
使用CNN做影象風格轉化+程式碼實現
18/6/13更新:
由於評論區很多說效果不明顯,這是因為之前使用的是Squeezenet,且並沒有經過任何預訓練,所以效果不是很好。
在這裡補上一個效果更好的、使用VGG19並經過了Imagenet預訓練的一個結構,其程式碼下載地址:vgg19_transfer
相應的權重檔案可在百度網盤下載:vgg19.npy
影象風格轉化,即將我們的原始圖片,轉換成我們想要的特定風格的圖片。這是一個比較好玩的東西,可以用來合成許多有意思的圖片。下圖為論文中給出的結果圖。

簡單來說,就是我們給定兩幅圖片,其中我們想要提取出風格的圖片為我們的style image,另一個想要提取出內容的圖片為我們的content image。
我們搭建三個卷積神經網路,其中之一用於提取style image的特徵,其二用於提取content image的特徵,最後一個神經網路初始化一個隨機噪聲影象,通過對影象做梯度下降來不斷迭代更新我們的影象,來生成我們的最終結果圖。
下圖為論文作者給出的content image 和style image在神經網路(VGG19)架構中不同層次中的視覺化表示,其結果表明在神經網路低層次中,content image的視覺化重建與原圖幾乎沒什麼差別。
簡單來說,就是我們給定兩幅圖片,其中我們想要提取出風格的圖片為我們的style image,另一個想要提取出內容的圖片為我們的content image。
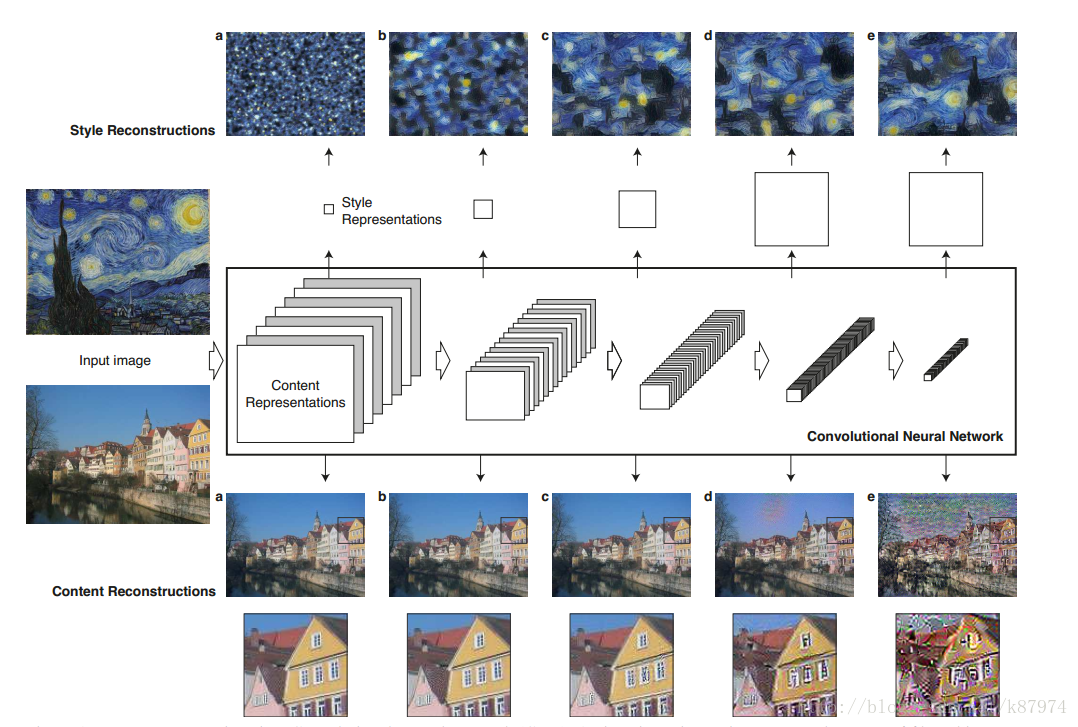
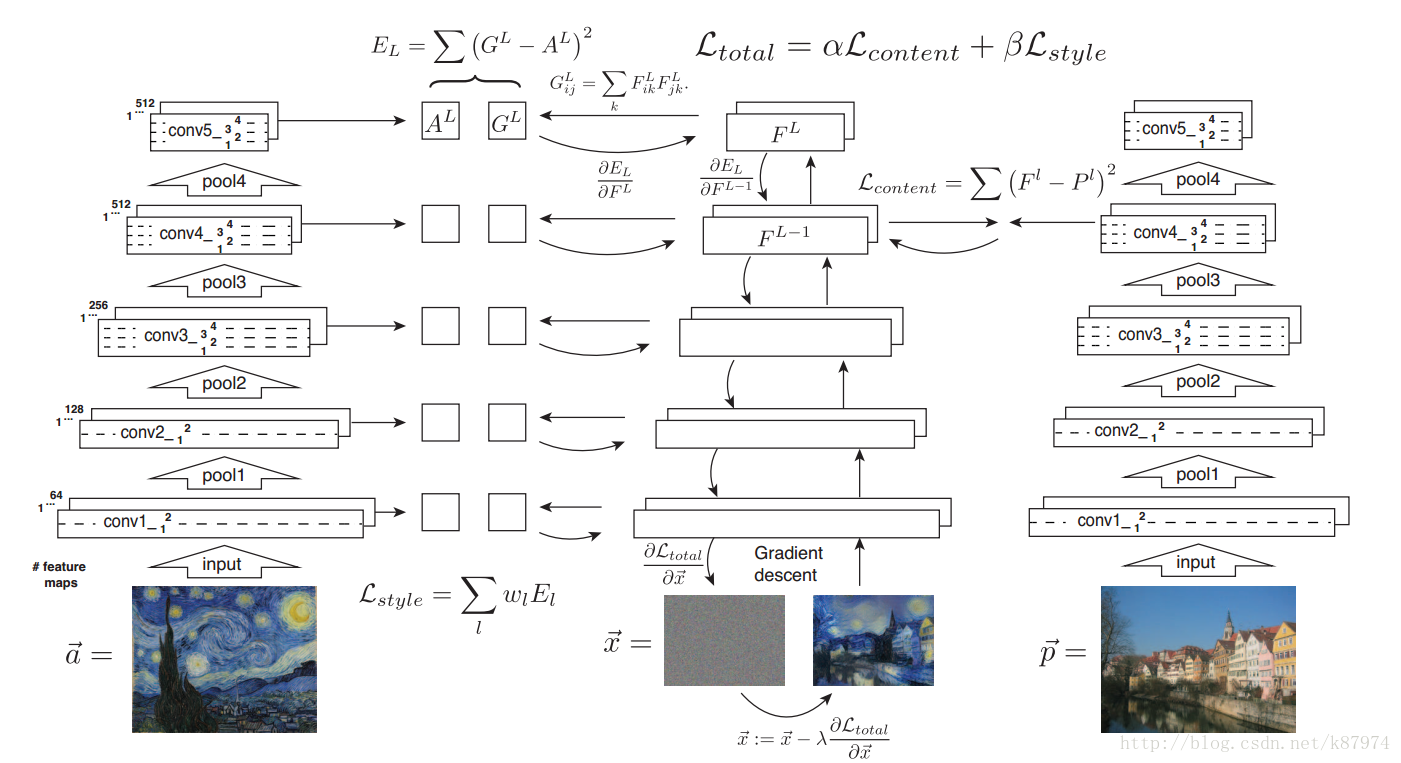
下圖所示為論文的具體實現過程,原作者使用的神經網路架構為VGG19網路。
content representation
A layer with Nl distinct filters has Nl feature maps each of size Ml, where Ml is the height times the width of the feature map. So the responses in a layer l can be stored in a matrix F l ∈ RNl×Ml where F l
ij is the activation of the ith filter at position j in layer l.簡單來說Fl 就是第l層的特徵表示。用
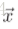
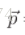 分別表示生成圖和原圖,Fl和Pl分別為其特徵表示。然後定義一個平方差loss函式。
分別表示生成圖和原圖,Fl和Pl分別為其特徵表示。然後定義一個平方差loss函式。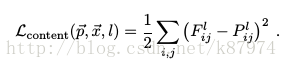
其導數如下:
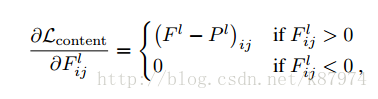
通過上述公式,我們可以使用梯度下降方法來使我們的生成影象在對應的卷積層生成與原圖相同的特徵表示。這樣這完成了我們風格轉化中內容影象的轉化。
style representation
feature correlations are given by the Gram matrix Gl ∈ RNl×Nl, where Gl ij is the inner product between the vectorised feature maps i and j in layer l: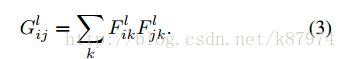
