《web安全之機器學習入門》第6章決策樹與隨機森林演算法
阿新 • • 發佈:2018-12-25
決策樹識別pop3埠掃描(原書中識別暴力破解,實際上pop3協議的並沒有guess_passwd型別的資料,所以改為識別port_sweep.):
待分析資料集:
KDD-99資料集,連結:http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html
該資料集是從一個模擬的美國空軍區域網上採集來的9個星期的網路連線資料,分成具有標識的訓練資料和未加標識的測試資料。
資料集已經進行了資料採集、清洗、提取特徵、打標籤等動作。每一行包括41個特徵和1個標籤,總共42列。
一個網路連線定義為在某個時間內從開始到結束的TCP資料包序列,並且在這段時間內,資料在預定義的協議下(如TCP、UDP)從源IP地址到目的IP地址的傳遞。每個網路連線被標記為正常(normal)或異常(attack),異常型別被細分為4大類共39種攻擊型別,其中22種攻擊型別出現在訓練集中,另有17種未知攻擊型別出現在測試集中。
從資料集中過濾出協議為pop3的(第2列),以及標籤為normal.負類、port_sweep.正類的資料(第41列)
選取的特徵:
列0:duration:連續型別:連線持續時間
列4:src_bytes:連續型別:從源主機到目標主機的位元組數
列5:dst_bytes:連續型別:從目標主機到源主機的位元組數
列6:land:離散型別:若連線來自/送達同一個主機/埠,則為1,否則為0[1 if connection from/to the same host/port;0 otheriwise]
列7:wrong_fragment:連續型別:錯誤分段數量
列22:count:連續型別:過去2s內,與當前連線具有相同目標ip的連線數目
列23:srv_count:連續型別:過去2s內,與當前連線具有相同服務的連線數目
列24:serror_rate:連續型別:過去2s內,與當前連線具有相同目標IP的連線中,出現"SYN"錯誤的連線的百分比
列25:srv_serror_rate:連續型別:過去2s內,與當前連線具有相同服務的連線中,出現"SYN"錯誤的連線的百分比
列26:rerror_rate:連續型別:過去2s內,與當前連線具有相同目標IP的連線中,出現"REJ"錯誤的連線的百分比
列27:srv_rerror_rate:連續型別:過去2s內,與當前連線具有相同服務的連線中,出現"REJ"錯誤的連線的百分比
列28:same_srv_rate:連續型別:在過去2s內,與當前連線具有相同目標主機的連線中,與當前連線具有相同服務的連線的百分比
待分析資料集:
KDD-99資料集,連結:http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html
該資料集是從一個模擬的美國空軍區域網上採集來的9個星期的網路連線資料,分成具有標識的訓練資料和未加標識的測試資料。
資料集已經進行了資料採集、清洗、提取特徵、打標籤等動作。每一行包括41個特徵和1個標籤,總共42列。
一個網路連線定義為在某個時間內從開始到結束的TCP資料包序列,並且在這段時間內,資料在預定義的協議下(如TCP、UDP)從源IP地址到目的IP地址的傳遞。每個網路連線被標記為正常(normal)或異常(attack),異常型別被細分為4大類共39種攻擊型別,其中22種攻擊型別出現在訓練集中,另有17種未知攻擊型別出現在測試集中。
從資料集中過濾出協議為pop3的(第2列),以及標籤為normal.負類、port_sweep.正類的資料(第41列)
選取的特徵:
列0:duration:連續型別:連線持續時間
列4:src_bytes:連續型別:從源主機到目標主機的位元組數
列5:dst_bytes:連續型別:從目標主機到源主機的位元組數
列6:land:離散型別:若連線來自/送達同一個主機/埠,則為1,否則為0[1 if connection from/to the same host/port;0 otheriwise]
列7:wrong_fragment:連續型別:錯誤分段數量
列22:count:連續型別:過去2s內,與當前連線具有相同目標ip的連線數目
列23:srv_count:連續型別:過去2s內,與當前連線具有相同服務的連線數目
列24:serror_rate:連續型別:過去2s內,與當前連線具有相同目標IP的連線中,出現"SYN"錯誤的連線的百分比
列25:srv_serror_rate:連續型別:過去2s內,與當前連線具有相同服務的連線中,出現"SYN"錯誤的連線的百分比
列26:rerror_rate:連續型別:過去2s內,與當前連線具有相同目標IP的連線中,出現"REJ"錯誤的連線的百分比
列27:srv_rerror_rate:連續型別:過去2s內,與當前連線具有相同服務的連線中,出現"REJ"錯誤的連線的百分比
列28:same_srv_rate:連續型別:在過去2s內,與當前連線具有相同目標主機的連線中,與當前連線具有相同服務的連線的百分比
列29:diff_srv_rate:連續型別:在過去2s內,與當前連線具有相同目標主機的連線中,與當前連線具有不同服務的連線的百分比
決策樹演算法的程式碼如下:
#coding:utf-8 import os import numpy as np from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import cross_val_score DATAPATH = os.path.dirname(os.path.abspath(__file__)) + "/data" def parse_data(): FULLPATH = DATAPATH + "/kddcup.data.corrected" test_data = list() label_data = list() with open(FULLPATH, "r") as f: for line in f.readlines(): lines = line.strip().split(",") label = 0 if lines[2] == 'pop_3' and (lines[-1] == 'normal.' or lines[-1] == 'portsweep.'): if lines[-1] == 'portsweep.': label = 1 test_data.append([lines[0]] + lines[4:8] + lines[22:30]) label_data.append(label) return [test_data,label_data] if __name__ == '__main__': test_data, label_data = parse_data() tree = DecisionTreeClassifier() score = cross_val_score(tree, test_data, label_data, cv=10) print score print "precision:",np.mean(score)*100
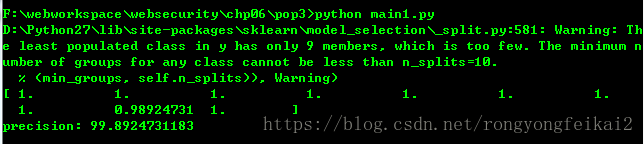
程式碼執行效果如下:

隨機森林的程式碼如下:
#coding:utf-8 import os import numpy as np from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import cross_val_score DATAPATH = os.path.dirname(os.path.abspath(__file__)) + "/data" def parse_data(): FULLPATH = DATAPATH + "/kddcup.data.corrected" test_data = list() label_data = list() with open(FULLPATH, "r") as f: for line in f.readlines(): lines = line.strip().split(",") label = 0 if lines[2] == 'pop_3' and (lines[-1] == 'normal.' or lines[-1] == 'portsweep.'): if lines[-1] == 'portsweep.': label = 1 test_data.append([lines[0]] + lines[4:8] + lines[22:30]) label_data.append(label) return [test_data,label_data] if __name__ == '__main__': test_data, label_data = parse_data() forest = RandomForestClassifier(n_estimators = 10) score = cross_val_score(forest, test_data, label_data, cv=10) print score print "precision:",np.mean(score)*100
程式碼執行效果如下: