
人臉檢測:MTCNN學習
本文來自於中國科學院深圳先進技術研究院,目前發表在arXiv上,是2016年4月份的文章,算是比較新的文章。
論文地址:
概論
用於人臉檢測和對齊。因為現實中的圖片一般還有其他背景,所以我們要檢測出人臉部分,不能遺漏,不能錯檢。
然後為了人臉識別更加精準,所以一般還要人臉對齊,通過檢測出人臉的五官:眼睛,鼻子,嘴巴等這些關鍵點位置來
進行仿射變換將人臉統一校準。
本文提出的unified cascaded CNNs by multi-task learning,包含三個階段:
1) 利用一個淺層的CNN快速產生候選視窗
2) 利用一個更復雜的CNN排除掉大量非人臉視窗
3) 利用一個更強大的CNN進一步改善結果,並輸出人臉關鍵點位置。
本文的貢獻:
1) 提出一個新的基於CNN的級聯型框架,用於聯和(joint)人臉檢測和對齊;還設計輕量級的CNN架構使得速度上可以達到實時。
2) 提出一個有效的online hard sample mining方法來提高表現能力
3) 在人臉檢測和人臉對齊上提高了不少精度
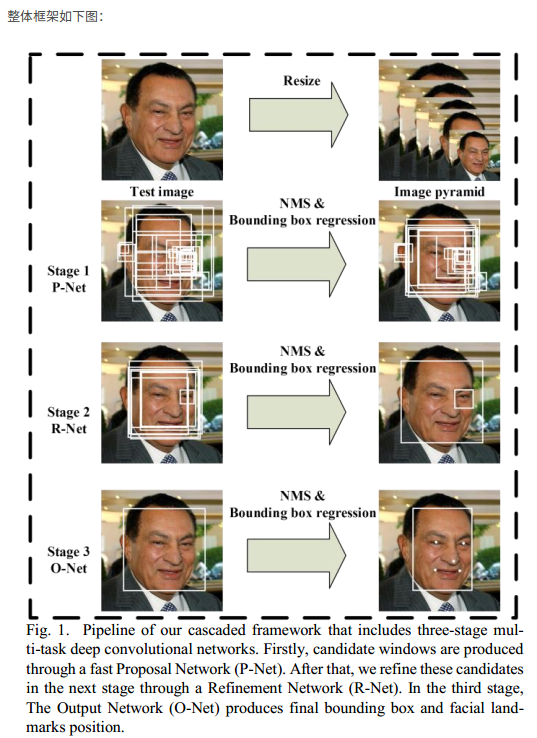
測試階段大概過程
首先影象經過金字塔,生成多個尺度的影象,然後輸入PNet, PNet由於尺寸很小,所以可以很快的選出候選區域,但是準確率不高,然後採用NMS演算法,合併候選框,然後根據候選框提取影象,作為RNet的輸入,RNet可以精確的選取邊框,一般最後只剩幾個邊框,最後輸入ONet,ONet雖然速度較慢,但是由於經過前兩個網路,已經得到了高概率的邊框,所以輸入
1. MTCNN關鍵引數
nms_threshold:非極大值抑制nms篩選人臉框時的IOU閾值,三個網路可單獨設定閾值,值設定的過小,nms合併的少,會產生較多冗餘計算。示例nms_threshold[3] = { 0.5, 0.7, 0.7 };。
threshold:人臉框得分閾值,三個網路可單獨設定閾值,值設定的太小,會有很多框通過,也就增加了計算量,還有可能導致最後不是人臉的框錯認為人臉。示例threshold[3] = {0.8, 0.8, 0.8};
minsize :最小可檢測影象,該值大小,可控制影象金字塔的階層數的引數之一,越小,階層越多,計算越多。示例minsize = 40;
factor :生成影象金字塔時候的縮放係數, 範圍(0,1),可控制影象金字塔的階層數的引數之一,越大,階層越多,計算越多。示例factor = 0.709;
輸入圖片的尺寸,minsize和factor共同影響了影象金字塔的階層數。使用者可根據自己的精度需求進行調控。
接下來對使用過程進行詳細說明:2. 生成影象金字塔
前面提到,輸入圖片的尺寸,minsize和factor共同影響了影象金字塔的階層數。也就是說決定能夠生成多少張圖。
縮放後的尺寸minL=org_L*(12/minisize)*factor^(n),n={0,1,2,3,...,N},縮放尺寸最小不能小於12,也就是縮放到12為止。n的數量也就是能夠縮放出圖片的數量。
看到上面這個公式應該就明白為啥那三個引數能夠影響階層數了吧。
3. Pnet運算
一般Pnet只做檢測和人臉框迴歸兩個任務。忽略下圖中的Facial landmark。

雖然網路定義的時候input的size是12*12*3,由於Pnet只有卷積層,我們可以直接將resize後的影象餵給網路進行前傳,只是得到的結果就不是1*1*2和1*1*4,而是m*m*2和m*m*4了。這樣就不用先從resize的圖上擷取各種12*12*3的圖再送入網路了,而是一次性送入,再根據結果回推每個結果對應的12*12的圖在輸入圖片的什麼位置。
