
資料探勘模型介紹之三:決策樹
1. 適用的場景
(1)分析對某種響應可能性影響最大的因素,比如判斷具有什麼特徵的客戶流失概率更高;
(2)為其他模型篩選變數。決策樹找到的變數是對目標變數影響很大的變數。所以可以作為篩選變數的手段。
注:
1)決策樹篩選的變數之間的獨立性可能不夠,因為決策樹每次選擇變數時不會考慮變數和其他變數的相關性。所以,如果其他模型自變數的相關性很敏感,用決策樹篩選變數時需要檢查變數的相關性。
2)如果為迴歸模型篩選變數,需要注意,決策樹篩選出的變數和因變數之間的關係可能不具有單調性,因此用在迴歸模型中可能並不好用。這樣的變數可以不用,或者進行離散化處理。
(3)預測因變數屬於某一類的可能性或者可能性排名。比如因變數的類別為“響應”和“不響應”,“流失”和“不流失”,“類別一”、“類別二”和“類別三”。
注:
1)如果訓練集的樣本是分層抽樣的,即抽樣中各類別的比例和原始資料不同,那麼,模型結果顯示的屬於某一類的概率也是不準確的。這時,概率排名是有意義的,但概率本身沒有意義。如果模型目標是提取某類別可能性最高部分客戶,但對屬於某類別的可能性不關心的話,直接用模型的結果就行。如果模型的目標是預測屬於某類別的概率,那麼,需要把原始資料在模型裡執行一下,得到原始資料在各個葉子節點裡各分類的真實概率。
2)使用決策樹直接預測記錄屬於哪個類別並不好用,因為對於很多情況下,記錄屬於某個類別的比例特別低,而這個特別低比例的記錄卻是使用者真正感興趣的記錄。而如果直接把決策樹作為分類器,很多時候會把所有葉子節點的類別都分為同一個類別,並且這個類別不是使用者關心的。比如,為預測客戶響應營銷的可能性使用決策樹,訓練資料集裡的客戶總體響應率可能只有1%甚至更低。這樣建立模型後,模型結果裡,所有葉子節點中,純度最高的節點,可能也只有5%的響應客戶。這樣,如果本模型用於分類,那麼,所有節點的類別都是不響應。
2. 決策樹構建過程
(1) 確定模型目標(可以參考文章第一部分:使用場景);
(2) 確定訓練集資料、驗證集資料、目標變數、自變數,對資料進行必要的預處理;
(3) 使用訓練集進行決策樹構建:
1) 常用演算法:CART,CHAID,C5.0,C4.5等;
2) 主要過程:從根節點開始進行不斷的劃分,進行剪枝;
3) 確定最佳劃分的主要標準:劃分後節點的純度;
(4) 使用測試集進行模型的驗證;
(5) 確定模型。
3. 決策樹構建關鍵過程:劃分
3.1 劃分的總體標準
確定最佳劃分的總體標準:(1)劃分後,子節點的純度提升最大;(2)每個子節點記錄數不太少(至少也有幾十個)。
所謂純度提升,可以這樣理解:就是劃分後,一個子節點裡的所有記錄,在各個分類上分佈比父節點更不平均。比如,一個決策樹要對記錄進行類別預測,一共有兩個類別A和B,父節點的記錄在A和B上的的分佈是A:60%,B:40%。進行進一步劃分後,父節點劃分後,其中一個子節點上A和B的分佈是,A:85%,B:15%,那麼,這個節點的純度就比父節點有了提升。實際模型的純度計算要比這個例子複雜,並且有很多計算方式。

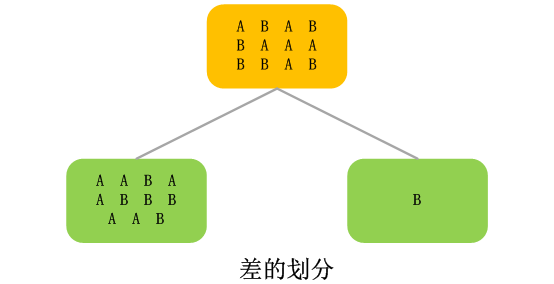

3.2 針對數值型變數的劃分方式
如果當前要劃分的變數是數值型變數,一般的處理方式是,把數值型變數截成分段,比如,前三個月購買金額欄位,截成“<3500”、“>=3500”。
決策樹演算法中,會把數值型變數進進行分段處理,這樣會有一個後果,就是對於極端值所包含的資訊不敏感,尤其是當極端值確實包含了重要資訊時,這些資訊很可能不能在模型中表現出來。
注:
1) 因為劃分過程一般由演算法自動完成,所以很可能劃分的分界點不是非常規整的整數,比如,可能是“<3527”、“>=3527”。
2) 劃分成的段數由具體演算法和配置的引數確定,可能分成兩段,也可能分成三個以上的分段。
3.3 針對分型別變數的劃分方式
如果當前要劃分的變數是分型別變數,處理方式相對簡單一些,一般的處理方式是,演算法會按照各分類的表現,確定把一些分類歸為一類。比如,類別變數的取值有“A”、“B”、“C”、“D”、“E”、“F”六個類別,可能劃分成“ACD”、“BE”、“F”三個類別。當然,極端的情況是,每一個類別都單獨屬於一個劃分。比如上述分類變數的六個類別都單獨作為一個劃分。
3.4 劃分時缺失值的處理方式
