
基於情感詞典的情感打分
阿新 • • 發佈:2019-01-07
原理我就不講了,請移步下面這篇論文,包括情感詞典的構建(各位讀者可以根據自己的需求稍作簡化),以及打分策略(程式對原論文稍有改動)。
本文采用的方法如下:
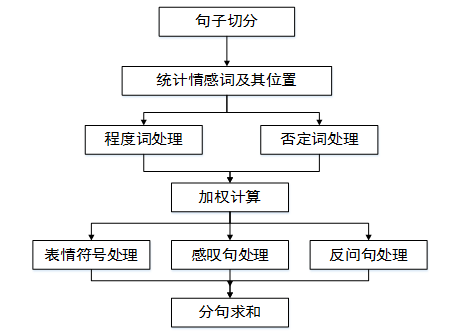
首先對單條微博進行文字預處理,並以標點符號為分割標誌,將單條微博分割為n個句子,提取每個句子中的情感詞 。以下兩步的處理均以分句為處理單位。
第二步在情感詞表中尋找情感詞,以每個情感詞為基準,向前依次尋找程度副詞、否定詞,並作相應分值計算。隨後對分句中每個情感詞的得分作求和運算。
第三步判斷該句是否為感嘆句,是否為反問句,以及是否存在表情符號。如果是,則分句在原有分值的基礎上加上或減去對應的權值。
最後對該條微博的所有分句的分值進行累加,獲得該條微博的最終得分。
程式碼如下:
首先檔案結構圖如下:
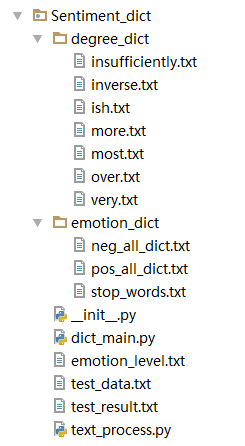
其中,degree_dict為程度詞典,其中每個檔案為不同的權值。
emotion_dict為情感詞典,包括了積極情感詞和消極情感詞以及停用詞。
檔案一:文字預處理 textprocess.py
在裡面封裝了一些文字預處理的函式,方便呼叫。
# -*- coding: utf-8 -*-
__author__ = 'Bai Chenjia'
import jieba
import jieba.posseg as pseg
print "載入使用者詞典..."
import sys
reload(sys)
sys.setdefaultencoding("utf-8" 檔案二:情感打分 dict_main.py
其中待處理資料放在chinese_weibo.txt中,讀者可以自行更改檔案目錄,該檔案中的資料格式如下圖:

即用每一行代表一條語句,我們對每條語句進行情感分析,進行打分
# -*- coding: utf-8 -*-
__author__ = 'Bai Chenjia'
import text_process as tp
import numpy as np
# 1.讀取情感詞典和待處理檔案
# 情感詞典
print "reading..."
posdict = tp.read_lines("f://emotion/mysite/Sentiment_dict/emotion_dict/pos_all_dict.txt")
negdict = tp.read_lines("f://emotion/mysite/Sentiment_dict/emotion_dict/neg_all_dict.txt")
# 程度副詞詞典
mostdict = tp.read_lines('f://emotion/mysite/Sentiment_dict/degree_dict/most.txt') # 權值為2
verydict = tp.read_lines('f://emotion/mysite/Sentiment_dict/degree_dict/very.txt') # 權值為1.5
moredict = tp.read_lines('f://emotion/mysite/Sentiment_dict/degree_dict/more.txt') # 權值為1.25
ishdict = tp.read_lines('f://emotion/mysite/Sentiment_dict/degree_dict/ish.txt') # 權值為0.5
insufficientdict = tp.read_lines('f://emotion/mysite/Sentiment_dict/degree_dict/insufficiently.txt') # 權值為0.25
inversedict = tp.read_lines('f://emotion/mysite/Sentiment_dict/degree_dict/inverse.txt') # 權值為-1
# 情感級別
emotion_level1 = "悲傷。在這個級別的人過的是八輩子都懊喪和消沉的生活。這種生活充滿了對過去的懊悔、自責和悲慟。在悲傷中的人,看這個世界都是灰黑色的。"
emotion_level2 = "憤怒。如果有人能跳出冷漠和內疚的怪圈,並擺脫恐懼的控制,他就開始有慾望了,而慾望則帶來挫折感,接著引發憤怒。憤怒常常表現為怨恨和復仇心裡,它是易變且危險的。憤怒來自未能滿足的慾望,來自比之更低的能量級。挫敗感來自於放大了慾望的重要性。憤怒很容易就導致憎恨,這會逐漸侵蝕一個人的心靈。"
emotion_level3 = "淡定。到達這個能級的能量都變得很活躍了。淡定的能級則是靈活和無分別性的看待現實中的問題。到來這個能級,意味著對結果的超然,一個人不會再經驗挫敗和恐懼。這是一個有安全感的能級。到來這個能級的人們,都是很容易與之相處的,而且讓人感到溫馨可靠,這樣的人總是鎮定從容。他們不會去強迫別人做什麼。"
emotion_level4 = "平和。他感覺到所有的一切都生機勃勃並光芒四射,雖然在其他人眼裡這個世界還是老樣子,但是在這人眼裡世界卻是一個。所以頭腦保持長久的沉默,不再分析判斷。觀察者和被觀察者成為同一個人,觀照者消融在觀照中,成為觀照本身。"
emotion_level5 = "喜悅。當愛變得越來越無限的時候,它開始發展成為內在的喜悅。這是在每一個當下,從內在而非外在升起的喜悅。這個能級的人的特點是,他們具有巨大的耐性,以及對一再顯現的困境具有持久的樂觀態度,以及慈悲。同時發生著。在他們開來是稀鬆平常的作為,卻會被平常人當成是奇蹟來看待。"
# 情感波動級別
emotion_level6 = "情感波動很小,個人情感是不易改變的、經得起考驗的。能夠理性的看待周圍的人和事。"
emotion_level7 = "情感波動較大,周圍的喜悅或者悲傷都能輕易的感染他,他對周圍的事物有敏感的認知。"
# 2.程度副詞處理,根據程度副詞的種類不同乘以不同的權值
def match(word, sentiment_value):
if word in mostdict:
sentiment_value *= 2.0
elif word in verydict:
sentiment_value *= 1.75
elif word in moredict:
sentiment_value *= 1.5
elif word in ishdict:
sentiment_value *= 1.2
elif word in insufficientdict:
sentiment_value *= 0.5
elif word in inversedict:
#print "inversedict", word
sentiment_value *= -1
return sentiment_value
# 3.情感得分的最後處理,防止出現負數
# Example: [5, -2] → [7, 0]; [-4, 8] → [0, 12]
def transform_to_positive_num(poscount, negcount):
pos_count = 0
neg_count = 0
if poscount < 0 and negcount >= 0:
neg_count += negcount - poscount
pos_count = 0
elif negcount < 0 and poscount >= 0:
pos_count = poscount - negcount
neg_count = 0
elif poscount < 0 and negcount < 0:
neg_count = -poscount
pos_count = -negcount
else:
pos_count = poscount
neg_count = negcount
return (pos_count, neg_count)
# 求單條微博語句的情感傾向總得分
def single_review_sentiment_score(weibo_sent):
single_review_senti_score = []
cuted_review = tp.cut_sentence(weibo_sent) # 句子切分,單獨對每個句子進行分析
for sent in cuted_review:
seg_sent = tp.segmentation(sent) # 分詞
seg_sent = tp.del_stopwords(seg_sent)[:]
#for w in seg_sent:
# print w,
i = 0 # 記錄掃描到的詞的位置
s = 0 # 記錄情感詞的位置
poscount = 0 # 記錄該分句中的積極情感得分
negcount = 0 # 記錄該分句中的消極情感得分
for word in seg_sent: # 逐詞分析
#print word
if word in posdict: # 如果是積極情感詞
#print "posword:", word
poscount += 1 # 積極得分+1
for w in seg_sent[s:i]:
poscount = match(w, poscount)
#print "poscount:", poscount
s = i + 1 # 記錄情感詞的位置變化
elif word in negdict: # 如果是消極情感詞
#print "negword:", word
negcount += 1
for w in seg_sent[s:i]:
negcount = match(w, negcount)
#print "negcount:", negcount
s = i + 1
# 如果是感嘆號,表示已經到本句句尾
elif word == "!".decode("utf-8") or word == "!".decode('utf-8'):
for w2 in seg_sent[::-1]: # 倒序掃描感嘆號前的情感詞,發現後權值+2,然後退出迴圈
if w2 in posdict:
poscount += 2
break
elif w2 in negdict:
negcount += 2
break
i += 1
#print "poscount,negcount", poscount, negcount
single_review_senti_score.append(transform_to_positive_num(poscount, negcount)) # 對得分做最後處理
pos_result, neg_result = 0, 0 # 分別記錄積極情感總得分和消極情感總得分
for res1, res2 in single_review_senti_score: # 每個分句迴圈累加
pos_result += res1
neg_result += res2
#print pos_result, neg_result
result = pos_result - neg_result # 該條微博情感的最終得分
result = round(result, 1)
return result
"""
# 測試
weibo_sent = "這手機的畫面挺好,操作也比較流暢。不過拍照真的太爛了!系統也不好。"
score = single_review_sentiment_score(weibo_sent)
print score
"""
# 分析test_data.txt 中的所有微博,返回一個列表,列表中元素為(分值,微博)元組
def run_score():
fp_test = open('f://emotion/mysite/Weibo_crawler/chinese_weibo.txt', 'r') # 待處理資料
contents = []
for content in fp_test.readlines():
content = content.strip()
content = content.decode("utf-8")
contents.append(content)
fp_test.close()
results = []
for content in contents:
score = single_review_sentiment_score(content) # 對每條微博呼叫函式求得打分
results.append((score, content)) # 形成(分數,微博)元組
return results
# 將(分值,句子)元組按行寫入結果檔案test_result.txt中
def write_results(results):
fp_result = open('test_result.txt', 'w')
for result in results:
fp_result.write(str(result[0]))
fp_result.write(' ')
fp_result.write(result[1])
fp_result.write('\n')
fp_result.close()
# 求取測試檔案中的正負極性的微博比,正負極性分值的平均值比,正負分數分別的方差
def handel_result(results):
# 正極性微博數量,負極性微博數量,中性微博數量,正負極性比值
pos_number, neg_number, mid_number, number_ratio = 0, 0, 0, 0
# 正極性平均得分,負極性平均得分, 比值
pos_mean, neg_mean, mean_ratio = 0, 0, 0
# 正極性得分方差,負極性得分方差
pos_variance, neg_variance, var_ratio = 0, 0, 0
pos_list, neg_list, middle_list, total_list = [], [], [], []
for result in results:
total_list.append(result[0])
if result[0] > 0:
pos_list.append(result[0]) # 正極性分值列表
elif result[0] < 0:
neg_list.append(result[0]) # 負極性分值列表
else:
middle_list.append(result[0])
#################################各種極性微博數量統計
