基於Mahout的電影推薦系統
1 Mahout介紹
Apache Mahout 是 Apache Software Foundation(ASF) 旗下的一個開源專案,提供一些可擴充套件的機器學習領域經典演算法的實現,旨在幫助開發人員更加方便快捷地建立智慧應用程式。經典演算法包括聚類、分類、協同過 濾、進化程式設計等等,並且,在 Mahout 中還加入了對Apache Hadoop的支援,使這些演算法可以更高效的執行在雲端計算環境中。
2環境部署
- Ubuntu
- JDK1.6.0_21
- MySQL
- apache-tomcat-6.0.35
- mahout-0.3
- MyEclipse 8.0
2.1JDK1.6.0_21的安裝
jdk的下載地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html我所用的版本是jdk-6u21-linux-i586.bin。
安裝步驟:
1.開啟終端,進入放置jdk安裝檔案的目錄cd /home/huhui/develop
2.更改檔案許可權為可執行chmod +x jdk-6u21-linux-i586.bin
3.執行該檔案,執行命令./jdk-6u21-linux-i586.bin
JDK自動安裝到/home/huhui/develop/jdk1.6.0_21目錄下。這個目錄下,在終端輸入java -version可以看到jdk的版本資訊:

4.安裝完JDK之後,接下來需要配置環境變數,在終端中輸入命令sudo gedit /etc/profile,此時會彈出如下對話方塊:
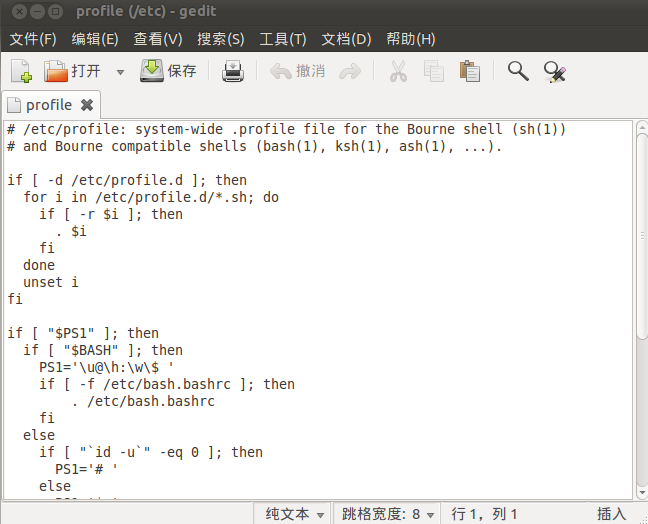
在這個文件的末尾加入如下資訊:
#set java environment
JAVA_HOME=/home/huhui/develop/jdk1.6.0_21
export JRE_HOME=/home/huhui/develop/jdk1.6.0_21/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
儲存並關閉檔案,至此,jdk的安裝與配置就完成了。
2.2MySQL的安裝
MySQL的安裝過程比較簡單,在終端輸入sudo apt-get install mysql-server my-client即可:

到這裡,要求使用者輸入Y或者N,此時選擇Y,會彈出一個介面,要求輸入mysql的root的密碼,這裡一定輸入,省得安裝後再設密碼了。
我習慣與使用視覺化工具來操作MySQL資料庫,於是我又安裝了“MySQL Administrator”軟體,這個是資料庫管理軟體,執行如下圖所示: 
2.3Tomcat的安裝
軟體下載地址:http://archive.apache.org/dist/tomcat/tomcat-6/ 我下載的版本是apache-tomcat-6.0.35.tar.gz
1.解壓檔案
複製安裝檔案到hom/huhui/develop目錄下,在終端輸入sudo tar -zxvf apache-tomcat-6.0.35.tar.gz,將安裝包解壓至apache-tomcat-6.0.35目錄下
2.配置startup.sh檔案
在終端輸入sudo gedit home/huhui/develop/apache-tomcat-6.0.35/bin/startup.sh
在startup.sh檔案的末尾加入一下內容,加入的內容即為jdk的環境變數:
JAVA_HOME=/home/huhui/develop/jdk1.6.0_21
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
TOMCAT_HOME=/home/huhui/develop/apache-tomcat-6.0.35
3.啟動tomcat
進入/usr/local/apache-tomcat-6.0.35/bin/目錄,輸入sudo ./startup.sh,若出現下圖資訊,則說明tomcat安裝成功。

此時在瀏覽器中輸入http://localhost:8080/將出現tomcat的歡迎介面。
2.4Mahout安裝
1.Mahout可以從http://mirror.bit.edu.cn/apache/mahout/下載,我下載的版本是mahout-0.3.tar.gz