針對金字塔中每張圖,網路forward計算後都得到了人臉得分以及人臉框迴歸的結果。人臉分類得分是兩個通道的三維矩陣m*m*2,其實對應在網路輸入圖片上m*m個12*12的滑框,結合當前圖片在金字塔圖片中的縮放scale,可以推算出每個滑框在原始影象中的具體座標。
首先要根據得分進行篩選,得分低於閾值的滑框,排除。
當金字塔中所有圖片處理完後,再利用nms對彙總的滑框進行合併,然後利用最後剩餘的滑框對應的Bbox結果轉換成原始影象中畫素座標,也就是得到了人臉框的座標。
所以,Pnet最終能夠得到了一批人臉框。
4. Rnet
Rnet仍然只做檢測和人臉框迴歸兩個任務。忽略下圖中的Facial landmark。
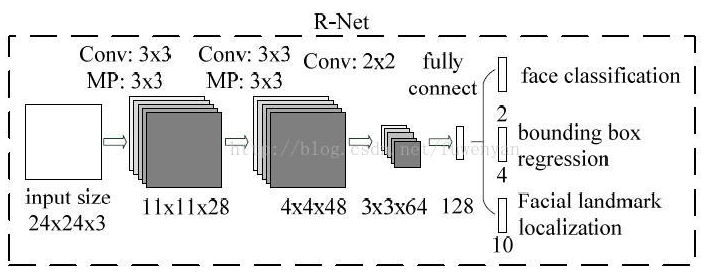
Rnet的作用是對Pnet得到的人臉框進一步打分篩選,迴歸人臉框。
將Pnet運算出來的人臉框從原圖上擷取下來,並且resize到24*24*3,作為Rnet的輸入。輸出仍然是得分和BBox迴歸結果。
對得分低於閾值的候選框進行拋棄,剩下的候選框做nms進行合併,然後再將BBox迴歸結果對映到原始影象的畫素座標上。
所以,Rnet最終得到的是在Pnet結果中精選出來的人臉框。
5. Onet
Onet將檢測,人臉框迴歸和特徵點定位,一起做了。
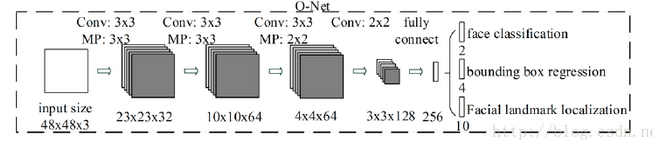
Onet的作用是對Rnet得到的人臉框進一步打分篩選,迴歸人臉框。同時在每個框上都計算特徵點位置。
將Rnet運算出來的人臉框從原圖上擷取下來,並且resize到48*48*3,作為Onet的輸入。輸出是得分,BBox迴歸結果以及landmark位置資料。
分數超過閾值的候選框對應的Bbox迴歸資料以及landmark資料進行儲存。
將Bbox迴歸資料以及landmark資料對映到原始影象座標上。
再次實施nms對人臉框進行合併。
經過這層層篩選合併後,最終剩下的Bbox以及其對應的landmark就是我們苦苦追求的結果了。
loss訓練
利用三個任務來訓練CNN檢測器:人臉/非人臉 分類 ,bounding box regression 和人臉關鍵點定位(facial landmark localization)
1) 人臉分類器。這是一個二分類問題,對於每個樣本xi,我們使用交叉熵損失:
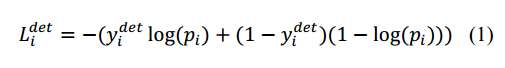
其中,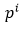 表示網路預測該樣本是人臉的概率,
表示網路預測該樣本是人臉的概率,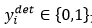 是ground-truth label。
是ground-truth label。
2) 邊界框迴歸(Bounding box regression)。對於每個候選視窗,我們預測該候選視窗與其最近的ground truth(the bounding boxes’ left top, height, and width)的偏移。這是一個迴歸問題,對每個樣本xi,使用歐式損失(Euclidean loss):
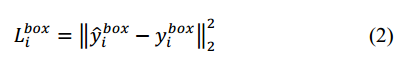
