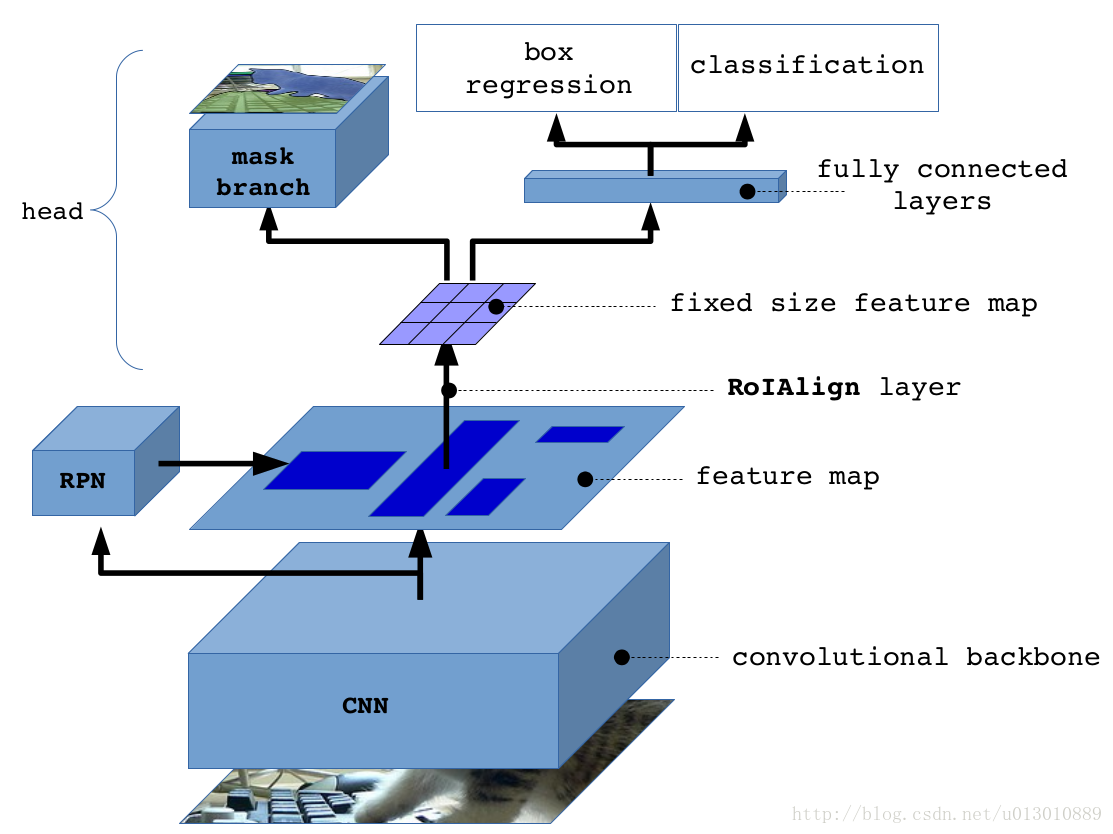
RoIAlign
問題
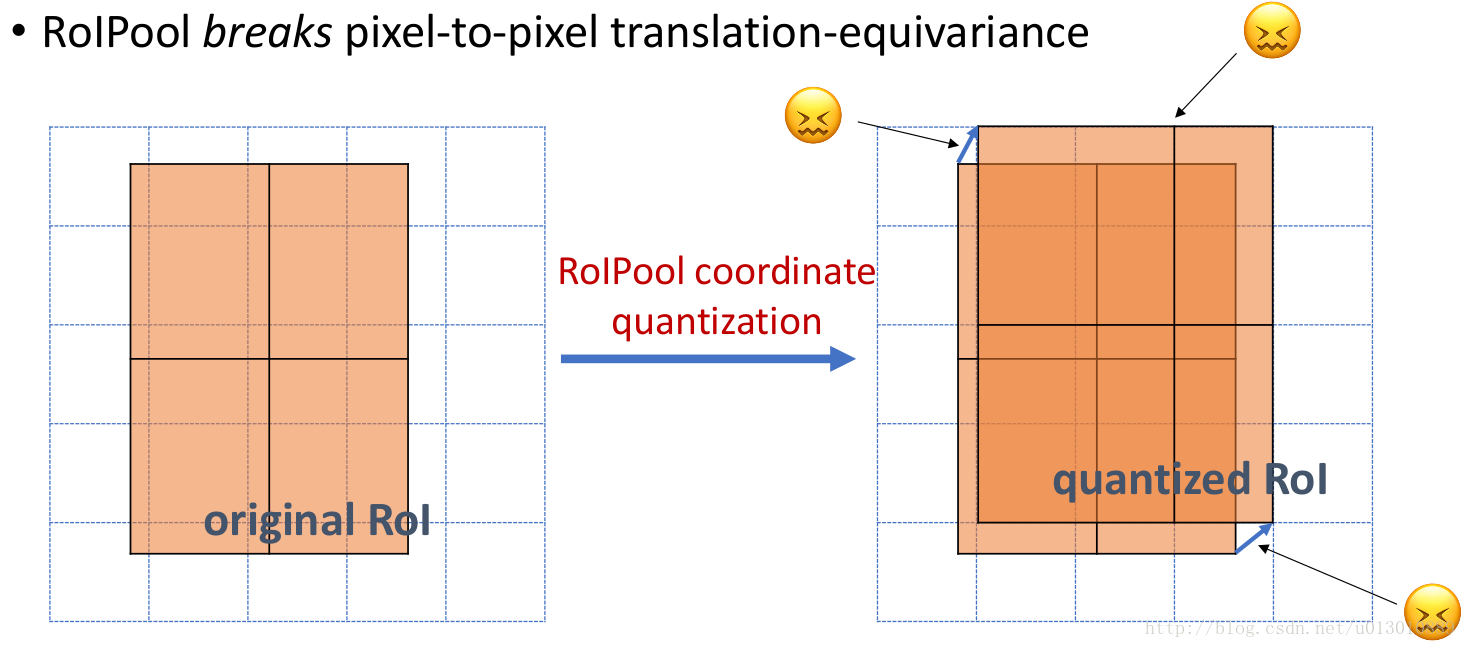
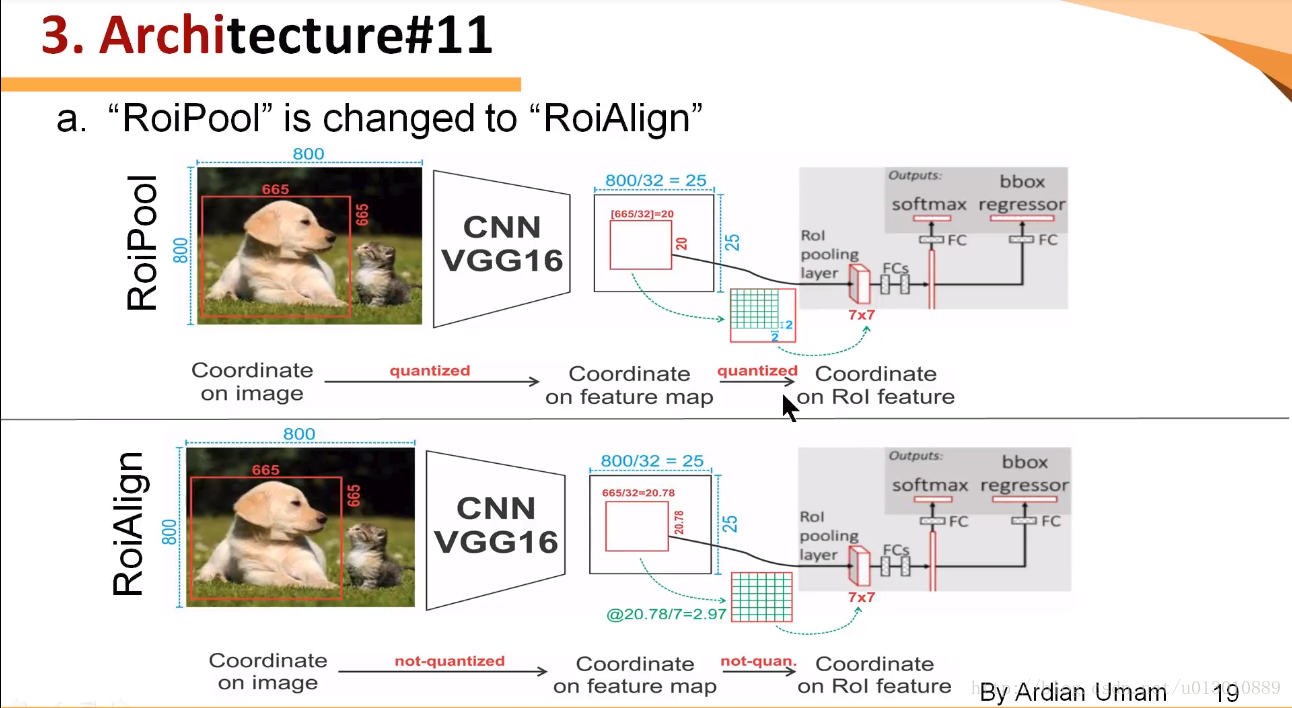
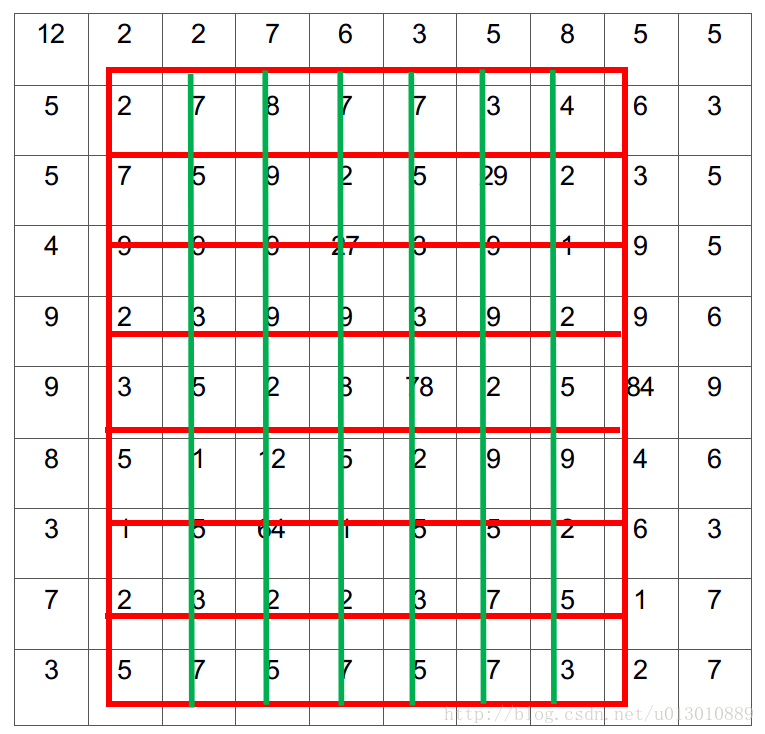
做segment是pixel級別的,但是faster rcnn中roi pooling有2次量化操作導致了沒有對齊
兩次量化,第一次roi對映feature時,第二次roi pooling時(這個圖參考了youtube的視訊,但是感覺第二次量化它畫錯了,根據上一講ross的原始碼,不是縮小了,而是部分bin大小和步長髮生變化)
