
Ng深度學習筆記 1-線性迴歸、監督學習、成本函式、梯度下降
阿新 • • 發佈:2019-01-08
他講了監督學習的兩類問題,分類和迴歸,並引入了兩個例子。一個講用現有的房屋面積和房價的資料集推算任意房子的價格(可認為是連續的),然後再引入其他模型引數,比如臥室個數等。另一個講用腫瘤的大小來推斷是否為良性或惡性腫瘤,如果引入其他引數,比如腫瘤細胞大小的一致性,及細胞形狀的一致性等,依然可以找出這種關係,其結果是離散的(在其他問題中,可能分多於兩個類,但依然是離散結果,是分類問題)。總之,兩類問題都是根據已知的資料(引數值和輸出)來推算尚未知輸入的輸出,這也就是監督學習的直觀理解。
設計不同的模型來研究現實世界中的問題,引入更多的引數讓該模型更趨近真實情形,這可能就是工程師看世界的角度吧。有人做過北京租房價格的統計, ->戳post,可以在這個基礎上學習一個房價模型(應該鏈家、麥田早就有他們的定價模型吧),現實情況往往復雜很多,鏈家員工去挨家挨戶統計真實住房資訊得磨斷多少腿?->戳video
Cost Function
線上性問題中,模型是這樣表示的,
在調整引數的時候,介紹了梯度下降的方法。求偏導部分讀者自行推導一下。
Gradient Descent
這裡
有兩個變數的時候,
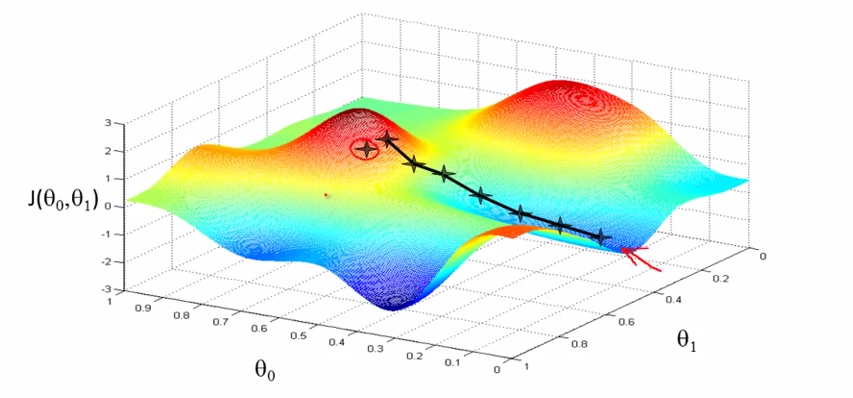
圖中的每個十字是一次迭代計算。每一次迭代的時候好比從該十字向周圍嗅探,去哪兒會降低
Vectorized Implementation
線性迴歸的成本函式向量化表達為下式:
故,