2.將下載下來的壓縮檔案解壓縮,將lib資料夾下的jar檔案全部拷貝出,為以後的工作做準備。doc目錄下的mahout-core資料夾下是mahout的API,供開發時查閱。
2.5MyEclipse8.0安裝
MyEclipse的安裝簡單,基本和windows下安裝一樣,此處不再贅述。MyEclipse安裝完成之後,將前面安裝好的tomcat關聯到MyEclipse下。
至此,已經完成了對環境的部署,下面進入開發階段。
3工程開發
3.1推薦引擎簡介
推薦引擎利用特殊的資訊過濾(IF,Information Filtering)技術,將不同的內容(例如電影、音樂、書籍、新聞、圖片、網頁等)推薦給可能感興趣的使用者。通常情況下,推薦引擎的實現是通過將使用者 的個人喜好與特定的參考特徵進行比較,並試圖預測使用者對一些未評分專案的喜好程度。參考特徵的選取可能是從專案本身的資訊中提取的,或是基於使用者所在的社 會或社團環境。
根據如何抽取參考特徵,我們可以將推薦引擎分為以下四大類:
• 基於內容的推薦引擎:它將計算得到並推薦給使用者一些與該使用者已選擇過的專案相似的內容。例如,當你在網上購書時,你總是購買與歷史相關的書籍,那麼基於內容的推薦引擎就會給你推薦一些熱門的歷史方面的書籍。
• 基於協同過濾的推薦引擎:它將推薦給使用者一些與該使用者品味相似的其他使用者喜歡的內容。例如,當你在網上買衣服時,基於協同過濾的推薦引擎會根據你的歷史購買記錄或是瀏覽記錄,分析出你的穿衣品位,並找到與你品味相似的一些使用者,將他們瀏覽和購買的衣服推薦給你。
• 基於關聯規則的推薦引擎:它將推薦給使用者一些採用關聯規則發現演算法計算出的內容。關聯規則的發現演算法有很多,如 Apriori、AprioriTid、DHP、FP-tree 等。
• 混合推薦引擎:結合以上各種,得到一個更加全面的推薦效果。
3.2Taste簡介
Taste 是 Apache Mahout 提供的一個協同過濾演算法的高效實現,它是一個基於 Java 實現的可擴充套件的,高效的推薦引擎。Taste 既實現了最基本的基於使用者的和基於內容的推薦演算法,同時也提供了擴充套件介面,使使用者可以方便的定義和實現自己的推薦演算法。同時,Taste 不僅僅只適用於 Java 應用程式,它可以作為內部伺服器的一個元件以 HTTP 和 Web Service 的形式向外界提供推薦的邏輯。
3.3Taste工作原理
Taste 由以下五個主要的元件組成:
- DataModel:DataModel 是使用者喜好資訊的抽象介面,它的具體實現支援從任意型別的資料來源抽取使用者喜好資訊。Taste 預設提供 JDBCDataModel 和 FileDataModel,分別支援從資料庫和檔案中讀取使用者的喜好資訊。
- UserSimilarity 和 ItemSimilarity:UserSimilarity 用於定義兩個使用者間的相似度,它是基於協同過濾的推薦引擎的核心部分,可以用來計算使用者的“鄰居”,這裡我們將與當前使用者口味相似的使用者稱為他的鄰居。 ItemSimilarity 類似的,計算內容之間的相似度。
- UserNeighborhood:用於基於使用者相似度的推薦方法中,推薦的內容是基於找到與當前使用者喜好相似的“鄰居使用者”的方式產生的。 UserNeighborhood 定義了確定鄰居使用者的方法,具體實現一般是基於 UserSimilarity 計算得到的。
- Recommender:Recommender 是推薦引擎的抽象介面,Taste 中的核心元件。程式中,為它提供一個 DataModel,它可以計算出對不同使用者的推薦內容。實際應用中,主要使用它的實現類 GenericUserBasedRecommender 或者 GenericItemBasedRecommender,分別實現基於使用者相似度的推薦引擎或者基於內容的推薦引擎。

圖1 Taste的主要元件圖
3.4基於Taste構建電影推薦引擎
3.4.1資料下載
本工程所用到的資料來源於此處: http://www.grouplens.org/node/12,下載資料“MovieLens 1M - Consists of 1 million ratings from 6000 users on 4000 movies.”
這個資料資料夾下有三個檔案:movies.dat,ratings.dat和users.dat,資料形式如下三個圖所示:



movies.dat的檔案描述是 電影編號::電影名::電影類別
ratings.dat的檔案描述是 使用者編號::電影編號::電影評分::時間戳
users.dat的檔案描述是 使用者編號::性別::年齡::職業::Zip-code
這些檔案包含來自6040個MovieLens使用者在2000年對約3900部電影的1000209個匿名評分資訊。
3.4.2構造資料庫
構建推薦引擎,可以直接使用movie.dat檔案作為資料來源,也可以使用資料庫中的資料作為資料來源,本實驗中,這兩種方式都實現了,所以下面介紹利用dat檔案建立資料庫。
構建資料庫的SQL語句如下:
- CREATEDATABASE movie;
- USE movie;
- CREATETABLE movies ( // 儲存電影相關的資訊。
- id INTEGERNOTNULL AUTO_INCREMENT,
- namevarchar(100) NOTNULL,
- published_year varchar(4) defaultNULL,
- type varchar(100) defaultNULL,
- PRIMARYKEY (id)
- );
- CREATETABLE movie_preferences ( // 儲存使用者對電影的評分,即喜好程度
- userID INTEGERNOTNULL,
- movieID INTEGERNOTNULL,
- preference INTEGERNOTNULLDEFAULT 0,
- timestampINTEGERnotnulldefault 0,
- FOREIGNKEY (movieID) REFERENCES movies(id) ONDELETECASCADE
- );
•Movie:表示電影,包含電影的基本資訊:編號、名稱、釋出時間、型別等等。
•Movie Reference:表示某個使用者對某個電影的喜好程度,包含使用者編號、電影編號、使用者的評分以及評分的時間。
至於如何將dat檔案中的內容匯入到MySQL資料庫中,分別由本工程目錄檔案下的ImportMovies.java和ImportRatings.java檔案實現。
MySQL資料庫中的資料如下圖:
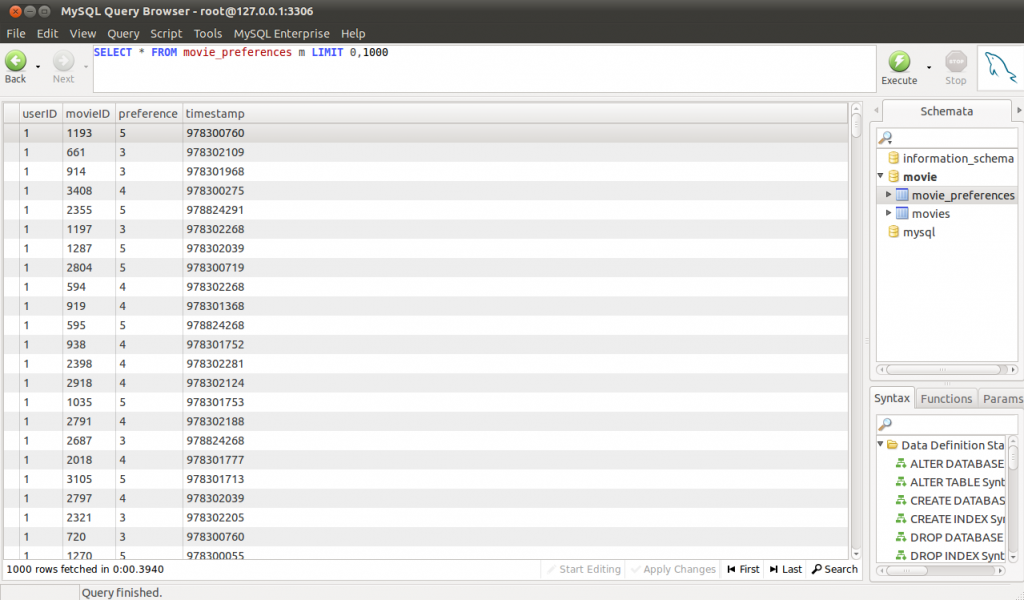
圖二 movie_preferences表記錄 
圖三 movies表記錄
3.4.3推薦引擎實現
在本工程中,我實現了三種方式的推薦引擎:基於使用者相似度的推薦引擎,基於內容相似度的推薦引擎,以及基於Slope One 的推薦引擎。在這些推薦引擎中,我分別使用了三種DataModel,即Database-based DataModel,File-based DataModel和In-memory DataModel。
a)基於使用者相似度的推薦引擎
- publicclass MyUserBasedRecommender {
- public List<RecommendedItem> userBasedRecommender(long userID,int size) {
- // step:1 構建模型 2 計算相似度 3 查詢k緊鄰 4 構造推薦引擎
- List<RecommendedItem> recommendations = null;
- try {
- DataModel model = MyDataModel.myDataModel();//構造資料模型,Database-based
- UserSimilarity similarity = new PearsonCorrelationSimilarity(model);//用PearsonCorrelation 演算法計算使用者相似度
- UserNeighborhood neighborhood = new NearestNUserNeighborhood(3, similarity, model);//計算使用者的“鄰居”,這裡將與該使用者最近距離為 3 的使用者設定為該使用者的“鄰居”。
- Recommender recommender = new CachingRecommender(new GenericUserBasedRecommender(model, neighborhood, similarity));//構造推薦引擎,採用 CachingRecommender 為 RecommendationItem 進行快取
- recommendations = recommender.recommend(userID, size);//得到推薦的結果,size是推薦接過的數目
- } catch (Exception e) {
- // TODO: handle exception
- e.printStackTrace();
- }
- return recommendations;
- }
- publicstaticvoid main(String args[]) throws Exception {
- }
- }
在這個推薦引擎中,由於使用的是MySQLJDBCDataModel和JNDI,所以需要在tomcat的server.xml檔案中新增如下資訊:
- <Contextpath="/MyRecommender"docBase="/home/huhui/develop/apache-tomcat-6.0.35/webapps/MyRecommender"debug="0"reloadable="true">
- <Resourcename="jdbc/movie"auth="Container"type="javax.sql.DataSource"
- username="root"
- password="***"
- driverClassName="com.mysql.jdbc.Driver"
- url="jdbc:mysql://localhost:3306/movie"
- maxActive="15"
- maxIdle="7"
- defaultTransactionIsolation="READ_COMMITTED"
- validationQuery="Select 1"/>
- </Context>
Mahout 中提供了基本的相似度的計算,它們都實現了 UserSimilarity 這個介面,以實現使用者相似度的計算,包括下面這些常用的:
•PearsonCorrelationSimilarity:基於皮爾遜相關係數計算相似度 (它表示兩個數列對應數字一起增大或一起減小的可能性。是兩個序列協方差與二者方差乘積的比值)
•EuclideanDistanceSimilarity:基於歐幾里德距離計算相似度
•TanimotoCoefficientSimilarity:基於 Tanimoto 係數計算相似度
根據建立的相似度計算方法,找到鄰居使用者。這裡找鄰居使用者的方法根據前面我們介紹的,也包括兩種:“固定數量的鄰居”和“相似度門檻鄰居”計算方法,Mahout 提供對應的實現:
•NearestNUserNeighborhood:對每個使用者取固定數量 N 的最近鄰居
•ThresholdUserNeighborhood:對每個使用者基於一定的限制,取落在相似度門限內的所有使用者為鄰居。
基於 DataModel,UserNeighborhood 和 UserSimilarity 構建 GenericUserBasedRecommender,從而實現基於使用者的推薦策略。
b)基於內容相似度的推薦引擎
理解了基於使用者相似讀的推薦引擎,基於內容相似讀的推薦引擎類似,甚至更加簡單。
- publicclass MyItemBasedRecommender {
- public List<RecommendedItem> myItemBasedRecommender(long userID,int size){
- List<RecommendedItem> recommendations = null;
- try {
- DataModel model = new FileDataModel(new File("/home/huhui/movie_preferences.txt"));//構造資料模型,File-based
- ItemSimilarity similarity = new PearsonCorrelationSimilarity(model);//計算內容相似度
- Recommender recommender = new GenericItemBasedRecommender(model, similarity);//構造推薦引擎
- recommendations = recommender.recommend(userID, size);//得到推薦接過
- } catch (Exception e) {
- // TODO: handle exception
- e.printStackTrace();
- }
- return recommendations;
- }
- }
在這個推薦引擎中,使用的是File-based Datamodel,資料檔案格式如下圖所示:

每一行都是一個簡單的三元組< 使用者 ID, 物品 ID, 使用者偏好 >。
c)基於Slop One的推薦引擎
基於使用者和基於內容是最常用最容易理解的兩種推薦策略,但在大資料量時,它們的計算量會很大,從而導致推薦效率較差。因此 Mahout 還提供了一種更加輕量級的 CF 推薦策略:Slope One。
