
談談VR遊戲的效能優化
阿新 • • 發佈:2019-01-07
VR遊戲相對傳統遊戲,個人認為主要有三個方面的不同:玩法設計,輸入方式,效能壓力。今天就來談一下VR遊戲中的效能優化。
為什麼VR遊戲的效能壓力很大?
- 主要有三個因素的影響:高幀率,高解析度,畫兩遍,影響權重由高到低。
- 高幀率:DK2為75,最新的CV1是90;HTC Vive為90;PS4 VR為120。對比PC遊戲的60以及主機遊戲的30,壓力可想而知!
- 需要說明的是鑑於幀率這麼高,每一幀即便2ms的提升意義也巨大。即便以75為例,每幀時間為13.33ms,2ms佔比15%!
- 高解析度:DK2為1920 * 1080,最新的CV1為2160 * 1200;HTC Vive為2160 * 1200;PS4 VR為1920 * 1080
- 除了賬面解析度之外,實際渲染時為抵消透鏡畸變帶來的解析度損失需要超取樣,具體:DK2為135%,CV1和HTC Vive都為140%
- 除了賬面解析度之外,實際渲染時為抵消透鏡畸變帶來的解析度損失需要超取樣,具體:DK2為135%,CV1和HTC Vive都為140%
- 即使以DK2的資料:1920 * 1080 @75Hz來說,每秒的畫素處理量為283 millions, 這個資料4倍於一般的主機遊戲!更別忘了,最新硬體的這個資料提升至457 millions
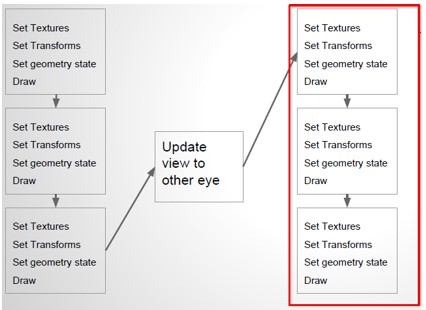
- 畫兩遍
- 方法一:依次畫兩遍場景
, SetTexture,SetTransforms,SetViewport,切換RenderState,DrawCall等均翻倍 - 方法二:依次畫兩遍物體
,相比較方法一有節省,但DrawCall依舊翻倍
- 方法一:依次畫兩遍場景

關於畫素處理部分
通過上面的資料可以看到其實VR遊戲效能壓力主要集中在畫素處理方面,那麼如下和畫素處理相關的部分就要特別注意:
- 光影計算方案的選擇:空間換時間尤為重要,light map、靜態AO,環境反射貼圖等能上就上,dynamic shadow在任何時候能省則省。
- 後期處理:不用的效果統統幹掉。如DOF、Motion Blur、Lens Flare等本就不適合VR遊戲;SSR、SSAO等儘量用前面說的靜態方案來替代;
AA也可以不用,因為已經有Super Sampling了 - 特別注意OverDraw的問題:典型的如範圍巨大的透明面片特效省著點用,不要動不動疊加個7、8層。
- Shader複雜度問題:UE4的viewmode裡面有一個是專門檢視shader複雜度的。一般來說,出現粉色和白色的情況說明shader太複雜了,需要修正。
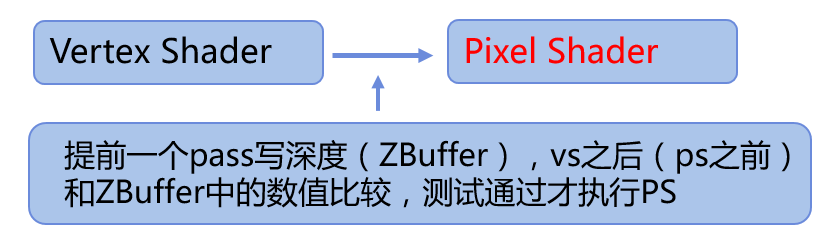
