
多類SVM的損失函式
原文:Multi-class SVM Loss
作者: Adrian Rosebrock
翻譯: KK4SBB 責編:何永燦
from: http://geek.csdn.net/news/detail/101547
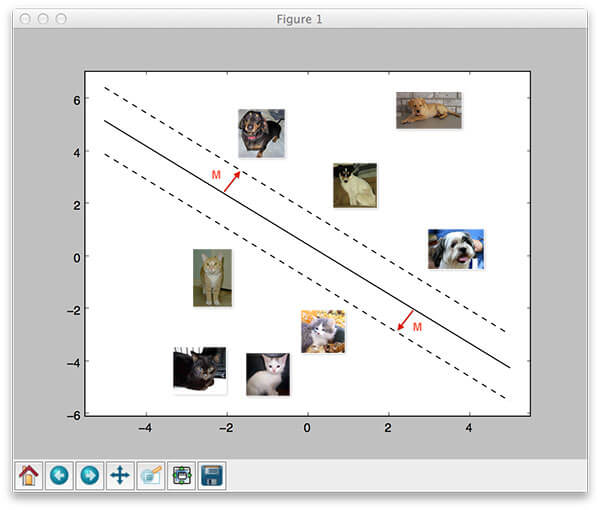
幾個星期之前,我們討論了線性分類和引數化學習的概念。這類學習方法使我們能夠輸入一組資料和類別標籤,然後從中學到一個從輸入值到預測值的對映關係,而我們只需要定義一組引數並優化這些引數。
我們本篇線性分類器教程主要關注評分函式的概念和它的用法。但是,為了真的“學會”輸入值和類別標籤的對映關係,我們需要討論下面兩個重要的概念:
- 損失函式
- 優化方法
在本週和下週的文章中,我們會討論兩類常見的損失函式,它們在機器學習、神經網路和深度學習演算法中都被應用:
- 多類SVM損失
- 交叉熵(用於Softmax分類器/多項式邏輯迴歸)
接下來,我們就討論多類SVM損失。
多類SVM損失
用最簡單的方式來解釋,損失函式就是用來衡量一個預測器在對輸入資料進行分類預測時的質量好壞。
損失值越小,分類器的效果越好,越能反映輸入資料與輸出類別標籤的關係(雖然我們的模型有時候會過擬合——這是由於訓練資料被過度擬合,導致我們的模型失去了泛化能力)。
相反,損失值越大,我們需要花更多的精力來提升模型的準確率。就引數化學習而言,這涉及到調整引數,比如需要調節權重矩陣W或偏置向量B,以提高分類的精度。確切地說,我們如何去更新這些引數屬於優化問題,我們這一系列的教程的後續篇幅將會覆蓋這些話題。
多類SVM損失背後的數學問題
在閱讀完Python的線性分類教程之後,你會發現我們選用的分類器是線性支援向量機(linear SVM)。
上一篇教程著重介紹了評分函式f的概念,它把我們的特徵向量對映為數值型的類別標籤。如其名稱所示,線性SVM採用簡單的線性對映:
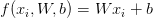
現在我們有了評分/對映函式f,我們需要確定這個函式預測的質量(給定權重矩陣W和偏置向量b)是“好”還是“壞”。
為了完成這一目標,需要定義一個損失函式。接著,我們就來給損失函式下一個定義。
基於之前的線性分類器教程,我們知道當前有一個特徵向量矩陣x —— 這些特徵向量可以從顏色直方圖中獲取,也可以是HOG特徵,或者甚至是原始畫素值。
無論我們如何選擇量化影象,我們都能從影象資料集中抽取出一個特徵矩陣x。然後,我們可以用xi獲取某張圖片的第i維特徵,也就是x的第i個特徵向量。
同樣的,我們也有一個向量y,儲存了每個x的類別標籤。這些y值是我們的參照標籤,正是我們希望評分函式能夠準確預測的標籤值。就像我們可以用xi得到某個特徵向量,我們也可以用yi讀取第i個類別標籤。
為了簡化,我們將評分函式簡寫為s:
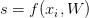
第i個數據的第j類預測得分值可以表示為:

按照上述定義,我們將它代入公式,得到了hinge損失函式:
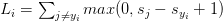
注意:我先故意略過正則化引數項。在後續的文章中,當我們理解了損失函式,我會再來介紹正則化。
那麼,上面那個方程究竟有什麼用途?
我很高興你能提出這樣的問題。
簡單來說,hinge損失函式將預測不正確的類別( )累加,然後將我們評分函式s在第j類(不正確類別)的輸出值與在第yi類的輸出值比較。
)累加,然後將我們評分函式s在第j類(不正確類別)的輸出值與在第yi類的輸出值比較。
然後應用max函式,使得函式的輸出值不小於0 —— 這一點非常重要,因而輸出不會出現負值。
若Li=0,說明給定的資料xi被正確分類了(我在後續的章節中會舉一個例子)。
當把損失值推廣到整個訓練資料集,我們對所有的Li取平均數:
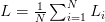
此外,常用的損失函式還有平方hinge損失:

平方項對損失值的懲罰力度更大。
至於選用何種損失函式,這需要視資料集而定。標準的hinge損失函式比較常見,但某些資料集可能使用平方項能取得更好的精度 —— 總之,這是一個需要你交叉驗證的超引數。
多類SVM損失示例
現在,再來討論hinge損失和平方hinge損失的數學原理,以下面的問題為例。
我們再一次選用Kaggle的狗vs.貓資料集,即判斷指定圖片裡包含了貓還是狗。
這個資料集中只包含了兩種可能的類別標籤,因此屬於二分類問題,可以用標準的二項SVM損失函式求解。也就是說,我們仍然使用多類SVM損失,所以我們可以有一個成功實踐的例子。然後,我會擴充套件示例來處理三種類別的問題。
首先,看看下面的圖片,圖片是來自“狗vs.貓”資料集的兩個訓練樣本:

給定任意的權重矩陣W和偏置向量b,f(x,W)=Wx+b函式的輸出分數如上表所示。分數值越大,說明我們的評分函式對預測結果的置信度越高。
我們先來計算“狗”類的損失值Li。假設一個二分類問題,這就非常容易:
>>> max(0, 1.33 - 4.26 + 1)
0
>>>
請注意“狗”的損失值為啥等於零 —— 意思是正確地預測了狗的類別。快速地回顧上述圖1所示的內容:“狗”的分值大於“貓”的分值。
同樣的,我們對第二張影象採取相同的做法,這張圖片包含了一隻貓:
>>> max(0, 3.76 - (-1.2) + 1)
5.96
>>>
損失函式的輸出值大於零,意味著我們的預測結果不正確。
我們計算兩張圖片的損失值的均值作為整體損失值:
>>> (0 + 5.96) / 2
2.98
>>
對於二分類問題,計算過程非常簡單,那對於三分類問題呢?過程會變得複雜嗎?
事實上,並沒有複雜 —— 下圖是一個三類問題的示例,我新加入了一個類別“馬”:

再次計算“狗”這一類的損失值:
>>> max(0, 1.49 - (-0.39) + 1) + max(0, 4.21 - (-0.39) + 1)
8.48
>>>
請注意我們是如何將求和部分擴充套件到兩項計算的 —— 分別計算“狗”類的預測得分與“貓”類和”馬”類分值的差。
同樣的,計算”貓”這一類的損失值:
>>> max(0, -4.61 - 3.28 + 1) + max(0, 1.46 - 3.28 + 1)
0
>>>
最後,計算”馬”這一類的損失值:
>>> max(0, 1.03 - (-2.27) + 1) + max(0, -2.37 - (-2.27) + 1)
5.199999999999999
>>>
因此,整體損失值是:
>>> (8.48 + 0.0 + 5.2) / 3
4.56
>>>
正如你所看到的,它們都適用同樣的原則 —— 只要記住在擴充套件類別數目的同時,求和的項數也要擴充套件。
測驗:根據上面三類的損失值判斷,哪一類是正確的預測值?
我需要動手實現多類SVM損失值計算嗎?
如果你願意,也可以動手實現hinge和平方hinge損失值 —— 但這主要還是出於學習的目的。
你幾乎可以在所有的機器學習/深度學習庫裡找到hinge損失和平方hinge損失的實現,比如scikit-learn, Keras, Caffe等等。
總結
今天我們討論了多類SVM損失的概念。給定一個評分函式(將輸入資料對映到輸出的類別標籤),我們的損失函式可以用來定量評判評分函式預測正確類別標籤質量的“好”與“壞”。
損失值越小,我們的預測越準確(但存在過擬合的風險,對映函式過於擬合了輸入資料)。
相反,損失值越大,我們的預測結果越不準確,因此需要繼續優化引數W和b —— 當我們更深入地理解損失函式之後,後續文章會介紹優化方法。
理解“損失”的概念以及它在機器學習和深度學習演算法中的應用之後,我們仔細研究了兩類損失函式:
- hinge損失函式
- 平方hinge損失函式
通常,hinge損失更常見 —— 但仍然需要調優分類器的超引數來判斷哪種損失函式更適合你的資料集。