
淺析人臉檢測之Haar分類器方法【牛文強薦】
由於工作需要,我開始研究人臉檢測部分的演算法,這期間斷斷續續地學習Haar分類器的訓練以及檢測過程,在這裡根據各種論文、網路資源的查閱和對程式碼的理解做一個簡單的總結。我試圖概括性的給出演算法的起源、全貌以及細節的來龍去脈,但是水平有限,只能解其大概,希望對初學者起到幫助,更主要的是對我個人學習的一次提煉。
一、Haar分類器的前世今生
人臉檢測屬於計算機視覺的範疇,早期人們的主要研究方向是人臉識別,即根據人臉來識別人物的身份,後來在複雜背景下的人臉檢測需求越來越大,人臉檢測也逐漸作為一個單獨的研究方向發展起來。
目前的人臉檢測方法主要有兩大類:基於知識和基於統計。
“基於知識的方法主要利用先驗知識將人臉看作器官特徵的組合,根據眼睛、眉毛、嘴巴、鼻子等器官的特徵以及相互之間的幾何位置關係來檢測人臉。基於統計的方法則將人臉看作一個整體的模式——二維畫素矩陣,從統計的觀點通過大量人臉影象樣本構造人臉模式空間,根據相似度量來判斷人臉是否存在。在這兩種框架之下,發展了許多方法。目前隨著各種方法的不斷提出和應用條件的變化,將知識模型與統計模型相結合的綜合系統將成為未來的研究趨勢。”(來自論文《基於Adaboost的人臉檢測方法及眼睛定位演算法研究》)
基於知識的人臉檢測方法
Ø 模板匹配
Ø 人臉特徵
Ø 形狀與邊緣
Ø 紋理特性
Ø 顏色特徵
基於統計的人臉檢測方法
Ø 主成分分析與特徵臉
Ø 神經網路方法
Ø 支援向量機
Ø 隱馬爾可夫模型
Ø Adaboost演算法
本文中介紹的Haar分類器方法,包含了Adaboost演算法,稍候會對這一演算法做詳細介紹。所謂分類器,在這裡就是指對人臉和非人臉進行分類的演算法,在機器學習領域,很多演算法都是對事物進行分類、聚類的過程。OpenCV中的ml模組提供了很多分類、聚類的演算法。
注:聚類和分類的區別是什麼?一般對已知物體類別總數的識別方式我們稱之為分類,並且訓練的資料是有標籤的,比如已經明確指定了是人臉還是非人臉,這是一種有監督學習。也存在可以處理類別總數不確定的方法或者訓練的資料是沒有標籤的,這就是聚類,不需要學習階段中關於物體類別的資訊,是一種無監督學習。
其中包括Mahalanobis距離、K均值、樸素貝葉斯分類器、決策樹、Boosting、隨機森林、Haar分類器、期望最大化、K近鄰、神經網路、支援向量機。
我們要探討的Haar分類器實際上是Boosting演算法的一個應用,Haar分類器用到了Boosting演算法中的AdaBoost演算法,只是把AdaBoost演算法訓練出的強分類器進行了級聯,並且在底層的特徵提取中採用了高效率的矩形特徵和積分圖方法,這裡涉及到的幾個名詞接下來會具體討論。
雖說haar分類器採用了Boosting的演算法,但在OpenCV中,Haar分類器與Boosting沒有采用同一套底層資料結構,《Learning OpenCV》中有這樣的解釋:“Haar分類器,它建立了boost篩選式級聯分類器。它與ML庫中其他部分相比,有不同的格局,因為它是在早期開發的,並完全可用於人臉檢測。”
是的,在2001年,Viola和Jones兩位大牛發表了經典的《Rapid Object Detection using a Boosted Cascade of Simple Features》【1】和《Robust Real-Time Face Detection》【2】,在AdaBoost演算法的基礎上,使用Haar-like小波特徵和積分圖方法進行人臉檢測,他倆不是最早使用提出小波特徵的,但是他們設計了針對人臉檢測更有效的特徵,並對AdaBoost訓練出的強分類器進行級聯。這可以說是人臉檢測史上里程碑式的一筆了,也因此當時提出的這個演算法被稱為Viola-Jones檢測器。又過了一段時間,Rainer Lienhart和Jochen Maydt兩位大牛將這個檢測器進行了擴充套件【3】,最終形成了OpenCV現在的Haar分類器。之前我有個誤區,以為AdaBoost演算法就是Viola和Jones搞出來的,因為網上講Haar分類器的地方都在大講特講AdaBoost,所以我錯覺了,後來理清脈絡,AdaBoost是Freund 和Schapire在1995年提出的演算法,是對傳統Boosting演算法的一大提升。Boosting演算法的核心思想,是將弱學習方法提升成強學習演算法,也就是“三個臭皮匠頂一個諸葛亮”,它的理論基礎來自於Kearns 和Valiant牛的相關證明【4】,在此不深究了。反正我是能多簡略就多簡略的把Haar分類器的前世今生說完鳥,得出的結論是,大牛們都是成對兒的。。。額,回到正題,Haar分類器 = Haar-like特徵 + 積分圖方法 + AdaBoost + 級聯;
注:為何稱其為Haar-like?這個名字是我從網上看來的,《Learning OpenCV》中文版提到Haar分類器使用到Haar特徵,但這種說法不確切,應該稱為類Haar特徵,Haar-like就是類Haar特徵的意思。
二、Haar分類器的淺入淺出
之所以是淺入淺出是因為,我暫時深入不能,只是根據其他人的總結,我加以梳理歸納,用自己的理解闡述出來,難免會有錯誤,歡迎指正。
Haar分類器演算法的要點如下:
① 使用Haar-like特徵做檢測。
② 使用積分圖(Integral Image)對Haar-like特徵求值進行加速。
③ 使用AdaBoost演算法訓練區分人臉和非人臉的強分類器。
④ 使用篩選式級聯把強分類器級聯到一起,提高準確率。
2.1 Haar-like特徵你是何方神聖?
一看到Haar-like特徵這玩意兒就頭大的人舉手。好,很多人。那麼我先說下什麼是特徵,我把它放在下面的情景中來描述,假設在人臉檢測時我們需要有這麼一個子視窗在待檢測的圖片視窗中不斷的移位滑動,子視窗每到一個位置,就會計算出該區域的特徵,然後用我們訓練好的級聯分類器對該特徵進行篩選,一旦該特徵通過了所有強分類器的篩選,則判定該區域為人臉。
那麼這個特徵如何表示呢?好了,這就是大牛們乾的好事了。後人稱這他們搞出來的這些東西叫Haar-Like特徵。
下面是Viola牛們提出的Haar-like特徵。
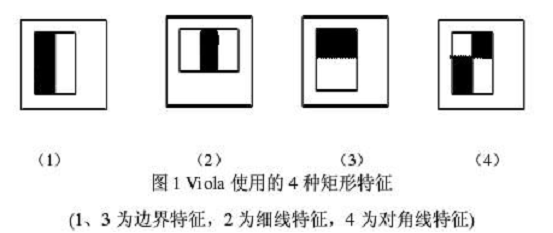
下面是Lienhart等牛們提出的Haar-like特徵。
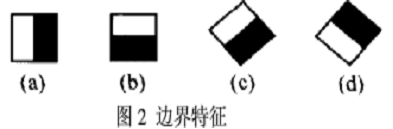
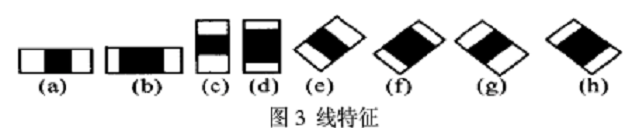
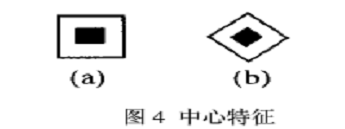
這些所謂的特徵不就是一堆堆帶條紋的矩形麼,到底是幹什麼用的?我這樣給出解釋,將上面的任意一個矩形放到人臉區域上,然後,將白色區域的畫素和減去黑色區域的畫素和,得到的值我們暫且稱之為人臉特徵值,如果你把這個矩形放到一個非人臉區域,那麼計算出的特徵值應該和人臉特徵值是不一樣的,而且越不一樣越好,所以這些方塊的目的就是把人臉特徵量化,以區分人臉和非人臉。
為了增加區分度,可以對多個矩形特徵計算得到一個區分度更大的特徵值,那麼什麼樣的矩形特徵怎麼樣的組合到一塊可以更好的區分出人臉和非人臉呢,這就是AdaBoost演算法要做的事了。這裡我們先放下積分圖這個概念不管,為了讓我們的思路連貫,我直接開始介紹AdaBoost演算法。
2.2 AdaBoost你給我如實道來!
本節旨在介紹AdaBoost在Haar分類器中的應用,所以只是描述了它在Haar分類器中的特性,而實際上AdaBoost是一種具有一般性的分類器提升演算法,它使用的分類器並不侷限某一特定演算法。
上面說到利用AdaBoost演算法可以幫助我們選擇更好的矩陣特徵組合,其實這裡提到的矩陣特徵組合就是我們之前提到的分類器,分類器將矩陣組合以二叉決策樹的形式儲存起來。
我現在腦子裡浮現了很多問題,總結起來大概有這麼些個:
v 弱分類器和強分類器是什麼?
v 弱分類器是怎麼得到的?
v 強分類器是怎麼得到的?
v 二叉決策樹是什麼?
要回答這一系列問題,我得跟你羅嗦一會兒了,這得從AdaBoost的身世說起。
2.2.1 AdaBoost的身世之謎
關於AdaBoost的身世,我把相關英文文獻從上世紀80年代一直下到2001年,我發現我在短時間內沒法讀完,所以我只能嘗試著從別人的總結中拼湊那些離散的片段,難免有誤。
之前講Haar分類器的前世今生也簡單說過AdaBoost的身世,但是說的還不透。我比較喜歡查演算法的戶口,所以新寫了一章查了下去。
AdaBoost的老祖宗可以說是機器學習的一個模型,它的名字叫PAC(Probably Approximately Correct)。
PAC模型是計算學習理論中常用的模型,是Valiant牛在我還沒出生的1984年提出來的【5】,他認為“學習"是模式明顯清晰或模式不存在時仍能獲取知識的一種“過程”,並給出了一個從計算角度來獲得這種“過程"的方法,這種方法包括:
(1)適當資訊收集機制的選擇;
(2)學習的協定;
(3)對能在合理步驟內完成學習的概念的分類。
PAC學習的實質就是在樣本訓練的基礎上,使演算法的輸出以概率接近未知的目標概念。PAC學習模型是考慮樣本複雜度(指學習器收斂到成功假設時至少所需的訓練樣本數)和計算複雜度(指學習器收斂到成功假設時所需的計算量)的一個基本框架,成功的學習被定義為形式化的概率理論。(來自論文《基於Adaboost的人臉檢測方法及眼睛定位演算法研究》)
簡單說來,PAC學習模型不要求你每次都正確,只要能在多項式個樣本和多項式時間內得到滿足需求的正確率,就算是一個成功的學習。
基於PAC學習模型的理論分析,Valiant牛提出了Boosting演算法【5】,Boosting演算法涉及到兩個重要的概念就是弱學習和強學習,所謂的弱學習,就是指一個學習演算法對一組概念的識別率只比隨機識別好一點,所謂強學習,就是指一個學習演算法對一組概率的識別率很高。現在我們知道所謂的弱分類器和強分類器就是弱學習演算法和強學習演算法。弱學習演算法是比較容易獲得的,獲得過程需要數量巨大的假設集合,這個假設集合是基於某些簡單規則的組合和對樣本集的效能評估而生成的,而強學習演算法是不容易獲得的,然而,Kearns 和Valiant 兩頭牛提出了弱學習和強學習等價的問題 【6】 並證明了只要有足夠的資料,弱學習演算法就能通過整合的方式生成任意高精度的強學習方法。這一證明使得Boosting有了可靠的理論基礎,Boosting演算法成為了一個提升分類器精確性的一般性方法。【4】
1990年,Schapire牛提出了第一個多項式時間的演算法【7】,1年後Freund牛又提出了一個效率更高的Boosting演算法【8】。然而,Boosting演算法還是存在著幾個主要的問題,其一Boosting演算法需要預先知道弱學習演算法學習正確率的下限即弱分類器的誤差,其二Boosting演算法可能導致後來的訓練過分集中於少數特別難區分的樣本,導致不穩定。針對Boosting的若干缺陷,Freund和Schapire牛於1996年前後提出了一個實際可用的自適應Boosting演算法AdaBoost【9】,AdaBoost目前已發展出了大概四種形式的演算法,Discrete AdaBoost(AdaBoost.M1)、Real AdaBoost、LogitBoost、gentle AdaBoost,本文不做一一介紹。至此,AdaBoost的身世之謎就這樣揭開鳥。同時弱分類器和強分類器是什麼的問題也解釋清楚了。剩下3個問題,我們先看一下,弱分類器是如何得到的。
2.2.2 弱分類器的孵化
最初的弱分類器可能只是一個最基本的Haar-like特徵,計算輸入影象的Haar-like特徵值,和最初的弱分類器的特徵值比較,以此來判斷輸入影象是不是人臉,然而這個弱分類器太簡陋了,可能並不比隨機判斷的效果好,對弱分類器的孵化就是訓練弱分類器成為最優弱分類器,注意這裡的最優不是指強分類器,只是一個誤差相對稍低的弱分類器,訓練弱分類器實際上是為分類器進行設定的過程。至於如何設定分類器,設定什麼,我們首先分別看下弱分類器的數學結構和程式碼結構。
² 數學結構

一個弱分類器![]() 由子視窗影象x,一個特徵f,指示不等號方向的p和閾值
由子視窗影象x,一個特徵f,指示不等號方向的p和閾值![]() 組成。P的作用是控制不等式的方向,使得不等式都是<號,形式方便。
組成。P的作用是控制不等式的方向,使得不等式都是<號,形式方便。
² 程式碼結構
 1 /* 2 * CART classifier
1 /* 2 * CART classifier3 */
4 typedef struct CvCARTHaarClassifier
5 {
6 CV_INT_HAAR_CLASSIFIER_FIELDS()
7 int count;
8 int* compidx;
9 CvTHaarFeature* feature;
10 CvFastHaarFeature* fastfeature;
11 float* threshold;
12 int* left;
13 int* right;
14 float* val;
15 } CvCARTHaarClassifier;
程式碼結構中的threshold即代表數學結構中的![]() 閾值。
閾值。
這個閾值究竟是幹什麼的?我們先了解下CvCARTHaarClassifier這個結構,注意CART這個詞,它是一種二叉決策樹,它的提出者Leo Breiman等牛稱其為“分類和迴歸樹(CART)”。什麼是決策樹?我如果細講起來又得另起一章,我只簡略介紹它。
“機器學習中,決策樹是一個預測模型;他代表的是物件屬性與物件值之間的一種對映關係。樹中每個節點表示某個物件,而每個分叉路徑則代表的某個可能的屬性值,而每個葉結點則對應從根節點到該葉節點所經歷的路徑所表示的物件的值。決策樹僅有單一輸出,若欲有複數輸出,可以建立獨立的決策樹以處理不同輸出。從資料產生決策樹的機器學習技術叫做決策樹學習, 通俗說就是決策樹。”(來自《維基百科》)
決策樹包含:分類樹,迴歸樹,分類和迴歸樹(CART),CHAID 。
分類和迴歸的區別是,分類是當預計結果可能為兩種型別(例如男女,輸贏等)使用的概念。 迴歸是當局域結果可能為實數(例如房價,患者住院時間等)使用的概念。
決策樹用途很廣可以分析因素對事件結果的影響(詳見維基百科),同時也是很常用的分類方法,我舉個最簡單的決策樹例子,假設我們使用三個Haar-like特徵f1,f2,f3來判斷輸入資料是否為人臉,可以建立如下決策樹:
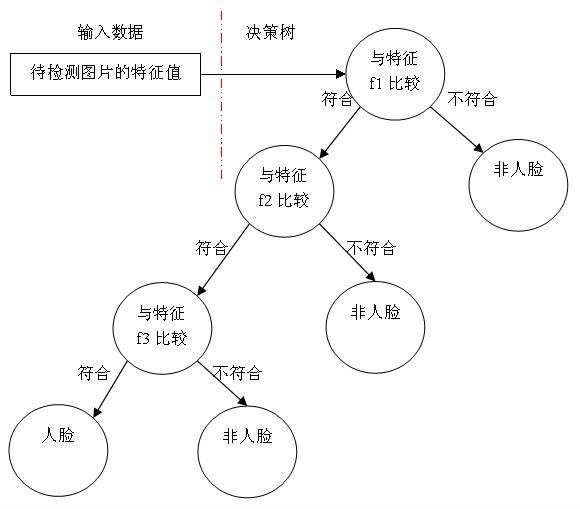
可以看出,在分類的應用中,每個非葉子節點都表示一種判斷,每個路徑代表一種判斷的輸出,每個葉子節點代表一種類別,並作為最終判斷的結果。
一個弱分類器就是一個基本和上圖類似的決策樹,最基本的弱分類器只包含一個Haar-like特徵,也就是它的決策樹只有一層,被稱為樹樁(stump)。
最重要的就是如何決定每個結點判斷的輸出,要比較輸入圖片的特徵值和弱分類器中特徵,一定需要一個閾值,當輸入圖片的特徵值大於該閾值時才判定其為人臉。訓練最優弱分類器的過程實際上就是在尋找合適的分類器閾值,使該分類器對所有樣本的判讀誤差最低。
具體操作過程如下:
1)對於每個特徵 f,計算所有訓練樣本的特徵值,並將其排序。
掃描一遍排好序的特徵值,對排好序的表中的每個元素,計算下面四個值:
全部人臉樣本的權重的和t1;
全部非人臉樣本的權重的和t0;
在此元素之前的人臉樣本的權重的和s1;
在此元素之前的非人臉樣本的權重的和s0;
2)最終求得每個元素的分類誤差![]()
在表中尋找r值最小的元素,則該元素作為最優閾值。有了該閾值,我們的第一個最優弱分類器就誕生了。
在這漫長的煎熬中,我們見證了一個弱分類器孵化成長的過程,並回答瞭如何得到弱分類器以及二叉決策樹是什麼。最後的問題是強分類器是如何得到的。
2.2.3 弱分類器的化蝶飛
首先看一下強分類器的程式碼結構:
1 /* internal stage classifier */2 typedef struct CvStageHaarClassifier
3 {
4 CV_INT_HAAR_CLASSIFIER_FIELDS()
5 int count;
6 float threshold;
7 CvIntHaarClassifier** classifier;
8 }CvStageHaarClassifier;
/* internal weak classifier*/typedef struct CvIntHaarClassifier
{
CV_INT_HAAR_CLASSIFIER_FIELDS()
} CvIntHaarClassifier; 這裡要提到的是CvIntHaarClassifier結構: 它就相當於一個介面類,當然是用C語言模擬的面向物件思想,利用CV_INT_HAAR_CLASSIFIER_FIELDS()這個巨集讓弱分類CvCARTHaarClassifier強分類器和CvStageHaarClassifier繼承於CvIntHaarClassifier。
強分類器的誕生需要T輪的迭代,具體操作如下:
1. 給定訓練樣本集S,共N個樣本,其中X和Y分別對應於正樣本和負樣本; T為訓練的最大迴圈次數;
2. 初始化樣本權重為1/N ,即為訓練樣本的初始概率分佈;
3. 第一次迭代訓練N個樣本,得到第一個最優弱分類器,步驟見2.2.2節
4. 提高上一輪中被誤判的樣本的權重;
5. 將新的樣本和上次本分錯的樣本放在一起進行新一輪的訓練。
6. 迴圈執行4-5步驟,T輪後得到T個最優弱分類器。
7.組合T個最優弱分類器得到強分類器,組合方式如下:
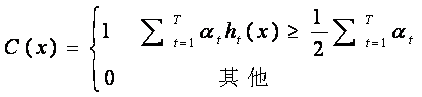
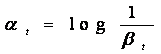
相當於讓所有弱分類器投票,再對投票結果按照弱分類器的錯誤率加權求和,將投票加權求和的結果與平均投票結果比較得出最終的結果。