- early z culling:
- 原理:
- 延遲渲染已經成為各大引擎的標配,很多人覺得對於延遲渲染來講,early z culling沒有存在的必要,畢竟生成GBuffer之後相當於已經做了畫素級別的culling,而且多了一個pass提前寫深度往往得不償失;但early z culling針對延遲渲染的受益部分主要在GBuffer的生成階段,傳統遊戲這部分相對於lighting計算階段開銷不大,所以往往被忽略掉,但VR遊戲中受制於超大的畫素處理量,這部分的優化提升在我們遊戲中經過測試是相當明顯的。當然,世事無絕對,這裡僅作下提醒,實際要根據自己的遊戲場景做下詳盡的測試。
- 原理:
關於畫兩遍
批次翻倍加上面數翻倍因此VR遊戲中優化批次和麵數較傳統遊戲的意義更大。
- 靜態場景的批次優化:針對UE4,我們專門做了擴充套件工具來合併場景中相同物體的批次,而不需要美術對已經做好的場景進行返工。
絕大多數情況下,這事總是程式開發效率對美術製作效率的妥協,程式逃不掉的:)
- 動態批次優化:多用instance的思想合併數量巨多但因個頭小而往往被忽視的物體,典型的如FPS遊戲中的子彈。
- 其實優化中很多這樣的情況,比如不起眼的string對效能和記憶體造成的巨大的壓力(當然如string相關的如此底層的優化,現代成熟引擎已經都做好了)
- 面數:對UE4而言,其消耗體現在生成GBuffer的Base pass階段,要善用統計工具去定時定性得分析遊戲場景;
- 另外關於面數除了美術提供的靜態場景和角色之外一定要關注下自動生成的東西,如tessellation;工具可能也會統計不到。
- 舉例:UE4中Ribbon特效的tessellation預設步長為15uu,而我們遊戲中的Ribbon特效可達30000uu,如果不改變預設值,一條拖尾
可生成4000面,同屏50條拖尾就令絕大部分GPU歇菜了 - 特定遊戲中特例化的問題防不勝防,應善用不同工具從多種角度分析。
- 舉例:UE4中Ribbon特效的tessellation預設步長為15uu,而我們遊戲中的Ribbon特效可達30000uu,如果不改變預設值,一條拖尾
其他
當然,前面講的都是針對VR遊戲的特點來重點強調的,其他的優化方法同樣使用,根據之前的經驗做下總結,包括但不限於:
- 對錶現效果妥協,如很多手機平臺的遊戲角色連normal都沒有。。還有貼圖精度,模型精度等
- 對製作流程 、製作效率的妥協。如開發無盡之劍XboxOne版時發現,UI直接呼叫d3d API畫的。。
- 開發效率的妥協。 注意shader中的資料型別,頂點的資料格式等,能用16位浮點就不要用32位的浮點
- 遊戲型別具體分析,比如如果確定場景中物件都必須渲染則把Ocullusion Culling關掉,因此這種情況下不需要預計算遮擋剔除關係!
- 特別注意下CPU、GPU的同步點,執行緒之間的同步點(多發生在競爭統一資源上,如主執行緒和第三方庫的執行緒用同一個記憶體分配器)
- 善用第三方庫站在巨人肩膀,比如小記憶體多,分配頻繁自己又懶得寫記憶體庫的話,乾脆用tcmalloc、nedmalloc等
- 多用LOD,不只是貼圖mipmap、模型LOD等這種,還有邏輯層面的LOD,如特效分層LOD
- 不同Actor、不同Component、不同系統設定不同的更新頻率
- 多執行緒加速、SIMD加速
- 很track的做法:避免使用基於win32 API的高階函式,例如memeset,因為這個是單位元組填充;可用匯編進行優化,效率提升明顯(當然成熟引擎不需要操心這點)
其他方案
除了這些,業界還有些全新的優化方案,這裡也做下介紹。
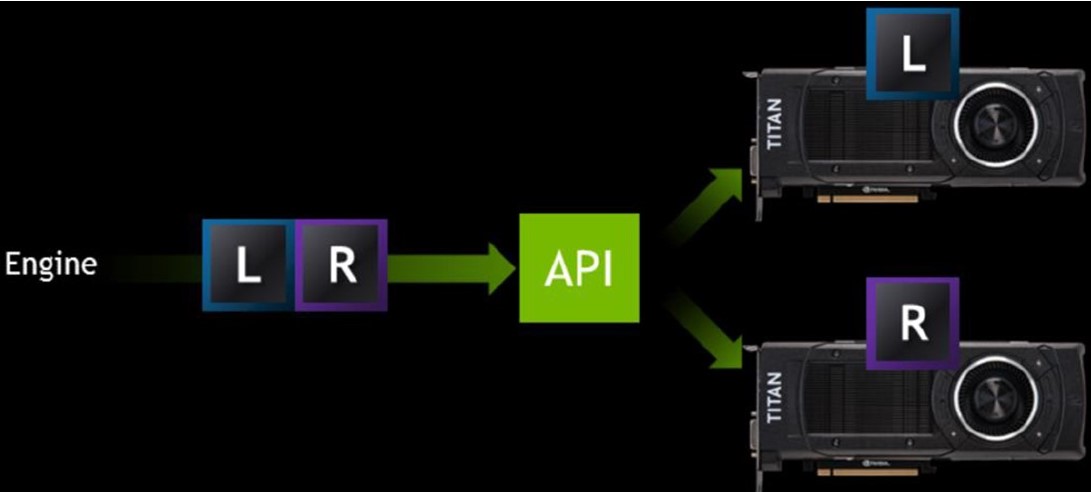
- 多/雙顯示卡渲染:
- DX12支援顯示卡混搭,可把render task繫結到任意GPU上
- Nvidia的SLI和ATI的CrossFire可應付非DX12的情況,叫法不同但原理相同:一塊顯示卡渲染左眼,另一塊顯示卡渲染右眼:
要求兩塊顯示卡必須型號一致,實測效果很不錯
- StencilMesh的思想,同樣是culling,不過在另外的層面上。UE4中的實現叫做HMD Distortion Mask,實際也是節省掉周圍四角區域的畫素計算。
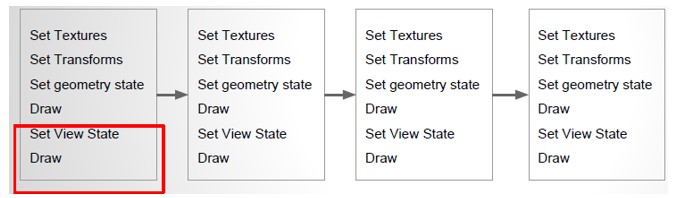
- Instanced stereo Rendering:
- 核心思想:一次提交繪製雙份幾何體,draw call不需要翻倍了
- UE4的4.11 preview版本已經放出了第一個版本的實現
- Multi-Resolution
- 人眼對中心區域畫素更敏感,所以保持中心區域解析度並降低邊緣區域解析度。整體解析度降低的同時儘可能抵消對效果的影響。
這種方法可以節省25%~50%的畫素處理量
- 人眼對中心區域畫素更敏感,所以保持中心區域解析度並降低邊緣區域解析度。整體解析度降低的同時儘可能抵消對效果的影響。



補充和總結
其實真正做優化之前,有兩點怎麼強調都不為過:
- 穩定測試環境。包括關閉PC上其他3D程式,關閉垂直同步,保證每次取樣點以及取樣上下文完全一致,不要以編輯器模式啟動等等。
- 量化觀測資料。同一遊戲,在完全穩定的測試環境下,前後兩次測試的效能觀測資料有有些許浮動都是很正常的,因此直覺不可靠!直覺不可靠!
直覺不可靠!重要的事情說三遍!不要想當然的認為:”這個沒影響“,”那個沒關係“,”這次有提升“,”感覺沒作用“等等。捕獲如下精確的資料加以分析才是靠譜的做法。
另外,優化是一個長期迭代進行的過程,中間過程做好記錄;遇到和美術PK的情況,也要做到儘量用資料說話。
