Mahout推薦系統
Mahout的推薦系統
- 什麼是推薦系統
- 為什使用推薦系統
- 推薦系統中的演算法
什麼是推薦系統
為什麼使用推薦系統?
促進廠商商品銷售,幫助使用者找到想要的商品
推薦系統無處不在,體現在生活的各個方面
圖書推薦;QQ好友推薦;優酷,愛奇藝的視訊推薦;豆瓣的音樂推薦;大從點評的餐飲推薦;世紀佳緣的相親推薦;智聯招聘的職業推薦。
亞馬遜的推薦系統深入到網站的各類商品,為亞馬遜帶來了至少30%的銷售額。
推薦引擎工作原理
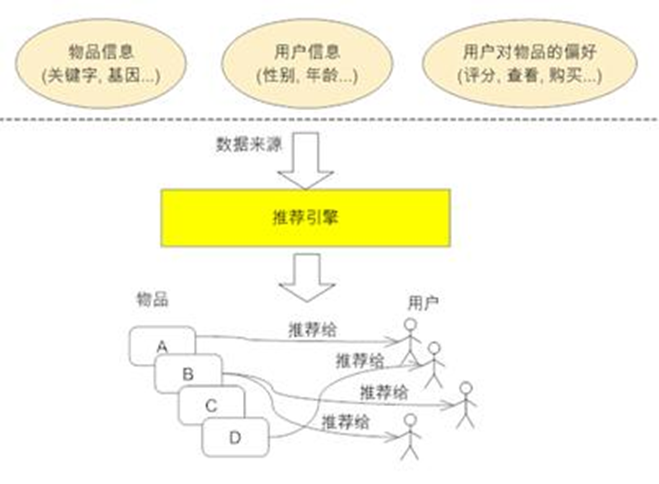
推薦系統主要向用戶推薦可能感興趣商品的系統。系統會給使用者以TopN推薦給使用者商品。
系統主要使用的資料是使用者的歷史商品購買記錄,這部分資料存放在公司的資料庫中。
Mahout的推薦系統整體架構
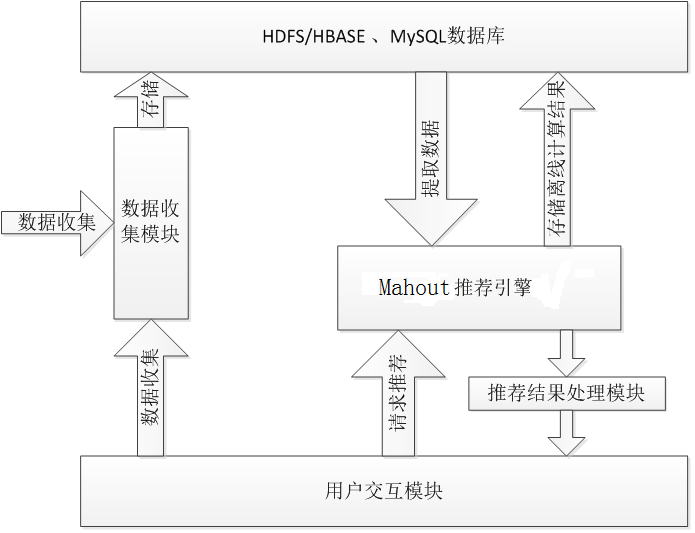
推薦系統的實現
推薦系統中的演算法
- Apriori演算法
- 基於使用者
- 基於內容
- 基於協同過濾(用的最多)
Apriori演算法-購物籃分析(關聯分析)
“啤酒與尿布”的故事產生於20世紀90年代的美國沃爾瑪超市。沃爾瑪的超市管理人員分析銷售資料時發現了一個令人難於理解的現象:在某些特定的情況下,“啤酒”與“尿布”兩件看上去毫無關係的商品會經常出現在同一個購物籃中,這種獨特的銷售現象引起了管理人員的注意,經過後續調查發現。
原來,美國的婦女通常在家照顧孩子,所以她們經常會囑咐丈夫在下班回家的路上為孩子買尿布,而丈夫在買尿布的同時又會順手購買自己愛喝的啤酒。這樣就會出現啤酒與尿布這兩件看上去不相干的商品經常會出現在同一個購物籃的現象。
這個發現為商家帶來了大量的利潤,但是如何從浩如煙海卻又雜亂無章的資料
Apriori演算法的產生
1993年美國學者Agrawal提出通過分析購物籃中的商品集合,從而找出商品之間關聯關係的關聯演算法,並根據商品之間的關係,找出客戶的購買行為。Agrawal從數學及計算機演算法角度提出了商品關聯關係的計算方法——Apriori演算法。
沃爾瑪從上個世紀90年代嘗試將Aprior算 法引入到POS機資料分析中,並獲得了成功,於是產生了“啤酒與尿布”的故事。
Apriori演算法
如何尋找?