至此,我們看到其實我的題目起的漂亮卻並不貼切,強分類器的脫穎而出更像是民主的投票制度,眾人拾材火焰高,強分類器不是個人英雄主義的的產物,而是團結的力量。但從巨集觀的局外的角度看,整個AdaBoost演算法就是一個弱分類器從孵化到化蝶的過程。小人物的奮鬥永遠是理想主義者們津津樂道的話題。但暫時讓我們放下AdaBoost繼續探討Haar分類器的其他特性吧。
2.3 強分類器的強強聯手
至今為止我們好像一直在講分類器的訓練,實際上Haar分類器是有兩個體系的,訓練的體系,和檢測的體系。訓練的部分大致都提到了,還剩下最後一部分就是對篩選式級聯分類器的訓練。我們看到了通過AdaBoost演算法辛苦的訓練出了強分類器,然而在現實的人臉檢測中,只靠一個強分類器還是難以保證檢測的正確率,這個時候,需要一個豪華的陣容,訓練出多個強分類器將它們強強聯手,最終形成正確率很高的級聯分類器這就是我們最終的目標Haar分類器。
那麼訓練級聯分類器的目的就是為了檢測的時候,更加準確,這涉及到Haar分類器的另一個體系,檢測體系,檢測體系是以現實中的一幅大圖片作為輸入,然後對圖片中進行多區域,多尺度的檢測,所謂多區域,是要對圖片劃分多塊,對每個塊進行檢測,由於訓練的時候用的照片一般都是20*20左右的小圖片,所以對於大的人臉,還需要進行多尺度的檢測,多尺度檢測機制一般有兩種策略,一種是不改變搜尋視窗的大小,而不斷縮放圖片,這種方法顯然需要對每個縮放後的圖片進行區域特徵值的運算,效率不高,而另一種方法,是不斷初始化搜尋視窗size為訓練時的圖片大小,不斷擴大搜索視窗,進行搜尋,解決了第一種方法的弱勢。在區域放大的過程中會出現同一個人臉被多次檢測,這需要進行區域的合併,這裡不作探討。
無論哪一種搜尋方法,都會為輸入圖片輸出大量的子視窗影象,這些子視窗影象經過篩選式級聯分類器會不斷地被每一個節點篩選,拋棄或通過。
它的結構如圖所示。
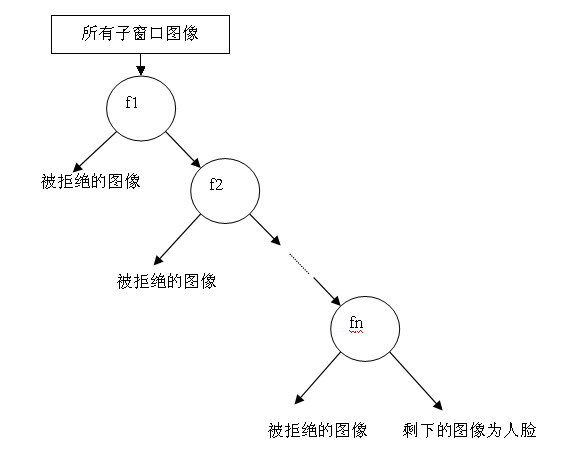
我想你一定覺得很熟悉,這個結構不是很像一個簡單的決策樹麼。
在程式碼中,它的結構如下:
1 /* internal tree cascade classifier node */2 typedef struct CvTreeCascadeNode
3 {
4 CvStageHaarClassifier* stage;
5 struct CvTreeCascadeNode* next;
6 struct CvTreeCascadeNode* child;
7 struct CvTreeCascadeNode* parent;
8 struct CvTreeCascadeNode* next_same_level;
9 struct CvTreeCascadeNode* child_eval;
10 int idx;
11 int leaf;
12 } CvTreeCascadeNode;
13 /* internal tree cascade classifier */
14 typedef struct CvTreeCascadeClassifier
15 {
16 CV_INT_HAAR_CLASSIFIER_FIELDS()
17 CvTreeCascadeNode* root; /* root of the tree */
18 CvTreeCascadeNode* root_eval;
相關推薦
淺析人臉檢測之Haar分類器方法【牛文強薦】
由於工作需要,我開始研究人臉檢測部分的演算法,這期間斷斷續續地學習Haar分類器的訓練以及檢測過程,在這裡根據各種論文、網路資源的查閱和對程式碼的理解做一個簡單的總結。我試圖概括性的給出演算法的起源、全貌以及細節的來龍去脈,但是水平有限,只能解其大概,希望對初學者起到