決策樹處理缺失值比其他很多模型都有優勢。最常見的處理方式是可以把缺失值作為一個單獨的類別使用。當然,缺失值類別可能作為一個單獨的劃分,也可能和其他某些分類或分段歸為一個劃分。總之,缺失值的處理方式就是把缺失值作為一個單獨的分類來看待。
4. 決策樹劃分演算法
4.1 基於Gini(基尼)得分的劃分演算法
(1) 目標:劃分出的所有子節點的Gini得分加權平均和最大。
注:在一些軟體(比如SASEM)中的決策樹模型裡,如果使用Gini得分作為劃分判斷標準,Gini得分是越低越好的。原因是軟體裡對Gini得分進行的處理,比如用1減去我們這裡定義的Gini得分,從而使得最終得分越低越好。但道理都是一樣的。
(2) 過程:
1) 計算劃分出的每個子節點的Gini得分;
2) 計算劃分出的所有子節點的Gini得分的加權平均和;
3) 比較各種劃分方式所得到的所有子節點的Gini加權平均和,Gini加權平均和超過父節點的Gini得分,並且Gini加權平均和最大的劃分方式作為最終的劃分方式。
(3) 如何計算劃分出的某一個子節點的Gini得分
一個子節點的Gini得分=節點中各類別記錄數所佔的百分比的平方和。
比如:一個決策樹的目標變數有兩個分類A和B,一個子節點,A的記錄佔比是80%,B的記錄佔比是20%,那麼,本節點的Gini得分=0.82+0.22=0.64+0.04 = 0.68。
(4) 如何計算劃分出的所有子節點的Gini加權平均和
1) 計算每個子節點的Gini得分;
2) 計算每個子節點的Gini得分加權平均值;
一個子節點的Gini得分加權平均值=節點Gini得分*節點記錄數佔所有子節點總記錄數的比例。
比如:一個子節點的Gini得分是0.68,本節點有3000個記錄,另外還有兩個子節點,記錄數分別為5000和2000,那麼,本節點的Gini得分加權平均值是:
0.68*3000/(3000+5000+2000)=0.68*0.3= 0.204
3) 計算所有子節點的Gini得分加權平均值的和。
4.2 基於熵減少的劃分演算法
(1) 什麼是熵
“熵”是資訊理論裡的一個概念,可以簡單的把熵理解成“用於度量一個系統複雜程度的變數”。具體的定義和描述如果感興趣可以去查閱相關資料。
(2) 目標:劃分出的所有子節點的熵的加權平均和最小。
(3) 過程:
1) 計算劃分出的每個子節點的熵;
2) 計算劃分出的所有子節點的熵的加權平均和;
3) 比較各種劃分方式所得到的所有子節點的熵加權平均和,熵加權平均和超過父節點的熵,並且熵加權平均和最大的劃分方式作為最終的劃分方式。
(4) 如何計算劃分出的某一個子節點的熵
一個子節點的熵=節點中各類別記錄數所佔的百分比乘以該比例的以2為底的對數,然後在把各類別的這個結果相加,然後再乘以-1,即取相反數。
比如:一個決策樹的目標變數有兩個分類A和B,一個子節點,A的記錄佔比是80%,B的記錄佔比是20%,那麼,本節點的熵=-1*(0.8*log20.8+0.2*log20.2)。
(5) 如何計算劃分出的所有子節點的熵
1) 計算每個子節點的熵;
2) 計算每個子節點的熵加權平均值;
一個子節點的熵加權平均值=節點熵*節點記錄數佔所有子節點總記錄數的比例。
比如:一個子節點的熵是0.32,本節點有3000個記錄,另外還有兩個子節點,記錄數分別為5000和2000,那麼,本節點的熵加權平均值是:
0.32 *3000/(3000+5000+2000)=0.32*0.3= 0.096
3) 計算所有子節點的熵加權平均值的和。
4.3 基於卡方檢驗的劃分演算法
(1) 什麼是卡方檢驗
卡方檢驗室統計學裡的一種檢驗統計顯著性的檢驗方法。其目標是檢驗某個劃分不可能是由偶然因素和隨機產生的可能性。相關詳細資料可以查閱統計學書籍。
(2) 目標:劃分出的所有子節點的卡方值最大。
(3) 過程:
1) 計算劃分出的每個子節點的卡方值;
2) 計算劃分出的所有子節點的卡方值的和;
3) 比較各種劃分方式所得到的所有子節點的卡方值的和,卡方值的和最大的劃分方式作為最終的劃分方式。
(4) 如何計算劃分出的某一個子節點的卡方值
(5) 劃分出的所有子節點的卡方就是每個子節點卡方的和。
(6) 使用卡方檢驗的決策樹演算法:CHAID。
4.4 基於方差的劃分演算法
(1) 基於方差的劃分演算法主要應用於決策樹應用於預測數值型變數的情況下。
(2) 目標是子節點的方差減少。
4.5 基於F檢驗的劃分演算法
簡單介紹一下,基於F檢驗的方法,目標是使劃分的F檢驗值變大,越大,說明劃分效果越好。