在歷史購物記錄中,一些商品總是在一起購買。但人看上去不是那麼的直觀的,而是隱蔽的。讓計算機做這事,設法計演算法讓計算機自動去找,找到這樣的模式(規律)。
目標:尋找那些總是一起出現商品。
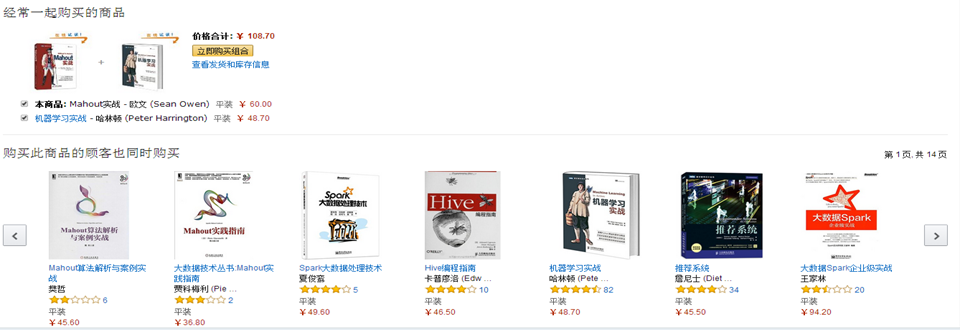
mahout實戰—>機器學習實戰
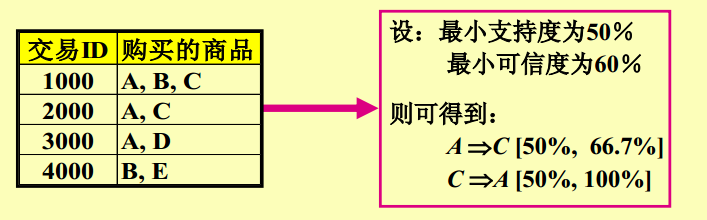
《mahout實戰》與《機器學習實戰》一起購買的記錄數佔所有商品記錄總數的比例——支援度(整體)
買了《mahout實戰》與《機器學習實戰》一起購買的記錄數佔所有購買《mahout實戰》記錄數的比例——置信度(區域性)
需要達到一定的閾值
支援度、置信度越大,商品出現一起購買的次數就越多,可信度就越大。
支援度:在所有的商品記錄中有2%量是購買《mahout實戰》與《機器學習實戰》
置信度:買《mahout實戰》的顧客中有60%的顧客購買了《機器學習實戰》
作用:找到商品購買記錄中反覆一起出現的商品,幫能助營銷人員做更好的策略,幫助顧客方便購買。
策略:
1、同時購買的商品放一起
2、同時購買的商品放兩端
支援度、置信度轉化為數學語言進行計算:
A表示《mahout實戰》 B表示《機器學習實戰》
support(A->B) = P(AB) (《mahout實戰》和《機器學習實戰》一起買佔總的購買記錄的比例)
confidence(A->B) = P(B|A) (購買了《mahout實戰》後,買《機器學習實戰》佔的比例)