淺析人臉檢測之Haar分類器方法
一、Haar分類器的前世今生 人臉檢測屬於計算機視覺的範疇,早期人們的主要研究方向是人臉識別,即根據人臉來識別人物的身份,後來在複雜背景下的人臉檢測需求越來越大,人臉檢測也逐漸作為一個單獨的研究方向發展起來。 目前的人臉檢測方法主要有兩大類:基於知識和基於統計。 “基於
第九節、人臉檢測之Haar分類器
白色 har cas 詳情 大小 一次 水平 分類 需求 人臉檢測屬於計算機視覺的範疇,早期人們的主要研究方向是人臉識別,即根據人臉來識別人物的身份,後來在復雜背景下的人臉檢測需求越來越大,人臉檢測也逐漸作為一個單獨的研究方向發展起來。 目前人臉檢測的方法主要有兩大類:基於
【OpenCV筆記 16-2】OpenCV人臉檢測和人眼檢測之LBP分類器
//LBP檢測器的運用 //本程式可以執行,用於人臉識別和人眼識別 #include<opencv2/opencv.hpp> #include <iostream> using namespace std; using namespace cv; CascadeClassif
OpenCV訓練自己的人臉檢測級連分類器並測試
0. 概述 分為如下幾步: step1. 製作訓練資料集 step2. 訓練分類器 step3. 使用分類器進行分類 1. 準備工作 建立一個專案目錄objection_detection/ $ mkdir objection_detecti
opencv人臉檢測_Haar特徵分類器實現人臉檢測_cascade.detectMultiScale引數詳解
1. 概述 CascadeClassifier為OpenCV中cv namespace下用來做目標檢測的級聯分類器的一個類。該類中封裝的目標檢測機制,簡而言之是滑動視窗機制+級聯分類器的方式 2. 支援的特徵 對於Haar、LBP和HOG,CascadeClas
OpenCVForUnity使用Haar分類器檢測人臉和眼睛
Github上有許多已經訓練好的分類器,可以直接拿來試用。 void Start() { //訓練集路徑 haarcascade_frontalface_default_xml_filepath = Application.dataPa
人臉檢測(Haar特徵+Adaboost級聯分類器)
一、Haar分類器的前世今生 人臉檢測屬於計算機視覺的範疇,早期人們的主要研究方向是人臉識別,即根據人臉來識別人物的身份,後來在複雜背景下的人臉檢測需求越來越大,人臉檢測也逐漸作為一個單獨的研究方向發展起來。 目前的人臉檢測方法主要有兩大類:基於知識和基於統計。 “
HAAR與DLib的實時人臉檢測之實現與對比
人臉檢測方法有許多,比如opencv自帶的人臉Haar特徵分類器和dlib人臉檢測方法等。 對於opencv的人臉檢測方法,優點是簡單,快速;存在的問題是人臉檢測效果不好。正面/垂直/光線較好的人臉,該方法可以檢測出來,而側面/歪斜/光線不好的人臉,無法檢測。因此,該方法不適合現場應用。而對於dlib人臉檢
OpenCV學習記錄(一):使用haar分類器進行人臉識別
https://blog.csdn.net/hongbin_xu/article/details/74202193 OpenCV支援的目標檢測的方法是利用樣本的Haar特徵進行的分類器訓練,得到的級聯boosted分類器(Cascade Classification)。
