
機器學習—隨機森林演算法
作者:WenWu_Both
出處:http://blog.csdn.net/wenwu_both/article/
版權:本文版權歸作者和CSDN部落格共有
轉載:歡迎轉載,但未經作者同意,必須保留此段宣告;必須在文章中給出原文連結;否則必究法律責任
(1) 隨機森林基本原理
隨機森林幾乎是任何預測類問題(甚至非線性問題)的首選。隨機森林是相對較新的機器學習策略(出自90年代的貝爾實驗室),可應用於幾乎所用問題。它隸屬於更大的一類機器學習演算法,叫做“整合方法”(ensemble methods)。
隨機森林由LeoBreiman(2001)提出,它通過自助法(bootstrap)重取樣技術,從原始訓練樣本集N中有放回地重複隨機抽取k個樣本生成新的訓練樣本集合,然後根據自助樣本集生成k個分類樹組成隨機森林,新資料的分類結果按分類樹投票多少形成的分數而定。其實質是對決策樹演算法的一種改進,將多個決策樹合併在一起,每棵樹的建立依賴於一個獨立抽取的樣品,森林中的每棵樹具有相同的分佈,分類誤差取決於每一棵樹的分類能力和它們之間的相關性。特徵選擇採用隨機的方法去分裂每一個節點,然後比較不同情況下產生的誤差。能夠檢測到的內在估計誤差、分類能力和相關性決定選擇特徵的數目。
決策樹為基本模型的bagging在每次bootstrap放回抽樣之後,產生一棵決策樹,抽多少樣本就生成多少棵樹,在生成這些樹的時候沒有進行更多的干預。而隨機森林也是進行bootstrap抽樣,但它與bagging的區別是:在生成每棵樹的時候,每個節點變數都僅僅在隨機選出的少數變數中產生。因此,不但樣本是隨機的,連每個節點變數(Features)的產生都是隨機的。
(2)建立決策樹
在建立每一棵決策樹的過程中,有兩點需要注意取樣與完全分裂。首先是兩個隨機取樣的過程,random forest對輸入的資料要進行行、列的取樣。對於行取樣,採用有放回的方式,也就是在取樣得到的樣本集合中,可能有重複的樣本。假設輸入樣本為N個,那麼取樣的樣本也為N個。這樣使得在訓練的時候,每一棵樹的輸入樣本都不是全部的樣本,使得相對不容易出現over-fitting。然後進行列取樣,從M個feature中,選擇m個(m << M)。之後就是對取樣之後的資料使用完全分裂的方式建立出決策樹,這樣決策樹的某一個葉子節點要麼是無法繼續分裂的,要麼裡面的所有樣本的都是指向的同一個分類。一般很多的決策樹演算法都一個重要的步驟——剪枝,但是這裡不這樣幹,由於之前的兩個隨機取樣的過程保證了隨機性,所以就算不剪枝,也不會出現over-fitting。
決策樹劃分原則:
1、資訊增益
2、增益率
3、基尼係數
具體的實現過程可參見“機器學習—決策樹”
(3)實現過程
具體實現過程如下:
(1)原始訓練集為N,應用bootstrap法有放回地隨機抽取k個新的自助樣本集,並由此構建k棵分類樹,每次未被抽到的樣本組成了k個袋外資料;
(2)設資料集共有
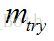

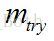
(3)每棵樹最大限度地生長, 不做任何修剪;
(4)將生成的多棵分類樹組成隨機森林,用隨機森林分類器對新的資料進行判別與分類,分類結果按樹分類器的投票多少而定。
(4)優缺點
優點:
1.正如上文所述,隨機森林演算法能解決分類與迴歸兩種型別的問題,並在這兩個方面都有相當好的估計表現;
2.隨機森林對於高維資料集的處理能力令人興奮,它可以處理成千上萬的輸入變數,並確定最重要的變數,因此被認為是一個不錯的降維方法。此外,該模型能夠輸出變數的重要性程度,這是一個非常便利的功能。下圖展示了隨機森林對於變數重要性程度的輸出形式:
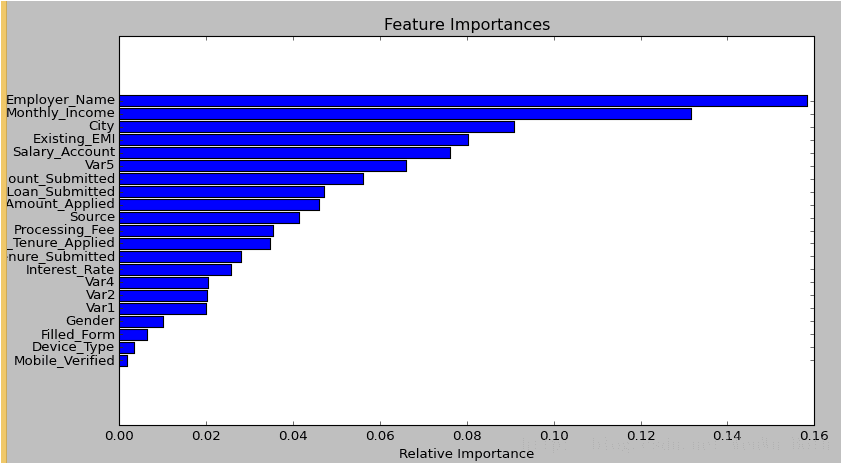
3.在對缺失資料進行估計時,隨機森林是一個十分有效的方法。就算存在大量的資料缺失,隨機森林也能較好地保持精確性;
4.當存在分類不平衡的情況時,隨機森林能夠提供平衡資料集誤差的有效方法;
5.模型的上述效能可以被擴充套件運用到未標記的資料集中,用於引導無監督聚類、資料透視和異常檢測;
6.隨機森林演算法中包含了對輸入資料的重複自抽樣過程,即所謂的bootstrap抽樣。這樣一來,資料集中大約三分之一將沒有用於模型的訓練而是用於測試,這樣的資料被稱為out of bag samples,通過這些樣本估計的誤差被稱為out of bag error。研究表明,這種out of bag方法的與測試集規模同訓練集一致的估計方法有著相同的精確程度,因此在隨機森林中我們無需再對測試集進行另外的設定。
缺點:
1.隨機森林在解決迴歸問題時並沒有像它在分類中表現的那麼好,這是因為它並不能給出一個連續型的輸出。當進行迴歸時,隨機森林不能夠作出超越訓練集資料範圍的預測,這可能導致在對某些還有特定噪聲的資料進行建模時出現過度擬合。
2.對於許多統計建模者來說,隨機森林給人的感覺像是一個黑盒子——你幾乎無法控制模型內部的執行,只能在不同的引數和隨機種子之間進行嘗試。
(5)Python實現
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_split=1e-07, bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False, class_weight=None)Python提供了一個機器學習演算法的包:scikit-learn,隨機森林演算法的呼叫引數官方文件講的非常詳細,我就不班門弄斧了,網址:sklearn.ensemble.RandomForestClassifier