簡單來說,Gl ij 表示第l層不同feature map之間的內在點積。令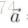
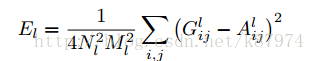
則總的style loss 就可以表示為: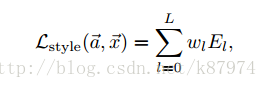
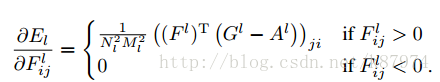
最後,總的loss如上圖中所示。
其程式碼實現,我們使用SqueezeNet,squeezeNet為AlexNet的精簡版,在達到AlexNet在imageNet上分類正確率的同事,減少了50X的引數量。簡單來講,就是效能不變,速度更快了。比較適合我這種電腦比較渣的人。
使用tensorflow的實現如下:
def content_loss(content_weight, content_current, content_original):
"""
Compute the content loss for style transfer.
Inputs:
- content_weight: scalar constant we multiply the content_loss by.
- content_current: features of the current image, Tensor with shape [1, height, width, channels]
- content_target: features of the content image, Tensor with shape [1, height, width, channels]
Returns:
- scalar content loss
"""
# tf.shape outputs a tensor containing the size of each axis.
shapes = tf.shape(content_current)
F_l = tf.reshape(content_current, [shapes[1], shapes[2]*shapes[3]])
P_l = tf.reshape(content_original,[shapes[1], shapes[2]*shapes[3]])
loss = content_weight * (tf.reduce_sum((F_l - P_l)**2))
return lossdef gram_matrix(features, normalize=True):
"""
Compute the Gram matrix from features.
Inputs:
- features: Tensor of shape (1, H, W, C) giving features for
a single image.
- normalize: optional, whether to normalize the Gram matrix
If True, divide the Gram matrix by the number of neurons (H * W * C)
Returns:
- gram: Tensor of shape (C, C) giving the (optionally normalized)
Gram matrices for the input image.
"""
shapes = tf.shape(features)
# Reshape feature map from [1, H, W, C] to [H*W, C].
F_l = tf.reshape(features, shape=[shapes[1]*shapes[2],shapes[3]])