項集:項的集合稱為項集,即商品的組合。
k項集:k種商品的組合,不關心商品件數,僅商品的種類。
項集頻率:商品的購買記錄數,簡稱為項集頻率,支援度計數。
注意,定義項集的支援度有時稱為相對支援度,而出現的頻率(比例)稱為絕對支援度。
頻繁項集:如果項集的相對支援度滿足給定的最小支援度閾值,則該項集是頻繁項集。
強關聯規則:滿足給定支援度和置信度閾值的關聯規則
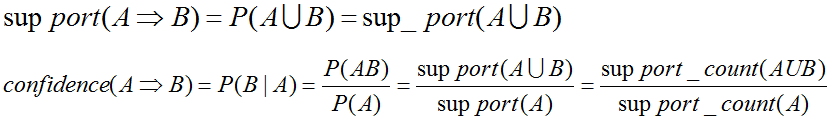
A=>B的置信度可以由A於A U B的支援度計數計算推出。滿足最小支援度計數的項集為頻繁項集。
找關聯規則問題,歸結為找頻繁項集。
注意:A=>B,B=>A的不同
明確問題
1、找出總是在一起出現的商品組合
2、提出衡量標準支援度、置信度(達到一定的閾值)
3、給出支援度、置信度直觀計算方法
4、得出在計算方法中起決定因素的是頻繁項集
5、由頻繁項集輕鬆找到強關聯規則
找關聯規則--------->找頻繁項集
步驟:
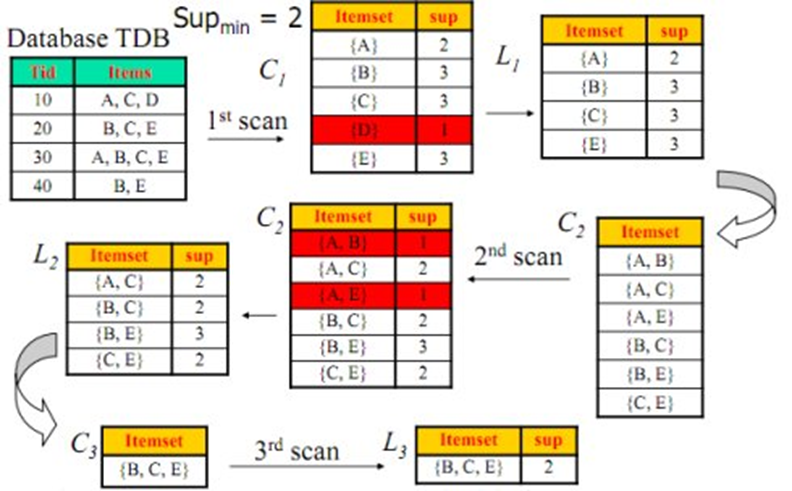
1. 找出所有的頻繁項集;這個項集出現的次數至少與要求的最小計數一樣。如在100次購買記錄中,至少一起出現30次。
2. 由頻繁項集產生強關聯規則;這些關聯規則滿足最小支援度與最小置信度。
Apriori演算法
先驗性質:頻繁項集的所有非空子集也一定是頻繁的。
逆否命題:若一個項集是非頻繁的,則它的任何超集也是非頻繁的
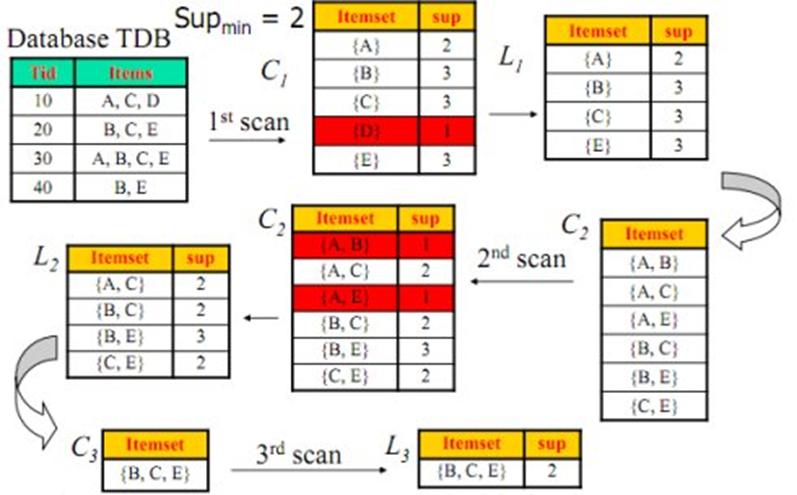
Apriori挑戰
挑戰
多次資料庫掃描
巨大數量的候補項集
繁瑣的支援度計算
改善Apriori: 基本想法
減少掃描資料庫的次數
減少候選項集的數量
簡化候選項集的支援度計算
FPGROWTH演算法(有名)
基於使用者的推薦技術
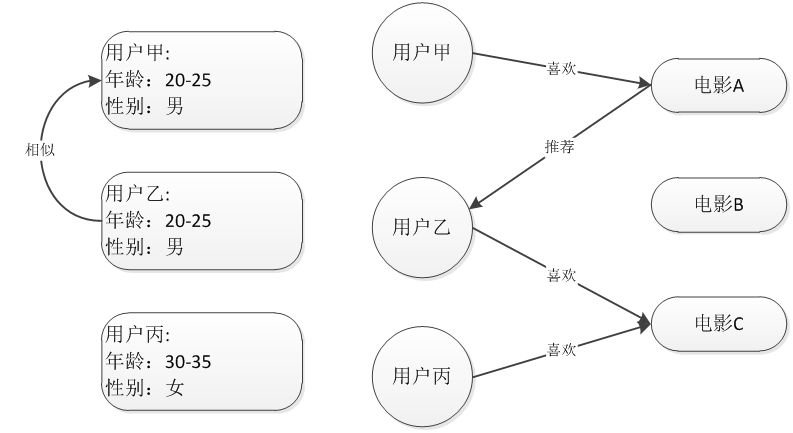
基於內容(物品)的推薦技術
協同過濾推薦技術
協同
指協調兩個或者兩個以上的不同資源或者個體,協同一致地完成某一目標的過程或能力。
原理
協同過濾技術是基於使用者對專案的歷史偏好,發掘專案之間的相關性,或者是發掘使用者間的相關性,根據這些相關性進行推薦。
類別
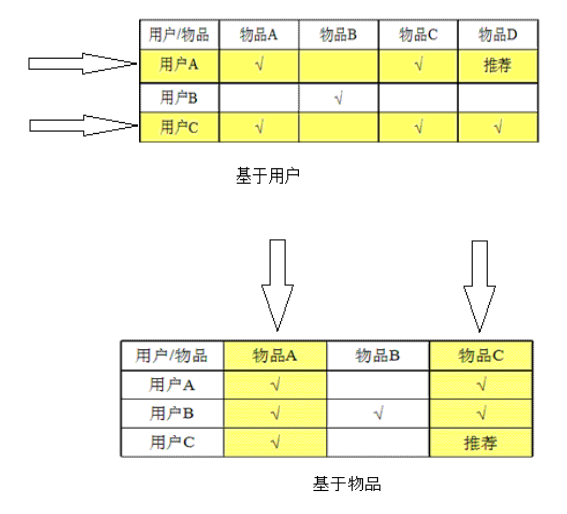
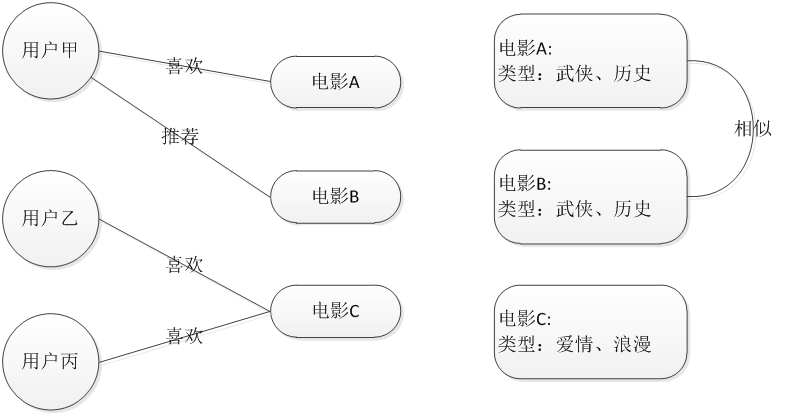
基於使用者的協同過濾推薦 Uesr_CF
基於物品的協同過濾推薦 Item_CF
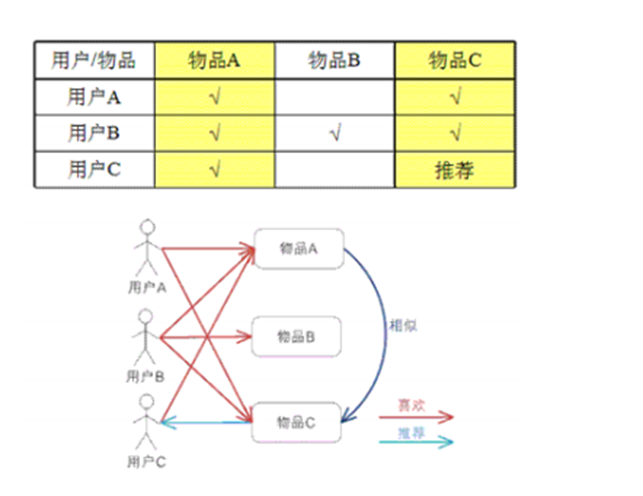
基於使用者的協同過濾推薦技術
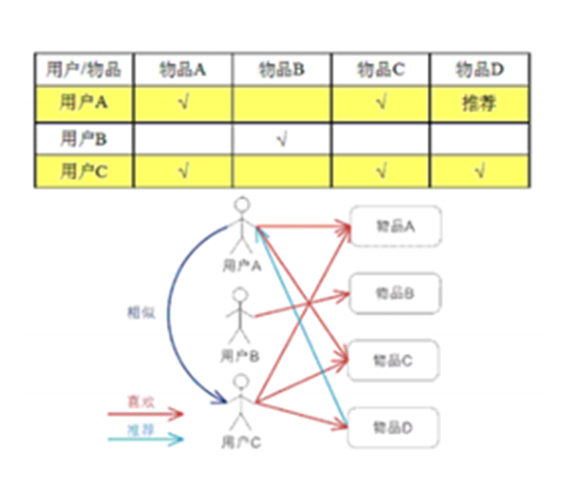
基於物品的協同過濾推薦技術(評分)
實現協同過濾的步驟
1、收集使用者偏好
2、找到相似的使用者或物品
3、計算推薦
收集使用者偏好的方法(評分)
每行3個欄位,依次是使用者ID,物品ID,使用者對物品的評分(0-5分,每0.5分為一個評分點!)

