
隨機森林演算法梳理
- 整合學習:通過構建並結合多個學習器來完成學習任務。先產生一組“個體學習器”,再用某種策略將它們結合起來。整合學習的核心是個體學習器以及整合策略,通常整合學習能夠獲得比單一學習器具有更優越的泛化效能;
- 個體學習器:個體學習器是傳統機器學習或者神經網路訓練學習的學習器,按照個體的性質將整合學習分成同質與異質整合。
(1)同質整合:個體學習器均為同一類個體學習器,比如均為決策樹或者均為神經網路;
(2) 異質整合:個體學習器為不同型別個體學習器,比如決策樹與神經網路一起構成新的學習器;異質整合:個體學習器為不同型別個體學習器,比如決策樹與神經網路一起構成新的學習器;
常見的整合學習方法:boosting(個體學習器存在強依賴關係,必須序列生成的序列化方法),bagging(比如隨機森林(Random Forest))(個體學習器不存在強依賴關係,可以並行生成);
3.Boosting是一族可將弱學習器提升為強學習器的演算法。先從初始訓練集訓練出一個基學習器,再根據基學習器的表現對訓練樣本分佈進行調整,使得先前基學習器做錯的訓練樣本後續得到更多關注。常用的演算法是AdaBoost和GradientBoosting
關於Boosting的兩個核心問題:
A)在每一輪如何改變訓練資料的權值或概率分佈?
通過提高那些在前一輪被弱分類器分錯樣例的權值,減小前一輪分對樣例的權值,來使得分類器對誤分的資料有較好的效果。
B)通過什麼方式來組合弱分類器?
通過加法模型將弱分類器進行線性組合,比如AdaBoost通過加權多數表決的方式,即增大錯誤率小的分類器的權值,同時減小錯誤率較大的分類器的權值。而提升樹通過擬合殘差的方式逐步減小殘差,將每一步生成的模型疊加得到最終模型。
4.bagging是並行整合學習著名代表,採取放回取樣的方式抽取資料訓練多個個體學習器,可以取樣出T個含有m個訓練樣本的學習器,每個學習可以並行訓練。Bagging主要關注的是降低方差,並且自助取樣的方式會使得其具有一部分的驗證樣本,這樣就使得泛化效果更好。其演算法過程如下:
A)從原始樣本集中抽取訓練集。每輪從原始樣本集中使用Bootstraping的方法抽取n個訓練樣本(在訓練集中,有些樣本可能被多次抽取到,而有些樣本可能一次都沒有被抽中)。共進行k輪抽取,得到k個訓練集。(k個訓練集之間是相互獨立的)
B)每次使用一個訓練集得到一個模型,k個訓練集共得到k個模型。(注:這裡並沒有具體的分類演算法或迴歸方法,我們可以根據具體問題採用不同的分類或迴歸方法,如決策樹、感知器等)
C)對分類問題:將上步得到的k個模型採用投票的方式得到分類結果;對迴歸問題,計算上述模型的均值作為最後的結果。(所有模型的重要性相同)
總的來說,Bagging的訓練樣本在每次訓練的時候,是通過抽樣採取;而Boosting的核心是每次訓練樣本都是一樣的,但是訓練時候的訓練樣本的權重不一樣。
1)Bagging + 決策樹 = 隨機森林
2)AdaBoost + 決策樹 = 提升樹
3)Gradient Boosting + 決策樹 = GBDT
5.結合策略:
學習器結合可能會從三個方面帶來好處,第一是從統計學方面來說,由於學習任務的假設空間往往很大,可能有多個假設在訓練集上達到同等心梗,此時若使用單學習器可能因武宣而導致泛化效能很低;第二,從計算方面看,學習演算法旺旺會陷入區域性極小點,因此泛化效能很差;第三從表示方面多個學習器結合,會加大假設空間,這樣泛化效能更加好。
常用的學習器結合策略:所謂的策略都是結合多個個體學習器的假設函式求得最終學習器的假設函式。
-
- 簡單平均法
對於迴歸預測類問題,通常使用的結合策略是平均法,通過對若干個弱學習器的輸出進行平均得到最終的預測輸出。其中包括算術平均和加權平均,一般而言,在個體學習器的效能相差較大時宜使用加權平均法,而在個體學習器效能相近時宜使用簡單平均法。
- 簡單平均法
- [ a] 算術平均:
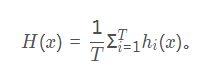
-
[b ] 加權平均:
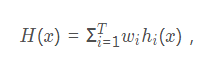

加權平均法的權重是從訓練資料中學習而得,在現實任務中的訓練樣本通常不充分或存在噪聲,使得學習的權重不一定可靠。因此,一般地在個體學習器效能相差較大時宜採用加權平均法,而在個體學習器效能相近時使用簡單平均法。 -
- 投票法:
對於分類問題,常用投票法(voting)。常見有三種投票法:
- 投票法:
-
[a ] 絕對多數投票法(majority voting):
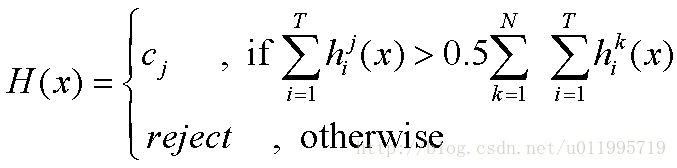 其中T表示有T個分類器,N表示有N種類別。意思就是,T個分類器對類別j的預測結果若大於總投票結果的一半,那麼就預測是類別j,否則就拒絕預測。
其中T表示有T個分類器,N表示有N種類別。意思就是,T個分類器對類別j的預測結果若大於總投票結果的一半,那麼就預測是類別j,否則就拒絕預測。 -
[ b] 相對多數投票法(plurality voting):即得票最多的那個類別為預測類別。
-
[c] 加權投票法(weighted voting) : 在分類任務中,不同型別的個體學習器產生不同型別的 。通常有兩種,一個是類標記,如決策樹,使用類標記的投票稱為硬投票(hard voting);一個是類概率,如貝葉斯分類器,使用類概率的投票稱為軟投票(soft voting)
-
- 學習法:最終的輸出是把個體學習器的輸出 輸入到一個學習器,最終得到預測結果,可以理解為多個學習器的級聯;
6.隨機森林:
隨機森林屬於整合學習(Ensemble Learning)中的bagging演算法,是一種特殊的bagging方法,它將決策樹用作bagging中的模型。
(1)核心思想:
核心思想就是將多個不同的決策樹進行組合,利用這種組合降低單一決策樹有可能帶來的片面性和判斷不準確性。具體來講,隨機森林是用隨機的方式建立一個森林,隨機森林是由很多的決策樹組成,但每一棵決策樹之間是沒有關聯的。在得到森林之後,當對一個新的樣本進行判斷或預測的時候,讓森林中的每一棵決策樹分別進行判斷,看看這個樣本應該屬於哪一類(對於分類演算法),然後看看哪一類被選擇最多,就預測這個樣本為那一類。
(2)隨機森林推廣:
-
[ a] extra trees
extra trees是RF的一個變種, 原理幾乎和RF一模一樣,僅有區別有:
1) 對於每個決策樹的訓練集,RF採用的是隨機取樣bootstrap來選擇取樣集作為每個決策樹的訓練集,而extra trees一般不採用隨機取樣,即每個決策樹採用原始訓練集。
2) 在選定了劃分特徵後,RF的決策樹會基於基尼係數,均方差之類的原則,選擇一個最優的特徵值劃分點,這和傳統的決策樹相同。但是extra trees比較的激進,他會隨機的選擇一個特徵值來劃分決策樹。
從第二點可以看出,由於隨機選擇了特徵值的劃分點位,而不是最優點位,這樣會導致生成的決策樹的規模一般會大於RF所生成的決策樹。也就是說,模型的方差相對於RF進一步減少,但是偏倚相對於RF進一步增大。在某些時候,extra trees的泛化能力比RF更好。 -
[ b] Totally Random Trees Embedding
Totally Random Trees Embedding(以下簡稱 TRTE)是一種非監督學習的資料轉化方法。它將低維的資料集對映到高維,從而讓對映到高維的資料更好的運用於分類迴歸模型。我們知道,在支援向量機中運用了核方法來將低維的資料集對映到高維,此處TRTE提供了另外一種方法。
TRTE在資料轉化的過程也使用了類似於RF的方法,建立T個決策樹來擬合數據。當決策樹建立完畢以後,資料集裡的每個資料在T個決策樹中葉子節點的位置也定下來了。比如我們有3顆決策樹,每個決策樹有5個葉子節點,某個資料特徵x劃分到第一個決策樹的第2個葉子節點,第二個決策樹的第3個葉子節點,第三個決策樹的第5個葉子節點。則x對映後的特徵編碼為(0,1,0,0,0, 0,0,1,0,0, 0,0,0,0,1), 有15維的高維特徵。這裡特徵維度之間加上空格是為了強調三顆決策樹各自的子編碼。
對映到高維特徵後,可以繼續使用監督學習的各種分類迴歸演算法了。
- [c ]Isolation Forest
Isolation Forest(以下簡稱IForest)是一種異常點檢測的方法。它也使用了類似於RF的方法來檢測異常點。
對於在T個決策樹的樣本集,IForest也會對訓練集進行隨機取樣,但是取樣個數不需要和RF一樣,對於RF,需要取樣到取樣集樣本個數等於訓練集個數。但是IForest不需要取樣這麼多,一般來說,取樣個數要遠遠小於訓練集個數?為什麼呢?因為我們的目的是異常點檢測,只需要部分的樣本我們一般就可以將異常點區別出來了。
對於每一個決策樹的建立, IForest採用隨機選擇一個劃分特徵,對劃分特徵隨機選擇一個劃分閾值。這點也和RF不同。
另外,IForest一般會選擇一個比較小的最大決策樹深度max_depth,原因同樣本採集,用少量的異常點檢測一般不需要這麼大規模的決策樹。
(3)隨機森林的優缺點:
RF的主要優點有:
1) 訓練可以高度並行化,對於大資料時代的大樣本訓練速度有優勢。個人覺得這是的最主要的優點。
2) 由於可以隨機選擇決策樹節點劃分特徵,這樣在樣本特徵維度很高的時候,仍然能高效的訓練模型。
3) 在訓練後,可以給出各個特徵對於輸出的重要性
4) 由於採用了隨機取樣,訓練出的模型的方差小,泛化能力強。
5) 相對於Boosting系列的Adaboost和GBDT, RF實現比較簡單。