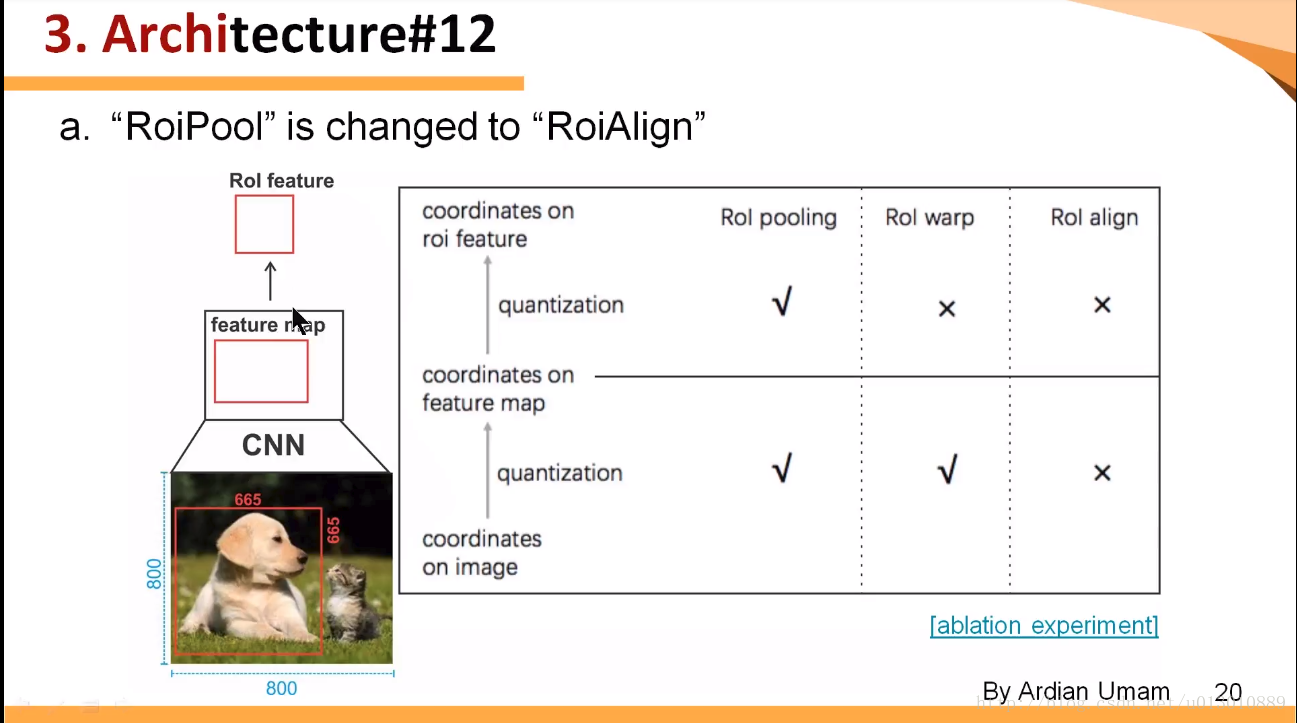
RoIWarp,第一次量化了,第二次沒有,RoIAlign兩次都沒有量化
解決方案
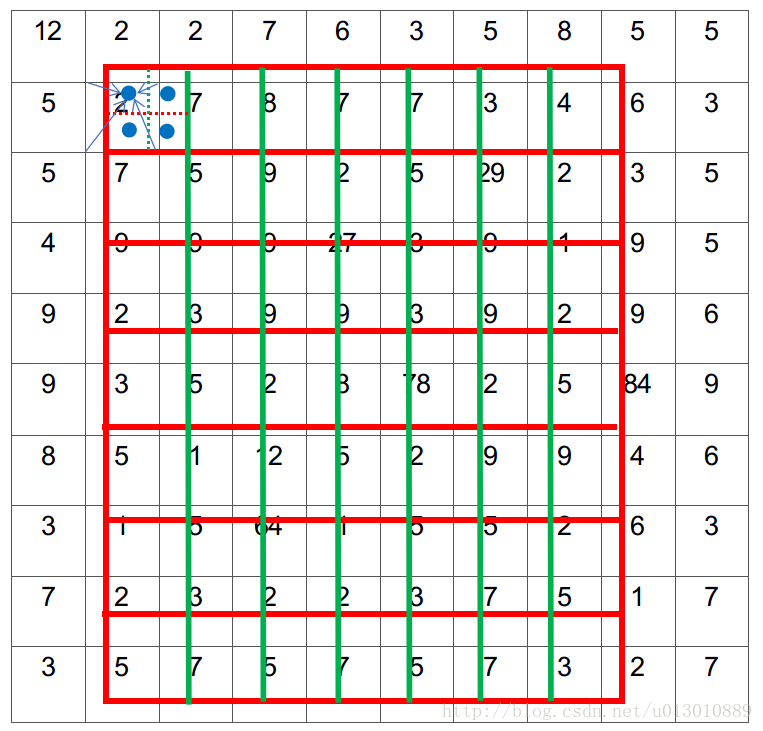
和上一講faster rcnn舉的例子一樣,輸出7*7
劃分7*7的bin(我們可以直接精確的對映到feature map來劃分bin,不用第一次量化)
每個bin中取樣4個點,雙線性插值
對每個bin4個點做max或average pool
# pytorch
# 這是pytorch做法先採樣到14*14,然後max pooling到7*7
pre_pool_size = cfg.POOLING_SIZE * 2
grid = F.affine_grid(theta, torch.Size((rois.size(0), 1, pre_pool_size, pre_pool_size)))
crops = F.grid_sample(bottom.expand(rois.size(0), bottom.size(1), bottom.size(2 sigmoid代替softmax
利用分類的結果,在mask之路,只取對應類別的channel然後做sigmoid,減少類間競爭,避免出現一些洞之類(個人理解)
FPN
詳見我的另一篇部落格FPN解讀
更多
前面我們介紹RoI Align是在每個bin中取樣4個點,雙線性插值,但也是一定程度上解讀了mismatch問題,而曠視科技PLACES instance segmentation比賽中所用的是更精確的解決這個問題,對於每個bin,RoIAlign只用了4個值求平均,而曠視則直接利用積分(把bin中所有位置都插值出來)求和出這一塊的畫素值和然後求平均,這樣更精確了但是很費時。

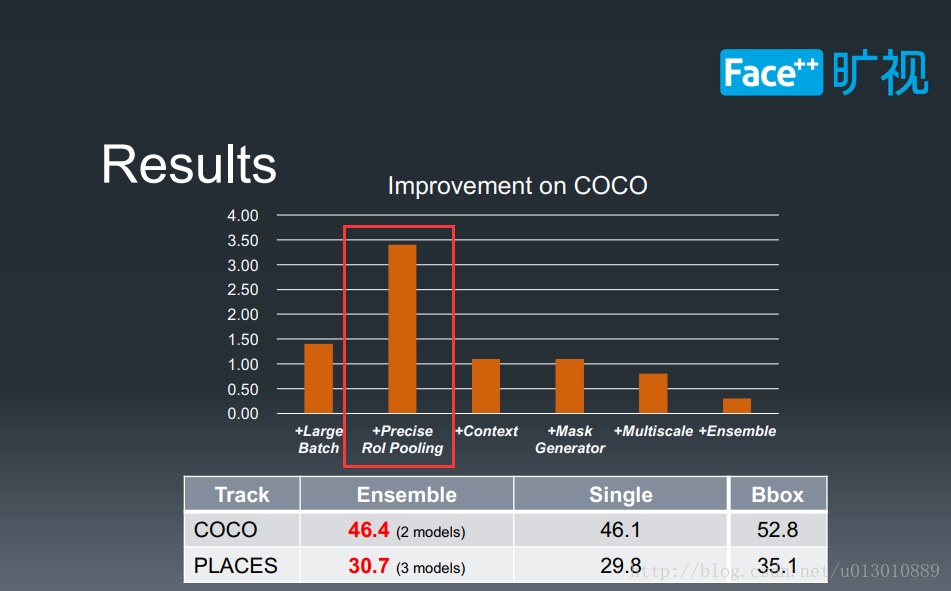
來源曠視科技peng chao分享的video和slides
Detectron部分程式碼細節點
- 無bn,因為batch太小了,使用affine channel
- mask分支,只使用fg_rois,只用前景的rois
- faster rcnn的rpn部分,是生成9*2=18個channel,然後每個格子對應9個anchor,2是前景和背景,使用softmax loss而Detectron中rpn是9個channel,使用sigmoid loss
- 所有的gt box都預設送到後面的fast rcnn和mask等分支中
- 準備gt_masks時,不是用gt_boxes去全圖mask上扣,然後resize到28*28,而是用預測出來的fg_rois去全圖的mask上扣然後resize到28*28,這樣才能正常訓練的mask分支,不然gt_masks的位置根本不對。這和我們採用gt_classes去抽取對應channel的score map做sigmoid一樣,目的都是為了能讓mask分支受到正常的監督,因為我們自己預測的類別可能是錯的,這樣抽取錯誤的channel去做sigmoid然後與gt_masks做loss,是錯誤的監督。