計算相似性
使用者,物品,評分
什麼人喜歡什麼,以及程度
相似性的度量
歐氏距離相似度
皮爾森相似度
餘弦相似度
秩相關係數相似度
曼哈頓距離相似度
對數似然相似度
歐氏距離相似度計算

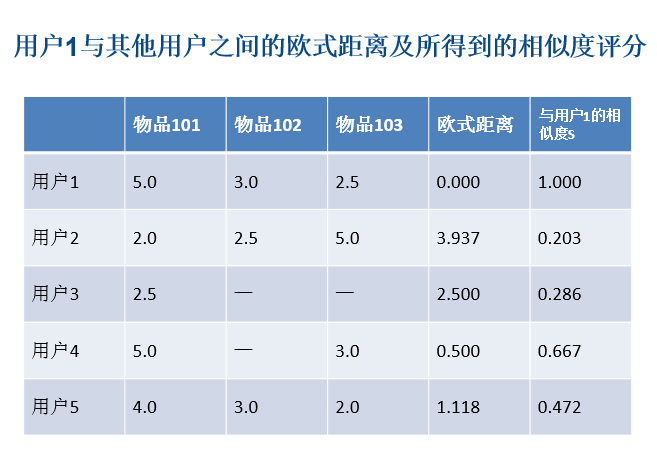
協同過濾推薦,一般要做好以下幾個步驟:
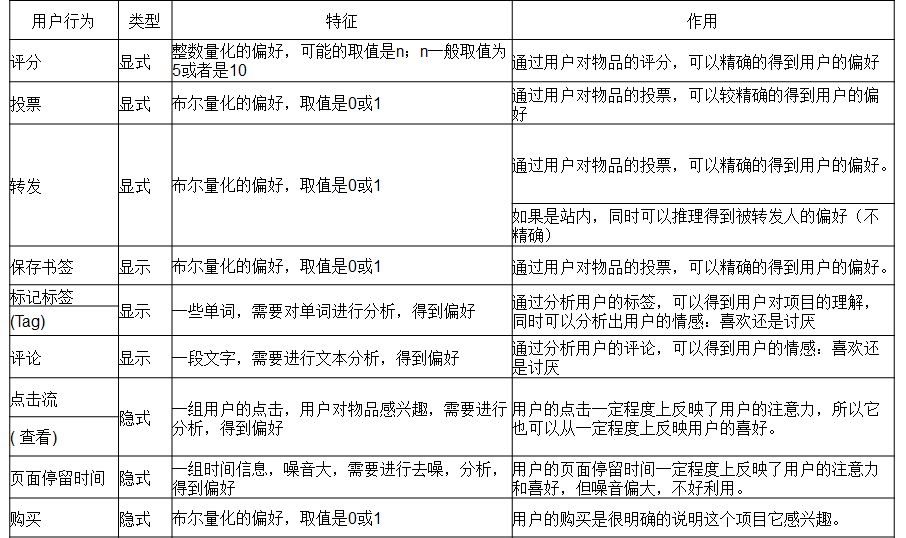
1)收集使用者偏好
通過使用者的行為諸如評分,投票,轉發,儲存,書籤,標記,評論,點選流,頁面停留時間,是否購買等獲得。所有這些資訊都數字化,用一個二維矩陣表示出來。
2)資料減噪與歸一化操作
使用者偏好的二維矩陣,一維是使用者列表,另一維是物品列表,值是使用者對物品的偏好,一般是 [0,1] 或者 [-1, 1] 的浮點數值。
3)找相似的使用者和物品,計算相似使用者或相似物品的相似度。
4)根據相似度作為使用者、物品的協同過濾推薦。
總結
Apriori
協同過濾