6) 對部分特徵缺失不敏感。
RF的主要缺點有:
1)在某些噪音比較大的樣本集上,RF模型容易陷入過擬合。
2) 取值劃分比較多的特徵容易對RF的決策產生更大的影響,從而影響擬合的模型的效果。
(4)隨機森林sklearn的引用程式碼sklearn.ensemble.RandomForestClassifier(
n_estimators=10, criterion=‘gini’, max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_features=‘auto’, max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=1,
random_state=None, verbose=0, warm_start=False, class_weight=None) -
[ a] sklearn中決策樹的引數:
–criterion: ”gini” or “entropy”(default=”gini”)是計算屬性的gini(基尼不純度)還是entropy(資訊增益),來選擇最合適的節點。
–splitter: ”best” or “random”(default=”best”)隨機選擇屬性還是選擇不純度最大的屬性,建議用預設。
–max_features: 選擇最適屬性時劃分的特徵不能超過此值。當為整數時,即最大特徵數;當為小數時,訓練集特徵數*小數;
if “auto”, then max_features=sqrt(n_features).
If “sqrt”, thenmax_features=sqrt(n_features).
If “log2”, thenmax_features=log2(n_features).
If None, then max_features=n_features.
–max_depth: (default=None)設定樹的最大深度,預設為None,這樣建樹時,會使每一個葉節點只有一個類別,或是達到min_samples_split。
–min_samples_split:根據屬性劃分節點時,每個劃分最少的樣本數。
–min_samples_leaf:葉子節點最少的樣本數。
–max_leaf_nodes: (default=None)葉子樹的最大樣本數。
–min_weight_fraction_leaf: (default=0) 葉子節點所需要的最小權值
–verbose:(default=0) 是否顯示任務程序 -
[ b] 隨機森林特有的引數:
-
n_estimators=10:決策樹的個數,越多越好,但是效能就會越差,至少100左右(具體數字忘記從哪裡來的了)可以達到可接受的效能和誤差率。
-
bootstrap=True:是否有放回的取樣。
-
oob_score=False:oob(out of band,帶外)資料,即:在某次決策樹訓練中沒有被bootstrap選中的資料。多單個模型的引數訓練,我們知道可以用cross validation(cv)來進行,但是特別消耗時間,而且對於隨機森林這種情況也沒有大的必要,所以就用這個資料對決策樹模型進行驗證,算是一個簡單的交叉驗證。效能消耗小,但是效果不錯。
-
n_jobs=1:並行job個數。這個在ensemble演算法中非常重要,尤其是bagging(而非boosting,因為boosting的每次迭代之間有影響,所以很難進行並行化),因為可以並行從而提高效能。1=不併行;n:n個並行;-1:CPU有多少core,就啟動多少job。
-
warm_start=False:熱啟動,決定是否使用上次呼叫該類的結果然後增加新的。
-
class_weight=None:各個label的權重。
-
[ c] 進行預測可以有幾種形式:
-
predict_proba(x):給出帶有概率值的結果。每個點在所有label的概率和為1.
-
predict(x):直接給出預測結果。內部還是呼叫
-
predict_proba(),根據概率的結果看哪個型別的預測值最高就是哪個型別。
-
predict_log_proba(x):和predict_proba基本上一樣,只是把結果給做了log()處理。
參考連結:
https://blog.csdn.net/starter_____/article/details/79328749
https://blog.csdn.net/loveliuzz/article/details/78758000
https://blog.csdn.net/u011995719/article/details/77863248
https://www.cnblogs.com/pinard/p/6156009.html