# Gram calculation is just a matrix multiply of F_l and F_l transpose to get [C, C] output shape.
gram = tf.matmul(tf.transpose(F_l),F_l)
if normalize == True:
gram /= tf.cast(shapes[1]*shapes[2]*shapes[3],tf.float32)
return gramdef style_loss(feats, style_layers, style_targets, style_weights):
"""
Computes the style loss at a set of layers.
Inputs:
- feats: list of the features at every layer of the current image, as produced by
the extract_features function.
- style_layers: List of layer indices into feats giving the layers to include in the
style loss.
- style_targets: List of the same length as style_layers, where style_targets[i] is
a Tensor giving the Gram matrix the source style image computed at
layer style_layers[i].
- style_weights: List of the same length as style_layers, where style_weights[i]
is a scalar giving the weight for the style loss at layer style_layers[i].
Returns:
- style_loss: A Tensor contataining the scalar style loss.
"""
# Hint: you can do this with one for loop over the style layers, and should
# not be very much code (~5 lines). You will need to use your gram_matrix function.
# Initialise style loss to 0.0 (this makes it a float)
style_loss = tf.constant(0.0)
# Compute style loss for each desired feature layer and then sum.
for i in range(len(style_layers)):
current_im_gram = gram_matrix(feats[style_layers[i]])
style_loss += style_weights[i] * tf.reduce_sum((current_im_gram - style_targets[i])**2)
return style_lossdef tv_loss(img, tv_weight):
"""
Compute total variation loss.
Inputs:
- img: Tensor of shape (1, H, W, 3) holding an input image.
- tv_weight: Scalar giving the weight w_t to use for the TV loss.