Slope One 是有 Daniel Lemire 和 Anna Maclachlan 在 2005 年提出的一種對基於評分的協同過濾推薦引擎的改進方法,下面簡單介紹一下它的基本思想。
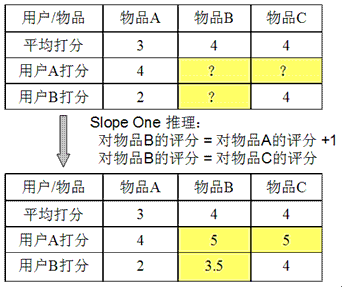
假設系統對於物品 A,物品 B 和物品 C 的平均評分分別是 3,4 和 4。基於 Slope One 的方法會得到以下規律:
•使用者對物品 B 的評分 = 使用者對物品 A 的評分 + 1
•使用者對物品 B 的評分 = 使用者對物品 C 的評分
基於以上的規律,我們可以對使用者 A 和使用者 B 的打分進行預測:
•對使用者 A,他給物品 A 打分 4,那麼我們可以推測他對物品 B 的評分是 5,對物品 C 的打分也是 5。
•對使用者 B,他給物品 A 打分 2,給物品 C 打分 4,根據第一條規律,我們可以推斷他對物品 B 的評分是 3;而根據第二條規律,推斷出評分是 4。當出現衝突時,我們可以對各種規則得到的推斷進行就平均,所以給出的推斷是 3.5。
這就是 Slope One 推薦的基本原理,它將使用者的評分之間的關係看作簡單的線性關係:
Y = mX + b;
當 m = 1 時就是 Slope One,也就是我們剛剛展示的例子。
- publicclass MySlopeOneRecommender {
- public List<RecommendedItem> mySlopeOneRecommender(long userID,int size){
- List<RecommendedItem> recommendations = null;
- try {
- DataModel model = new FileDataModel(new File("/home/huhui/movie_preferences.txt"));//構造資料模型
- Recommender recommender = new CachingRecommender(new SlopeOneRecommender(model));//構造推薦引擎
- recommendations = recommender.recommend(userID, size);//得到推薦結果
- } catch (Exception e) {
- // TODO: handle exception
- e.printStackTrace();
- }
- return recommendations;
- }
- }
d)對資料模型的優化——In-memory DataModel
上面所敘述的三種推薦引擎,輸入的都是使用者的歷史偏好資訊,在 Mahout 裡它被建模為 Preference(介面),一個 Preference 就是一個簡單的三元組 < 使用者 ID, 物品 ID, 使用者偏好 >,它的實現類是 GenericPreference,可以通過以下語句建立一個 GenericPreference:
- GenericPreference preference = new GenericPreference(1, 101, 4.0f);