pos_number = len(pos_list)
neg_number = len(neg_list)
mid_number = len(middle_list)
total_number = pos_number + neg_number + mid_number
number_ratio = pos_number/neg_number
pos_number_ratio = round(float(pos_number)/float(total_number), 2)
neg_number_ratio = round(float(neg_number)/float(total_number), 2)
mid_number_ratio = round(float(mid_number)/float(total_number), 2)
text_pos_number = "積極微博條數為 " + str(pos_number) + " 條,佔全部微博比例的 %" + str(pos_number_ratio*100)
text_neg_number = "消極微博條數為 " + str(neg_number) + " 條,佔全部微博比例的 %" + str(neg_number_ratio*100)
text_mid_number = "中性情感微博條數為 " + str(mid_number) + " 條,佔全部微博比例的 %" + str(mid_number_ratio*100)
##################################正負極性平均得分統計
pos_array = np.array(pos_list)
neg_array = np.array(neg_list) # 使用numpy匯入,便於計算
total_array = np.array(total_list)
pos_mean = pos_array.mean()
neg_mean = neg_array.mean()
total_mean = total_array.mean() # 求單個列表的平均值
mean_ratio = pos_mean/neg_mean
if pos_mean <= 6: # 賦予不同的情感等級
text_pos_mean = emotion_level4
else:
text_pos_mean = emotion_level5
if neg_mean >= -6:
text_neg_mean = emotion_level2
else:
text_neg_mean = emotion_level1
if total_mean <= 6 and total_mean >= -6:
text_total_mean = emotion_level3
elif total_mean > 6:
text_total_mean = emotion_level4
else:
text_total_mean = emotion_level2
##################################正負進行方差計算
pos_variance = pos_array.var(axis=0)
neg_variance = neg_array.var(axis=0)
total_variance = total_array.var(axis=0)
var_ratio = pos_variance/neg_variance
#print "pos_variance:", pos_variance, "neg_variance:", neg_variance, "var_ration:", var_ratio
if total_variance > 10: # 賦予不同的情感波動級別
text_total_var = emotion_level7
else:
text_total_var = emotion_level6
################################構成字典返回
result_dict = {}
result_dict['pos_number'] = pos_number # 正向微博數
result_dict['neg_number'] = neg_number # 負向微博數
result_dict['mid_number'] = mid_number # 中性微博數
result_dict['number_ratio'] = round(number_ratio, 1) # 正負微博數之比,保留一位小數四捨五入
result_dict['pos_mean'] = round(pos_mean, 1) # 積極情感平均分
result_dict['neg_mean'] = round(neg_mean, 1) # 消極情感平均分
result_dict['total_mean'] = round(total_mean, 1) # 總的情感平均得分
result_dict['mean_ratio'] = abs(round(mean_ratio, 1)) # 積極情感平均分/消極情感平均分
result_dict['pos_variance'] = round(pos_variance, 1) # 積極得分方差
result_dict['neg_variance'] = round(neg_variance, 1) # 消極得分方差
result_dict['total_variance'] = round(total_variance, 1) # 總的情感得分方差
result_dict['var_ratio'] = round(var_ratio, 1) # 積極得分方差/消極得分方差
result_dict['text_pos_number'] = text_pos_number # 各種情感評價
result_dict['text_neg_number'] = text_neg_number
result_dict['text_mid_number'] = text_mid_number
result_dict['text_pos_mean'] = text_pos_mean
result_dict['text_neg_mean'] = text_neg_mean
result_dict['text_total_mean'] = text_total_mean
result_dict['text_total_var'] = text_total_var
"""
for key in result_dict.keys():
print 'key = %s , value = %s ' % (key, result_dict[key])
"""
return result_dict
if __name__ == '__main__':
results = run_score() # 計算每句話的極性得分,返回list,元素是(得分,微博)
write_results(results) # 將每條微博的極性得分都寫入檔案
result_dict = handel_result(results) # 計算結果的各種引數,返回字典
打分結果如圖,即前面是情感得分,後面是語句:
