
【論文閱讀】:Embedding-based News Recommendation for Millions of Users
非常實用性的一個推薦新聞的模型
摘要:
新聞推薦非常重要,但是傳統的基於使用者id的協同過濾和低秩分解推薦演算法不完全適用於新聞推薦,因為新聞類文章過期的太快了
基於單詞的方法效能不錯,但是有處理同義詞和定義使用者需求的問題
因此本文提出一種基於嵌入式的演算法,基於一種去噪自編碼器的變體的方法來表示文章;用RNN以瀏覽歷史為輸入序列表示使用者;用內積計算來匹配使用者和文章
1 introduction
新聞推薦的三個關鍵點:
- 理解文章內容
- 理解使用者喜好
- 基於兩者選出每個使用者的文章列表
符合這三點的baseline模型是將文章表示成單詞的word的集合,使用者的表示是該使用者瀏覽過的文章包含的word的集合,用候選文章和瀏覽歷史比較共同出現的word來判斷點選的概率,這個模型簡單,容易學習;但是缺點是不能很好的判斷近義詞,也不能很好的更充分的利用使用者的瀏覽歷史
rnn擅長處理輸入序列長度變化的情況,但是隻用這個模型,不能符合要求的響應速度
所以本文提出的模型分為三步,端到端,分散式:
- - 基於去噪自編碼器的分散式表示方法表示出文章
- - 以瀏覽歷史為RNN的輸入 生成使用者表示
- - 用內積的方式匹配出使用者和文章
該方法的核心就是用內積計算來衡量使用者-文章的匹配度,非常快速。現在這種方法已經應用在雅虎日本的新聞推薦了
2、our service and process flow
本文針對的是雅虎日本app中使用者定製模組的部分
使用者登入時為使用者選擇匹配列表的過程如下:
- -登入時識別出更具瀏覽歷史提前計算出的使用者特徵
- - 匹配:根據使用者特徵計算出所有可用的文章
- - 排序:根據一些特徵優先順序重新排序
- - 去重
- - 插入廣告(如果需要的話)
這些過程非常的快
排序時除了考慮相關度,還會考慮文章的頁碼數以及新鮮程度等
用cos距離來計算文字的相似度,貪心的跳過重複的文章。如果一篇文章和優先順序更高的文章的相似度超過一定值,就捨棄
3、artical representations
得到文章的表示方式


為了讓輸入的兩篇文章x1,x2相近時得到的h1,h2內積之和大,對原本的去噪自編碼器進行了修改,輸入變為(x0,x1,x2)三元輸入組,x0 x1是同類(相似)的文章,x2是不同的,在loss函式中新增懲罰來達到訓練效果
得到的h就是後面要用來計算的
4、 user representation
通過使用者的瀏覽歷史來計算使用者特徵,包括的簡單的word-based baseline模型,以及普通rnn形式、lstm形式和gru形式
其中a表示文章集合A中的一篇文章(用一種形式表示出來的),u表示一位使用者,某個使用者瀏覽的一系列文章就構成了使用者u的瀏覽歷史,使用者通過推薦李彪點開文章才構成session,用s表示,下標p表示該文章在推薦列表中的位置
關鍵的目標是:

找到表示使用者和文章相關性的函式R和通過瀏覽歷史構建使用者狀態的函式F,滿足上圖的性質,其中P+表示推薦列表中使用者點選過的文章,P-則是沒有點選的
考慮到響應時間的限制,R必須是可以快速計算的,由於文章多而且時效端,也沒法提前計算好;但是對於F卻有比較充足的時間可以計算
因此,R就用內積計算來進行,![]()
只需要優化表示使用者狀態的函式F:

由於實際中點選的概率跟文章在session中的位置有關係,所以加了一個bias
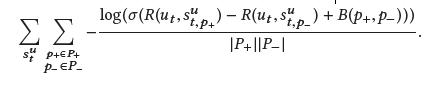
word-based模型
BoW詞袋 建立一個大的詞表V

相關性就是交集的單詞有多少,有就+1
問題是非常稀疏,也不能處理同義詞;由於瀏覽記錄被認為是一個單詞的集合,所以瀏覽的先後順序和頻率就丟失了
decaying model
使用第三部分所得的h來表示文章
用加權和來表示整個的瀏覽歷史,這樣根據係數可以調整瀏覽歷史的權重
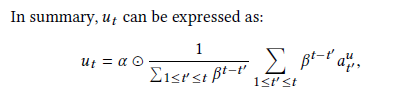
RNN model
簡單RNN
畢竟decaying model是線性的,很多資訊拿不到;而且ut是和上一個的狀態ut-1有關係的,因此使用rnn模型
![]()
這裡的啟用函式用tanh,用隨機梯度下降來優化
LSTM

GRU
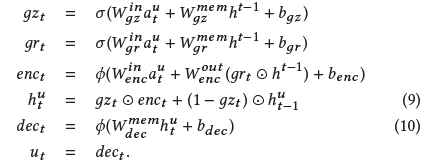
5、 offline experiments
雅虎日本主頁的資料,每個使用者隨機選擇了超過兩週的資料


結果:

6 deployment
向上部署以GRU的模型作為proposd bucket,以Bow模型為control bucket作對比(1%)
提前計算使用者特徵ut,當用戶訪問該服務時,用內積計算出一段時間內新出的新聞和使用者的相關度
去重後按照從高到低相關性排序
線上的度量包括:sessions(使用者每天使用推薦服務的平均時間) duration(看推薦列表以及點進去後的時間) clicks(在推薦列表中點進去的次數) CTR(點選數除以推薦列表中的展示出的文章數)
將使用者分為重度、中度和輕度使用者
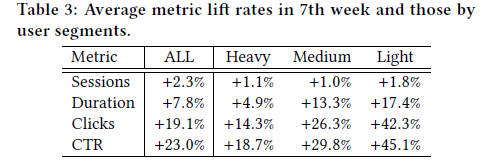
結果很好
部署大規模基於深度學習的模型時會遇到一些挑戰:
學習時間長;更新困難
因此是用兩個模型輪流來,以便進行更新
7 related work
8 conclusion