這其中, 1是使用者 ID,long 型;101是物品 ID,long 型;4.0f 是使用者偏好,float 型。從這個例子可以看出,一個 GenericPreference 的資料就佔用8+8+4=20 位元組,所以如果只簡單實用陣列 Array 載入使用者偏好資料,必然佔用大量的記憶體,Mahout 在這方面做了一些優化,它建立了 PreferenceArray(介面)儲存一組使用者偏好資料,為了優化效能,Mahout 給出了兩個實現類,GenericUserPreferenceArray 和 GenericItemPreferenceArray,分別按照使用者和物品本身對使用者偏好進行組裝,這樣就可以壓縮使用者 ID 或者物品 ID 的空間。
- FastByIDMap<PreferenceArray> preferences = new FastByIDMap<PreferenceArray>();
- PreferenceArray prefsForUser1 = new GenericUserPreferenceArray(3);// 注意這裡的數字
- // 這裡是用來儲存一個使用者的元資料,這些元資料通常來自日誌檔案,比如瀏覽歷史,等等,不同的業務場合,它的業務語義是不一樣
- prefsForUser1.setUserID(0, 1);
- prefsForUser1.setItemID(0, 101);
- prefsForUser1.setValue(0, 5.0f);//<1, 101, 5.0f> < 使用者 ID, 物品 ID, 使用者偏好 >
- prefsForUser1.setItemID(1, 102);
- prefsForUser1.setValue(1, 3.0f);//<1, 102, 3.0f>
- prefsForUser1.setItemID(2, 103);
- prefsForUser1.setValue(2, 2.5f);//<1, 103, 2.5f>
- preferences.put(1l, prefsForUser1);// 在這裡新增資料,userID作為key
- ........
由於程式碼比較長,此處就不全部貼出來,詳見工程檔案中的RecommenderIntro.java檔案。
4程式演示
這個專案工程是B/S模式的,基於MVC開發模式開發的,開發環境是Ubuntu,IDE是MyEclipse8.0,工程檔案目錄如下圖:

圖四 工程檔案目錄 
主要類檔案之間的關係
專案首頁提供三個輸入:使用者id,推薦電影的數目(預設為25),推薦策略。
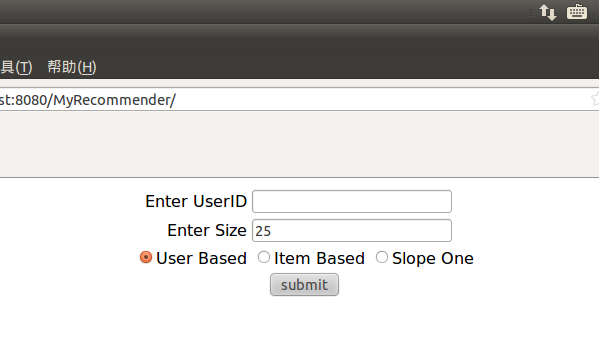
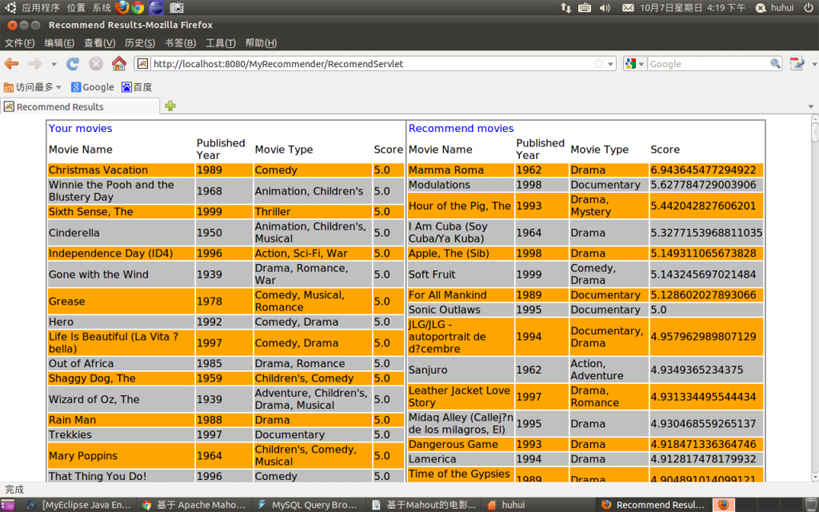
圖五 首頁
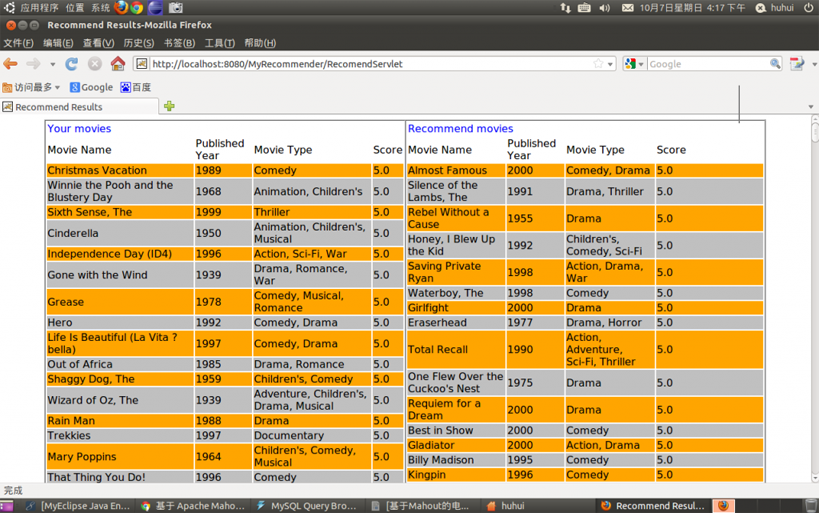
圖六 編號為10的使用者,基於使用者相似度的推薦結果
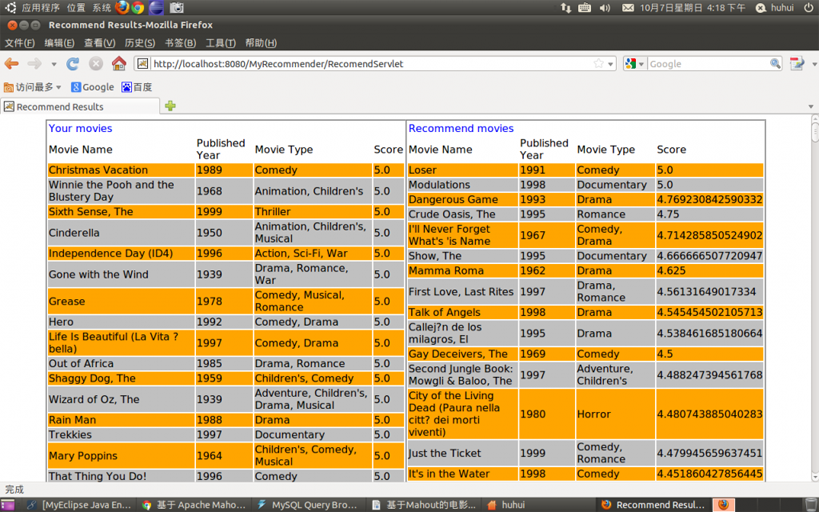
圖七 編號為10的使用者,基於內容相似度的推薦結果