
深度學習---煉丹trick之Normalization(BN/LN/WN/CN)
參考文獻:詳解深度學習中的Normalization,BN/LN/WN
https://zhuanlan.zhihu.com/p/33173246

3主流 Normalization 方法梳理
在上一節中,我們提煉了 Normalization 的通用公式:
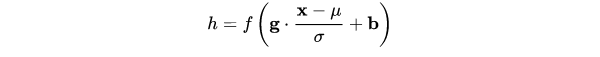
對照於這一公式,我們來梳理主流的四種規範化方法。
3.1 Batch Normalization —— 縱向規範化


3.2 Layer Normalization —— 橫向規範化


3.3 Weight Normalization —— 引數規範化


3.4 Cosine Normalization —— 餘弦規範化


相關推薦
深度學習---煉丹trick之Normalization(BN/LN/WN/CN)
參考文獻:詳解深度學習中的Normalization,BN/LN/WN https://zhuanlan.zhihu.com/p/33173246 3主流 Normalization 方法梳理 在上一節中,我們提煉了 Normalization 的通用公式: 對照於這一公
深度學習---煉丹trick之正確使用BN(訓練和測試/預測時怎麼用)
一、為什麼需要batch normalization 儘管梯度下降法訓練神經網路很簡單高效,但是需要人為地去選擇引數,比如學習率,引數初始化,權重衰減係數,Dropout比例等,而且這些引數的選擇對於訓練結果至關重要,以至於我們很多時間都浪費到這些調參上。BN演算法的強大之處在下面幾個方
深度學習 --- 模擬退火演算法詳解(Simulated Annealing, SA)
上一節我們深入探討了,Hopfield神經網路的性質,介紹了吸引子和其他的一些性質,而且引出了偽吸引子,因為偽吸引子的存在導致Hopfield神經網路正確率下降,因此本節致力於解決偽吸引子的存在。在講解方法之前我們需要再次理解一些什麼是偽吸引子,他到底是如何產生的? 簡單來說說就是網路動態轉
深度學習RNN實現股票預測實戰(附資料、程式碼)
背景知識最近再看一些量化交易相關的材料,偶然在網上看到了一個關於用RNN實現股票預測的文章,出於好奇心把文章中介紹的程式碼在本地跑了一遍,發現可以work。於是就花了兩個晚上的時間學習了下程式碼,順便把
深度學習的 “ 端到端模型(end-to-end learning)”
相對於深度學習,傳統機器學習的流程往往由多個獨立的模組組成,比如在一個典型的自然語言處理(Natural Language Processing)問題中,包括分詞、詞性標註、句法分析、語義分析等多個獨立步驟,每個步驟是一個獨立的任務,其結果的好壞會影響到下一步驟
【深度學習】批歸一化(Batch Normalization)
學習 src 試用 其中 put min 平移 深度 優化方法 BN是由Google於2015年提出,這是一個深度神經網絡訓練的技巧,它不僅可以加快了模型的收斂速度,而且更重要的是在一定程度緩解了深層網絡中“梯度彌散”的問題,從而使得訓練深層網絡模型更加容易和穩定。所以目前
小宋深度學習之旅(小白入門教程)0
這是針對和我一樣非計算機專業小白開發人員,基於TensorFlow框架,Python語言,主要使用Windows平臺開發的深度學習,小白入門教程。 先put出一個示例程式碼 Hello World 程式碼: # encode : utf-8 import tens
【火爐煉AI】深度學習010-Keras微調提升效能(多分類問題)
【火爐煉AI】深度學習010-Keras微調提升效能(多分類問題) (本文所使用的Python庫和版本號: Python 3.6, Numpy 1.14, scikit-learn 0.19, matplotlib 2.2, Keras 2.1.6, Tensorflow 1.9.0) 前面的文章(【火爐
分享《深度學習之Pytorch(廖星宇著)》+《PyTorch深度學習實戰(侯宜軍 著)》+源代碼
https col ges tps jpg 51cto 技術分享 分享圖片 pan 下載:https://pan.baidu.com/s/1ewm1x3UeMe283PQVbDVIoA 更多資料分享:http://blog.51cto.com/3215120 《深度學習之P
深度學習 --- 優化入門五(Batch Normalization(批量歸一化)二)
批歸一化真的可以解決內部協方差偏移問題?如果不能解決,那它的作用是什麼?你所接受的整個深度學習教育是一個謊言嗎?讓我們來尋找答案吧! 開始之前...... 我想提醒一下,本文是深度學習優化算法系列的第四篇,前三篇文章討論了: 隨機梯度下降如何克服深度學習中的區域性極小值和鞍點
深度學習 --- 優化入門四(Batch Normalization(批量歸一化)一)
前幾節我們詳細的探討了,梯度下降存在的問題和優化方法,本節將介紹在資料處理方面很重要的優化手段即批量歸一化(批量歸一化)。 批量歸一化(Batch Normalization)並不能算作是一種最優化演算法,但其卻是近年來優化深度神經網路最有用的技巧之一,並且這種方法非常的簡潔方便,可以和其他
基於深度學習的目標檢測演算法綜述(二)—Two/One stage演算法改進之R-FCN
基於深度學習的目標檢測演算法綜述(一):https://blog.csdn.net/weixin_36835368/article/details/82687919 目錄 1、Two stage 1.1 R-FCN:Object Detection via Region-based
深度學習UFLDL教程翻譯之卷積神經網路(一)
A、使用卷積進行特徵提取 一、概述 在前面的練習中,你解決了畫素相對較低的影象的相關問題,例如小的圖片塊和手寫數字的小影象。在這個節,我們將研究能讓我們將這些方法拓展到擁有較大影象的更加
學習hibernate出現錯誤--之二(方言)
pda data cells bird nbsp 版本問題 inno 提高 語言 最近在學習hibernate,其中關於錯誤的問題真是一頭大,各種各樣的奇葩錯誤層出不窮,簡直是受不了了。 用hibernate操作數據庫,在使用hibernate進行把持久
python學習_day54_前端基礎之js(2)
data 截取 定義 得到 let 結果 是什麽 index 插入 在JavaScript中除了null和undefined以外其他的數據類型都被定義成了對象,也可以用創建對象的方法定義變量,String、Math、Array、Date、RegExp都是JavaScri
深度學習的異構加速技術(二):螺獅殼裏做道場
篩選 分享 intel 支持 get 更多 wid efficient 優勢 作者簡介:kevinxiaoyu,高級研究員,隸屬騰訊TEG-架構平臺部,主要研究方向為深度學習異構計算與硬件加速、FPGA雲、高速視覺感知等方向的構架設計和優化。“深度學習的異構加速技術”系列
深度學習Keras框架筆記之TimeDistributedDense類
nts ini OS sample con stream 輸出 without 實例 深度學習Keras框架筆記之TimeDistributedDense類使用方法筆記 例: keras.layers.core.TimeDistribut
深度學習Keras框架筆記之AutoEncoder類
seq boolean red any ati RR blog data val 深度學習Keras框架筆記之AutoEncoder類使用筆記 keras.layers.core.AutoEncoder(encoder, decoder,output_recon
深度學習Keras框架筆記之Activation類使用
UNC 一個 HA brush theano predict bool sha red 使用 keras.layers.core.Activation(activation) Apply an activation function tothe in
機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之九(第5章 總結)
ces mark TP 生成 機器 分享 png ffffff images ? ?機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之九(第5章 總結)