其中,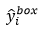 表示從網路中獲得目標的座標,
表示從網路中獲得目標的座標,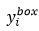 表示ground-truth座標。有4個座標,包括左上角x,y座標,高度和寬度,因此
表示ground-truth座標。有4個座標,包括左上角x,y座標,高度和寬度,因此
3) Facial landmark localization。與Bounding box regression相似,損失函式如下:
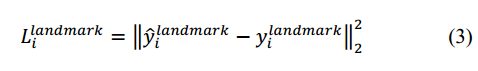
其中,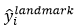 是網路預測的人臉關鍵點的座標,
是網路預測的人臉關鍵點的座標,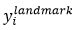 是ground-truth座標(不太理解,是提前標記好了??原論文也沒提)。有5個人臉關鍵點,包括左眼,右眼,鼻子,嘴邊左邊角,嘴巴右邊角,因此
是ground-truth座標(不太理解,是提前標記好了??原論文也沒提)。有5個人臉關鍵點,包括左眼,右眼,鼻子,嘴邊左邊角,嘴巴右邊角,因此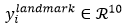
4) Multi-source training。由於在每個CNN網路中,我們使用了不同的任務,因此,在學習階段有不同種類的訓練影象,比如人臉,非人臉,部分對齊的人臉。在這種情況下,一些損失函式(公式1-3)用不到。比如說,對於背景區域圖片,我們只計算,另外兩個loss都設為0。整體的學習目標如下:
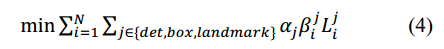
其中,N表示訓練樣本的數量,表示任務的重要性。在P-Net和R-Net中,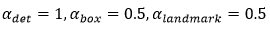 ;在O-Net中,
;在O-Net中,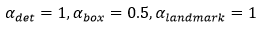 。
。 is the sample type indicator,比如說,對於背景樣本,我們只計算
is the sample type indicator,比如說,對於背景樣本,我們只計算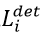 ,另外兩個loss都設為0,即此時
,另外兩個loss都設為0,即此時 。
。
在這種情況下,使用SGD來訓練網路。
5) Online Hard sample mining。與傳統的hard sample mining after original classifier had been trained不同,我們在人臉分類中採用線上的hard sample mining來自適應訓練。
在每個mini-batch中,我們從所有樣本的前向傳播中將計算得到的loss排序,然後只取其中loss最高的前70%作為hard samples。然後在反向傳播(BP)中只計算這些hard samples,忽略那些簡單的樣本。
參考:
https://blog.csdn.net/fuwenyan/article/details/77573755?locationNum=5&fps=1
https://www.cnblogs.com/hejunlin1992/p/7856414.html