Returns:
- loss: Tensor holding a scalar giving the total variation loss
for img weighted by tv_weight.
"""
# Your implementation should be vectorized and not require any loops!
w_variance = tf.reduce_sum((img[:,:,1:,:] - img[:,:,:-1,:])**2)
h_variance = tf.reduce_sum((img[:,1:,:,:] - img[:,:-1,:,:])**2)
loss = tv_weight * (w_variance + h_variance)
return lossdef style_transfer(content_image, style_image, image_size, style_size, content_layer, content_weight,
style_layers, style_weights, tv_weight, init_random = False):
"""Run style transfer!
Inputs:
- content_image: filename of content image
- style_image: filename of style image
- image_size: size of smallest image dimension (used for content loss and generated image)
- style_size: size of smallest style image dimension
- content_layer: layer to use for content loss
- content_weight: weighting on content loss
- style_layers: list of layers to use for style loss
- style_weights: list of weights to use for each layer in style_layers
- tv_weight: weight of total variation regularization term
- init_random: initialize the starting image to uniform random noise
"""
# Extract features from the content image
content_img = preprocess_image(load_image(content_image, size=image_size))
feats = model.extract_features(model.image)
content_target = sess.run(feats[content_layer],
{model.image: content_img[None]})
# Extract features from the style image
style_img = preprocess_image(load_image(style_image, size=style_size))
style_feat_vars = [feats[idx] for idx in style_layers]
style_target_vars = []
# Compute list of TensorFlow Gram matrices
for style_feat_var in style_feat_vars:
style_target_vars.append(gram_matrix(style_feat_var))
# Compute list of NumPy Gram matrices by evaluating the TensorFlow graph on the style image
style_targets = sess.run(style_target_vars, {model.image: style_img[None]})
# Initialize generated image to content image
if init_random:
img_var = tf.Variable(tf.random_uniform(content_img[None].shape, 0, 1), name="image")
else:
img_var = tf.Variable(content_img[None], name="image")
# Extract features on generated image
feats = model.extract_features(img_var)
# Compute loss
c_loss = content_loss(content_weight, feats[content_layer], content_target)
s_loss = style_loss(feats, style_layers, style_targets, style_weights)
t_loss = tv_loss(img_var, tv_weight)
loss = c_loss + s_loss + t_loss
# Set up optimization hyperparameters
initial_lr = 3.0
decayed_lr = 0.1
decay_lr_at = 180
max_iter = 200
# Create and initialize the Adam optimizer
lr_var = tf.Variable(initial_lr, name="lr")
# Create train_op that updates the generated image when run
with tf.variable_scope("optimizer") as opt_scope:
train_op = tf.train.AdamOptimizer(lr_var).minimize(loss, var_list=[img_var])
# Initialize the generated image and optimization variables
opt_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=opt_scope.name)
sess.run(tf.variables_initializer([lr_var, img_var] + opt_vars))
# Create an op that will clamp the image values when run
clamp_image_op = tf.assign(img_var, tf.clip_by_value(img_var, -1.5, 1.5))
f, axarr = plt.subplots(1,2)
axarr[0].axis('off')
axarr[1].axis('off')
axarr[0].set_title('Content Source Img.')
axarr[1].set_title('Style Source Img.')
axarr[0].imshow(deprocess_image(content_img))
axarr[1].imshow(deprocess_image(style_img))
plt.show()
plt.figure()
# Hardcoded handcrafted
for t in range(max_iter):
# Take an optimization step to update img_var
sess.run(train_op)
if t < decay_lr_at:
sess.run(clamp_image_op)
if t == decay_lr_at:
sess.run(tf.assign(lr_var, decayed_lr))
if t % 100 == 0:
print('Iteration {}'.format(t))
img = sess.run(img_var)
plt.imshow(deprocess_image(img[0], rescale=True))
plt.axis('off')
plt.show()
print('Iteration {}'.format(t))
img = sess.run(img_var)
plt.imshow(deprocess_image(img[0], rescale=True))
plt.axis('off')
plt.show()
文章中比較重要的兩個引數就是α與β,這決定了你生成的影象所佔的藝術比重以及內容比重,下圖為作者所示的不同比重的結果:

影象風格轉化是一個典型的卷積神經網路的應用,歡迎各位在評論區探討。