
OpenCV訓練自己的人臉檢測級連分類器並測試
0. 概述
分為如下幾步:
step1. 製作訓練資料集
step2. 訓練分類器
step3. 使用分類器進行分類
1. 準備工作
建立一個專案目錄objection_detection/
$ mkdir objection_detection/
$ cd objection_detection/
建立一個訓練資料集目錄train_img_set/用於存放訓練圖片
$ mkdir train_img_set/
下載MIT_Face資料集,並將訓練圖片的face/和non-face/圖片集拷貝到train_img_set/中
MIT_Face下載地址: http://cbcl.mit.edu/software-datasets/FaceData2.html
製作info.dat檔案和bg.txt檔案:
$ cd train_img_set/
$ subl info.dat
$ subl bg.txt
info.dat檔案內容如下(1 表示樣本標籤,0 0 18 18表示在圖片0,0,寬18,長18的矩形型區域):
face/cmu_0000.pgm 1 0 0 18 18
face/cmu_0001.pgm 1 0 0 18 18
face/cmu_0002.pgm 1 0 0 18 18
...
face/cmu_0471.pgm 1 0 0 18 18
bg.txt檔案內容如下, 為了避免路徑錯誤,建議使用絕對路徑:
/Users/liuweijie/workspace/objection_detection/train_img_set/non-face/cmu_0000.pgm /Users/liuweijie/workspace/objection_detection/train_img_set/non-face/cmu_0001.pgm /Users/liuweijie/workspace/objection_detection/train_img_set/non-face/cmu_0002.pgm ... /Users/liuweijie/workspace/objection_detection/train_img_set/non-face/cmu_9999.pgm
生成以上兩個檔案可以通過如下python指令碼實現, 該指令碼放置在train_img_set/目錄下:
#! /usr/local/bin/python import os import cv2 as cv POSTIVE_DIR = 'face/' NEGATIVE_DIR = 'non-face/' INFO_FILENAME = 'info.dat' BG_FILENAME = 'bg.txt' this_dir = os.path.abspath(os.path.dirname(__file__)) postive_url = os.path.join(this_dir, POSTIVE_DIR) negative_url = os.path.join(this_dir, NEGATIVE_DIR) # create info.dat img_list = os.listdir(postive_url) with open(os.path.join(this_dir, INFO_FILENAME), 'wb') as file: for img_name in img_list: img_url = os.path.join(postive_url, img_name) img = cv.imread(img_url) cols, rows = img.shape[:2] file.write(POSTIVE_DIR + img_name + ' 1 0 0 %s %s\n' % (cols - 1, rows - 1)) # create bg.txt img_list = os.listdir(negative_url) with open(os.path.join(this_dir, BG_FILENAME), 'wb') as file: for img_name in img_list: file.write(negative_url + img_name + '\n')
此時準備工作完畢,專案目錄結構如下
objection_detection/
└── train_img_set/
├── face/
│ ├── cmu_0000.pgm
│ ├── ...
│ └── cmu_0471.pgm
├── non-face/
│ ├── cmu_0000.pgm
│ ├── ...
│ └── cmu_9999.pgm
├── info.dat/
├── bg.txt
└── create_info_bg.py
2. 製作訓練資料集
負樣本圖片就是bg.txt描述,不用製作。正類樣本要用opencv_createsamples命令製作
它會從face/中根據info.dat的描述擷取圖片區域,並以*.vec二進位制的形式儲存正樣本訓練集。
這個命令的詳細介紹參考如下:
http://docs.opencv.org/2.4/doc/user_guide/ug_traincascade.html
我們寫成run_create_samples.sh指令碼,放在train_img_set目錄下:
#!/usr/bin/env sh
OUTPUT=./train_set.vec
INFO_FILE=./info.dat
BG_FILE=./bg.txt
NUM=472
WEIGHT=18
HIGHT=18
opencv_createsamples \
-vec $OUTPUT \
-info $INFO_FILE \
-bg $BG_FILE \
-num $NUM \
-show \
-w $WEIGHT \
-h $HIGHT \
執行該指令碼,就會把正樣本的圖片訓練集以二進位制形式儲存在train_set.vec檔案中。
這一步要注意的是NUM, WEIGHT, HIGHT這三個引數,分別是生成的正樣本數量,生成正樣本圖片的寬,高。
3. 訓練分類器
首先在專案目錄objection_detection/下建一個output/目錄來存放訓練結果。
cd ../
$ mkdir output
使用opencv_traincascade命令來進行訓練,該命令的具體可檢視:
http://blog.csdn.net/giantchen547792075/article/details/7404261
我們寫成train_classifier.sh指令碼,放在objection_detection/目錄下:
#!/usr/bin/env sh
OUTPUT_FILE=./output
VEC_FILE=./train_img_set/train_set.vec
BG_FILE=./train_img_set/bg.txt
NUM_POS=47
NUM_NEG=999
NUM_STAGE=10
VAL_BUFSIZE=1024
IDX_BUFSIZE=1024
STAGE_TYPE=BOOST
FEATURE_TYPE=HAAR
# FEATURE_TYPE=LBP
WEIGHT=18
HEIGHT=18