使用adaboost+haar分類器檢測車輛demo
程式碼如下 #include <iostream> #include <opencv2/opencv.hpp> #include <string> using na
Haar分類器(人臉識別、人眼識別)
一、Haar分類器的前世今生 人臉檢測屬於計算機視覺的範疇,早期人們的主要研究方向是人臉識別,即根據人臉來識別人物的身份,後來在複雜背景下的人臉檢測需求越來越大,人臉檢測也逐漸作為一個單獨的研究方向發展起來。 目前的人臉檢測方法主要有兩大類:基於知識和基
人臉檢測之face_recognition演算法除錯
參考:https://github.com/ageitgey/face_recognition 公司專案需求,要出一個人臉檢測與識別的demo,檢視網上比較成熟的是face_recognition方案,因此在電腦上按照推薦步驟進行除錯。face_recognition使用dlib最先進的面部
分類器設計之線性分類器和線性SVM(含Matlab程式碼)
對於高維空間的兩類問題,最直接的方法是找到一個最佳的分類超平面,使得並且,對於所有的正負訓練樣本和. 因此,以上問題可以表達為: 問題P0可以轉化為 兩邊除以\epsilon,並且做變數替換,最終得到下面的線性規化(linear programming
隨想錄(人臉檢測之dlib)
【 宣告:版權所有,歡迎轉載,請勿用於商業用途。 聯絡信箱:feixiaoxing @163.com】 opencv大家用的很多,但是opencv的效率實在不敢恭維。所以,大家開始慢慢尋找其他的一些開源庫,dlib就是不錯的一個選擇。當然,ope
機器學習之XGBoost分類器XGBClassifier-- xgb使用sklearn介面
機器學習之XGBoost分類器XGBClassifier # -*- coding: utf-8 -*- """ Created on Tue Dec 4 20:48:14 2018 @author: muli """ ''' xgb使用sklearn介面
sklean學習之LogisticRegression(邏輯斯蒂迴歸分類器)【原始碼】
def fit(self, X, y, sample_weight=None): """根據給定的訓練資料擬合模型. 引數 ---------- X : {array-like, sparse matrix}, shape (n_samples, n_fe
keras系列︱人臉表情分類與識別:opencv人臉檢測+Keras情緒分類(四)
人臉識別熱門,表情識別更加。但是表情識別很難,因為人臉的微表情很多,本節介紹一種比較粗線條的表情分類與識別的辦法。 Keras系列: 本次講述的表情分類是識別的分析流程分為:
機器學習之線性分類器(Linear Classifiers)——腫瘤預測例項
線性分類器:一種假設特徵與分類結果存線上性關係的模型。該模型通過累加計算每個維度的特徵與各自權重的乘積來幫助決策。 # 匯入pandas與numpy工具包。 import pandas as pd import numpy as np # 建立特徵列表。 column_n
人臉檢測之MTCNN程式碼實現
上一篇部落格介紹了MTCNN網路的原理,這篇部落格介紹一個程式碼的實現。 對應的MTCNN網路目前也有寫好的程式碼,大家可以在程式碼連結 上下載程式碼,然後進行識別。對於下載後的程式碼主要有以下的說明。 1. 該程式碼中的包含了已經訓練好的模型,模型的資料儲存在.npy檔