
資料探勘模型中的IV和WOE詳解
http://blog.csdn.net/kevin7658/article/details/50780391
1.IV的用途
IV的全稱是Information Value,中文意思是資訊價值,或者資訊量。
我們在用邏輯迴歸、決策樹等模型方法構建分類模型時,經常需要對自變數進行篩選。比如我們有200個候選自變數,通常情況下,不會直接把200個變數直接放到模型中去進行擬合訓練,而是會用一些方法,從這200個自變數中挑選一些出來,放進模型,形成入模變數列表。那麼我們怎麼去挑選入模變數呢?
挑選入模變數過程是個比較複雜的過程,需要考慮的因素很多,比如:變數的預測能力,變數之間的相關性,變數的簡單性(容易生成和使用),變數的強壯性(不容易被繞過),變數在業務上的可解釋性(被挑戰時可以解釋的通)等等。但是,其中最主要和最直接的衡量標準是變數的預測能力。
“變數的預測能力”這個說法很籠統,很主觀,非量化,在篩選變數的時候我們總不能說:“我覺得這個變數預測能力很強,所以他要進入模型”吧?我們需要一些具體的量化指標來衡量每自變數的預測能力,並根據這些量化指標的大小,來確定哪些變數進入模型。IV就是這樣一種指標,他可以用來衡量自變數的預測能力。類似的指標還有資訊增益、基尼係數等等。
2.對IV的直觀理解
從直觀邏輯上大體可以這樣理解“用IV去衡量變數預測能力”這件事情:我們假設在一個分類問題中,目標變數的類別有兩類:Y1,Y2。對於一個待預測的個體A,要判斷A屬於Y1還是Y2,我們是需要一定的資訊的,假設這個資訊總量是I,而這些所需要的資訊,就蘊含在所有的自變數C1,C2,C3,……,Cn中,那麼,對於其中的一個變數Ci來說,其蘊含的資訊越多,那麼它對於判斷A屬於Y1還是Y2的貢獻就越大,Ci的資訊價值就越大,Ci的IV就越大,它就越應該進入到入模變數列表中。
3.IV的計算
前面我們從感性角度和邏輯層面對IV進行了解釋和描述,那麼回到數學層面,對於一個待評估變數,他的IV值究竟如何計算呢?為了介紹IV的計算方法,我們首先需要認識和理解另一個概念——WOE,因為IV的計算是以WOE為基礎的。
3.1WOE
WOE的全稱是“Weight of Evidence”,即證據權重。WOE是對原始自變數的一種編碼形式。
要對一個變數進行WOE編碼,需要首先把這個變數進行分組處理(也叫離散化、分箱等等,說的都是一個意思)。分組後,對於第i組,WOE的計算公式如下:
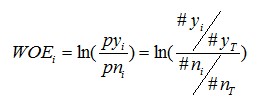
其中,pyi是這個組中響應客戶(風險模型中,對應的是違約客戶,總之,指的是模型中預測變數取值為“是”或者說1的個體)佔所有樣本中所有響應客戶的比例,pni是這個組中未響應客戶佔樣本中所有未響應客戶的比例,#yi是這個組中響應客戶的數量,#ni是這個組中未響應客戶的數量,#yT是樣本中所有響應客戶的數量,#nT是樣本中所有未響應客戶的數量。
從這個公式中我們可以體會到,WOE表示的實際上是“當前分組中響應客戶佔所有響應客戶的比例”和“當前分組中沒有響應的客戶佔所有沒有響應的客戶的比例”的差異。
對這個公式做一個簡單變換,可以得到:
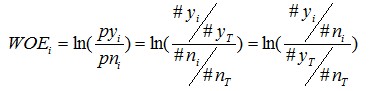
變換以後我們可以看出,WOE也可以這麼理解,他表示的是當前這個組中響應的客戶和未響應客戶的比值,和所有樣本中這個比值的差異。這個差異是用這兩個比值的比值,再取對數來表示的。WOE越大,這種差異越大,這個分組裡的樣本響應的可能性就越大,WOE越小,差異越小,這個分組裡的樣本響應的可能性就越小。
關於WOE編碼所表示的意義,大家可以自己再好好體會一下。
3.2 IV的計算公式
有了前面的介紹,我們可以正式給出IV的計算公式。對於一個分組後的變數,第i 組的WOE前面已經介紹過,是這樣計算的:
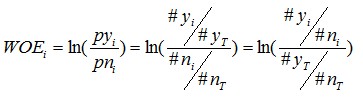
同樣,對於分組i,也會有一個對應的IV值,計算公式如下:
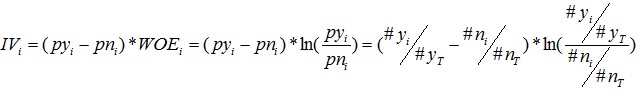
有了一個變數各分組的IV值,我們就可以計算整個變數的IV值,方法很簡單,就是把各分組的IV相加:
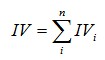
其中,n為變數分組個數。
3.3 用例項介紹IV的計算和使用
下面我們通過一個例項來講解一下IV的使用方式。
3.3.1 例項
假設我們需要構建一個預測模型,這個模型是為了預測公司的客戶集合中的每個客戶對於我們的某項營銷活動是否能夠響應,或者說我們要預測的是客戶對我們的這項營銷活動響應的可能性有多大。假設我們已經從公司客戶列表中隨機抽取了100000個客戶進行了營銷活動測試,收集了這些客戶的響應結果,作為我們的建模資料集,其中響應的客戶有10000個。另外假設我們也已經提取到了這些客戶的一些變數,作為我們模型的候選變數集,這些變數包括以下這些(實際情況中,我們擁有的變數可能比這些多得多,這裡列出的變數僅僅是為了說明我們的問題):
- 最近一個月是否有購買;
- 最近一次購買金額;
- 最近一筆購買的商品類別;
- 是否是公司VIP客戶;
假設,我們已經對這些變數進行了離散化,統計的結果如下面幾張表所示。
(1) 最近一個月是否有過購買:

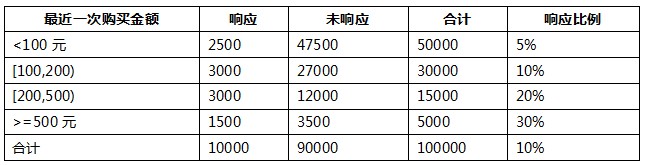
(2) 最近一次購買金額:
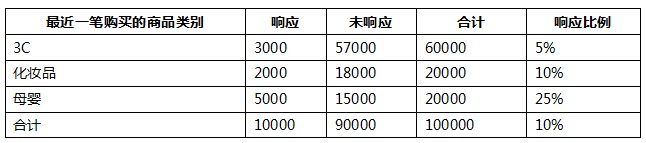
(3) 最近一筆購買的商品類別:
(4) 是否是公司VIP客戶:

3.3.2 計算WOE和IV
我們以其中的一個變數“最近一次購買金額”變數為例:

我們把這個變數離散化為了4個分段:<100元,[100,200),[200,500),>=500元。首先,根據WOE計算公式,這四個分段的WOE分別為:
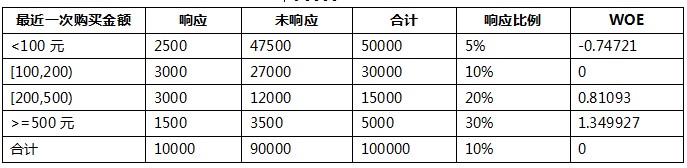
插播一段,從上面的計算結果中我們可以看一下WOE的基本特點:
- 當前分組中,響應的比例越大,WOE值越大;
- 當前分組WOE的正負,由當前分組響應和未響應的比例,與樣本整體響應和未響應的比例的大小關係決定,當前分組的比例小於樣本整體比例時,WOE為負,當前分組的比例大於整體比例時,WOE為正,當前分組的比例和整體比例相等時,WOE為0。
- WOE的取值範圍是全體實數。
我們進一步理解一下WOE,會發現,WOE其實描述了變數當前這個分組,對判斷個體是否會響應(或者說屬於哪個類)所起到影響方向和大小,當WOE為正時,變數當前取值對判斷個體是否會響應起到的正向的影響,當WOE為負時,起到了負向影響。而WOE值的大小,則是這個影響的大小的體現。
好,回到正題,計算完WOE,我們分別計算四個分組的IV值:
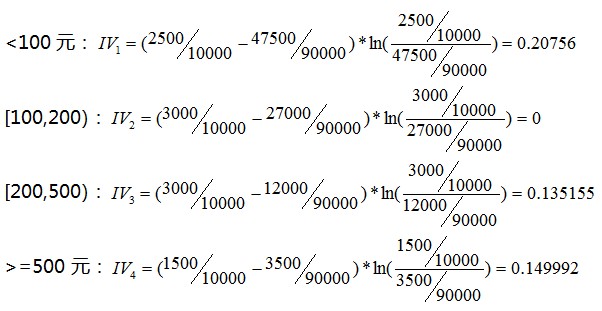
再插播一段,從上面IV的計算結果我們可以看出IV的以下特點:
- 對於變數的一個分組,這個分組的響應和未響應的比例與樣本整體響應和未響應的比例相差越大,IV值越大,否則,IV值越小;
- 極端情況下,當前分組的響應和未響應的比例和樣本整體的響應和未響應的比例相等時,IV值為0;
- IV值的取值範圍是[0,+∞),且,噹噹前分組中只包含響應客戶或者未響應客戶時,IV = +∞。
OK,再次回到正題。最後,我們計算變數總IV值:
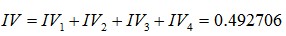
3.3.3 IV值的比較和變數預測能力的排序
我們已經計算了四個變數中其中一個的WOE和IV值。另外三個的計算過程我們不再詳細的說明,直接給出IV結果。
- 最近一個月是否有過購買:0.250224725
- 最近一筆購買的商品類別:0.615275563
- 是否是公司VIP客戶:1.56550367
前面我們已經計算過,最近一次購買金額的IV為0.49270645
這四個變數IV排序結果是這樣的:是否是公司VIP客戶 > 最近一筆購買的商品類別 > 最近一次購買金額 > 最近一個月是否有過購買。我們發現“是否是公司VIP客戶”是預測能力最高的變數,“最近一個月是否有過購買”是預測能力最低的變數。如果我們需要在這四個變數中去挑選變數,就可以根據IV從高到低去挑選了。
4.關於IV和WOE的進一步思考
4.1 為什麼用IV而不是直接用WOE
從上面的內容來看,變數各分組的WOE和IV都隱含著這個分組對目標變數的預測能力這樣的意義。那我們為什麼不直接用WOE相加或者絕對值相加作為衡量一個變數整體預測能力的指標呢?
並且,從計算公式來看,對於變數的一個分組,IV是WOE乘以這個分組響應占比和未響應占比的差。而一個變數的IV等於各分組IV的和。如果願意,我們同樣也能用WOE構造出一個這樣的一個和出來,我們只需要把變數各個分組的WOE和取絕對值再相加,即(取絕對值是因為WOE可正可負,如果不取絕對值,則會把變數的區分度通過正負抵消的方式抵消掉):

那麼我們為什麼不直接用這個WOE絕對值的加和來衡量一個變數整體預測能力的好壞,而是要用WOE處理後的IV呢。
我們這裡給出兩個原因。IV和WOE的差別在於IV在WOE基礎上乘以的那個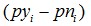
第一個原因,當我們衡量一個變數的預測能力時,我們所使用的指標值不應該是負數,否則,說一個變數的預測能力的指標是-2.3,聽起來很彆扭。從這個角度講,乘以pyn這個係數,保證了變數每個分組的結果都是非負數,你可以驗證一下,當一個分組的WOE是正數時,pyn也是正數,當一個分組的WOE是負數時,pyn也是負數,而當一個分組的WOE=0時,pyn也是0。
當然,上面的原因不是最主要的,因為其實我們上面提到的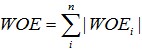
更主要的原因,也就是第二個原因是,乘以pyn後,體現出了變數當前分組中個體的數量佔整體個體數量的比例,對變數預測能力的影響。怎麼理解這句話呢?我們還是舉個例子。
假設我們上面所說的營銷響應模型中,還有一個變數A,其取值只有兩個:0,1,資料如下:

我們從上表可以看出,當變數A取值1時,其響應比例達到了90%,非常的高,但是我們能否說變數A的預測能力非常強呢?不能。為什麼呢?原因就在於,A取1時,響應比例雖然很高,但這個分組的客戶數太少了,佔的比例太低了。雖然,如果一個客戶在A這個變數上取1,那他有90%的響應可能性,但是一個客戶變數A取1的可能性本身就非常的低。所以,對於樣本整體來說,變數的預測能力並沒有那麼強。我們分別看一下變數各分組和整體的WOE,IV。

從這個表我們可以看到,變數取1時,響應比達到90%,對應的WOE很高,但對應的IV卻很低,原因就在於IV在WOE的前面乘以了一個係數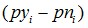
4.2 IV的極端情況以及處理方式
IV依賴WOE,並且IV是一個很好的衡量自變數對目標變數影響程度的指標。但是,使用過程中應該注意一個問題:變數的任何分組中,不應該出現響應數=0或非響應數=0的情況。
原因很簡單,當變數一個分組中,響應數=0時,
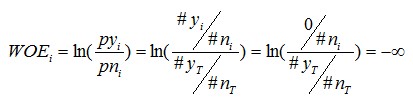
此時對應的IVi為+∞。
而當變數一個分組中,沒有響應的數量 = 0時,
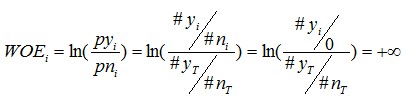
此時的IVi為+∞。
IVi無論等於負無窮還是正無窮,都是沒有意義的。
由上述問題我們可以看到,使用IV其實有一個缺點,就是不能自動處理變數的分組中出現響應比例為0或100%的情況。那麼,遇到響應比例為0或者100%的情況,我們應該怎麼做呢?建議如下:
(1)如果可能,直接把這個分組做成一個規則,作為模型的前置條件或補充條件;
(2)重新對變數進行離散化或分組,使每個分組的響應比例都不為0且不為100%,尤其是當一個分組個體數很小時(比如小於100個),強烈建議這樣做,因為本身把一個分組個體數弄得很小就不是太合理。
(3)如果上面兩種方法都無法使用,建議人工把該分組的響應數和非響應的數量進行一定的調整。如果響應數原本為0,可以人工調整響應數為1,如果非響應數原本為0,可以人工調整非響應數為1.