BT=GAB
MIN_HITRATE=0.995
MAX_FALSE_ALARM_RATE=0.05
WEIGHT_TRIM_RATE=0.95
MAX_DEPTH=1
MAX_WEAK_COUNT=100
MODE=BASIC
opencv_traincascade \
-data $OUTPUT_FILE \
-vec $VEC_FILE \
-bg $BG_FILE \
-numPos $NUM_POS \
-numNeg $NUM_NEG \
-numStages $NUM_STAGE \
-precalcValBufSize $VAL_BUFSIZE \
-precalcIdxBufSize $IDX_BUFSIZE \
-stageType $STAGE_TYPE \
-featureType $FEATURE_TYPE \
-w $WEIGHT \
-h $HEIGHT \
-bt $BT \
-minHitRate $MIN_HITRATE \
-maxFalseAlarmRate $MAX_FALSE_ALARM_RATE \
-weightTrimRate $WEIGHT_TRIM_RATE \
-maxDepth $MAX_DEPTH \
-maxWeakCount $MAX_WEAK_COUNT \
-mode $MODE \
# -baseFormatSave \
注意:這裡存在一個bug, 就是-baseFormatSave的話訓練出來的xml格式會錯誤,所以暫且不加,bug報告在這:
http://code.opencv.org/issues/2387
重點關注如下引數:
-data 結果輸出的位置目錄;
-numPos 每一級訓練時用的正樣本數量
-numNeg 每一級訓練時用的負樣本數量
-numStages 級連的級數
-stageType 每一級用什麼分類器
-featureType 每一級選用什麼特徵
-w 圖片的寬,必須與之前一致
-h 圖片的高,必須與之前一致
-bt 訓練方法
-minHitRate 目標每一級的最小真陽率 真陽數/所有正樣本數
-maxFalseAlarmRate 目標每一級的最大勿檢率 假陽數/所有負樣本數
-maxDepth 每一級的最大深度
-maxWeakCount 每一級的最大弱分類器數量
執行該指令碼。
$ chmod 777 train_classifier.sh
$ ./train_classifier.sh
此時就開始訓練,會看到如下內容:
PARAMETERS:
cascadeDirName: ./output
vecFileName: ./train_img_set/train_set.vec
bgFileName: ./train_img_set/bg.txt
numPos: 50
numNeg: 200
numStages: 5
precalcValBufSize[Mb] : 1024
precalcIdxBufSize[Mb] : 1024
acceptanceRatioBreakValue : -1
stageType: BOOST
featureType: HAAR
sampleWidth: 18
sampleHeight: 18
boostType: GAB
minHitRate: 0.995
maxFalseAlarmRate: 0.05
weightTrimRate: 0.95
maxDepth: 1
maxWeakCount: 100
mode: BASIC
===== TRAINING 0-stage =====
<BEGIN
POS count : consumed 50 : 50
NEG count : acceptanceRatio 200 : 1
Precalculation time: 0
+----+---------+---------+
| N | HR | FA |
+----+---------+---------+
| 1| 1| 1|
+----+---------+---------+
| 2| 1| 0.31|
+----+---------+---------+
| 3| 1| 0.31|
+----+---------+---------+
| 4| 1| 0.095|
+----+---------+---------+
| 5| 1| 0.055|
+----+---------+---------+
| 6| 1| 0.055|
+----+---------+---------+
| 7| 1| 0.01|
+----+---------+---------+
END>
Training until now has taken 0 days 0 hours 0 minutes 2 seconds.
===== TRAINING 1-stage =====
...
...
===== TRAINING 4-stage =====
<BEGIN
POS count : consumed 50 : 50
NEG count : acceptanceRatio 200 : 0.000419196
Precalculation time: 0
+----+---------+---------+
| N | HR | FA |
+----+---------+---------+
| 1| 1| 1|
+----+---------+---------+
| 2| 1| 1|
+----+---------+---------+
| 3| 1| 0.35|
+----+---------+---------+
| 4| 1| 0.35|
+----+---------+---------+
| 5| 1| 0.055|
+----+---------+---------+
| 6| 1| 0.04|
+----+---------+---------+
END>
Training until now has taken 0 days 0 hours 0 minutes 34 seconds.
此時在output/目錄下會得到cascade.xml檔案和一些其他中間過程的檔案。cascade.xml就是訓練好的級連分類器,其他中間過程檔案可以刪了。
3. 使用分類器進行分類
在專案目錄下建立一個test_img_set目錄,裡面放一些測試圖片。
在專案目錄下建立test_classifier.py指令碼來使用分類器:
'''
Test the classifier
'''
import numpy as np
import cv2
face_cascade = cv2.CascadeClassifier('./output/cascade.xml')
img = cv2.imread('./test_img_set/big_masters.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
也可以去opencv官方庫下載一些訓練好的xml檔案來,會比自己的效果好很多。

整個專案最終的檔案目錄結構如下
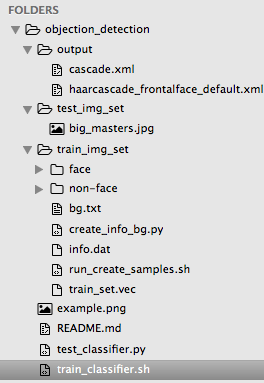
You can download the project from here: