
評分卡模型開發--總體流程
一、信用風險評級模型的型別
信用風險計量體系包括主體評級模型和債項評級兩部分。主體評級和債項評級均有一系列評級模型組成,其中主體評級模型可用“四張卡”來表示,分別是A卡、B卡、C卡和F卡;債項評級模型通常按照主體的融資用途,分為企業融資模型、現金流融資模型和專案融資模型等。
A卡,又稱為申請者評級模型,主要應用於相關融資類業務中新使用者的主體評級,適用於個人和機構融資主體。
B卡,又稱為行為評級模型,主要應用於相關融資類業務中存量客戶在續存期內的管理,如對客戶可能出現的逾期、延期等行為進行預測,僅適用於個人融資主體。
C卡,又稱為催收評級模型,主要應用於相關融資類業務中存量客戶是否需要催收的預測管理,僅適用於個人融資主體。
F卡,又稱為欺詐評級模型,主要應用於相關融資類業務
我們主要討論主體評級模型的開發過程。
二、信用風險評級模型開發流程概述
典型的評級模型開發流程如圖2.1所示。該流程中各個步驟的順序可根據具體情況的不同進行適當調整,也可以根據需要重複某些步驟。
信用風險評級模型的主要開發流程如下:
(1) 資料獲取,包括獲取存量客戶及潛在客戶的資料。存量客戶是指已經在證券公司開展相關融資類業務的客戶,包括個人客戶和機構客戶;潛在客戶是指未來擬在證券公司開展相關融資類業務的客戶,主要包括機構客戶,這也是解決證券業樣本較少的常用方法,這些潛在機構客戶包括上市公司、公開發行債券的發債主體、新三板上市公司、區域股權交易中心掛牌公司、非標融資機構等。
(2) EDA(探索性資料分析)與資料描述,該步驟主要是獲取樣本總體的大概情況,以便制定樣本總體的資料預處理方法。描述樣本總體情況的指標主要有缺失值情況、異常值情況、平均值、中位數、最大值、最小值、分佈情況等。
(3) 資料預處理,主要工作包括資料清洗、缺失值處理、異常值處理,主要是為了將獲取的原始資料轉化為可用作模型開發的格式化資料。
(4) 變數選擇,該步驟主要是通過統計學的方法,篩選出對違約狀態影響最顯著的指標。
(5) 模型開發,該步驟主要包括變數分段、變數的WOE(證據權重)變換和邏輯迴歸估算三部分。
(6) 主標尺與模型驗證,該步驟主要是開發某類主體的主標尺並進行模型的驗證與校準。
(7) 模型評估,該步驟主要是根據模型驗證和主標尺設計的結果,評估模型的區分能力、預測能力、穩定性,並形成模型評估報告,得出模型是否可以使用的結論。
(8) 模型實施,即模型的部署和應用。
(9) 監測與報告,該步驟主要工作是定期檢測模型的使用情況,並關注和定期檢驗模型的區分能力與預測能力的變化及模型穩定性的變化,在出現模型可能不能滿足業務需求的情況時,反饋至模型開發團隊,及時進行模型更新或重新開發。
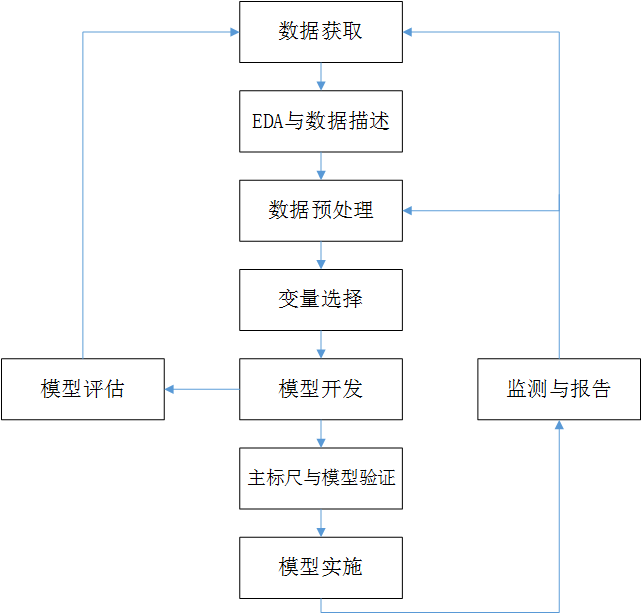
圖2.1 評級模型開發流程
三、基於Logistic迴歸的標準評分卡模型開發實現
3.1 明確要解決的問題
在開發信用風險評級模型(包括個人和機構)之前,首先要明確我們需要解決的問題。因為,個人信用風險評級模型包括申請者評級、行為評級、催收評級、欺詐評級等幾類,開發每一類評級模型所需要的資料也是不同的,例如開發個人申請者評級模型需要的是個人客戶申請融資類業務時提交的資料,開發個人行為評級模型需要的是存量個人客戶的歷史行為資料,這兩部分資料及需要解決的問題,也存在較大的差異。因此,在開發信用風險評級模型之前,我們需要明確開發模型的型別。此處以開發個人客戶的申請者評級模型為例,來詳細講述此類模型的開發過程。
開發申請者評分模型所需要的資料是個人客戶申請融資類業務時所需的資料,包括反映個人還款意願的定性資料,應用申請者評分模型的目的是預測該申請客戶在未來一段時間發生違約的概率。
我們做預測模型的一個基本原理是用歷史資料來預測未來,申請者評分模型需要解決的問題是未來一段時間(如12個月)融資人出現違約(如至少一次90天或90天以上逾期)的概率。在這個需求中,“未來一段時間”為表現時間視窗(performance window),“融資人出現至少一次90天或90天以上逾期”為觀察時間視窗(sample window)。個人主體的違約跟個人行為習慣有很大的相關性,因此我們可以通過分析個人樣本總體中客戶的歷史我違約頻率來確定表現時間視窗和觀察時間視窗。這兩個視窗的確定對於我們要解決的問題,有著非常重要的影響,我們將放在第二步中結合具體的資料來分析,並講述具體的確定方法。
3.2 資料描述和探索性資料分析
資料準備和資料預處理是整個信用風險模型開發過程中最重要也是最耗時的工作了。通常情況下,資料準備和資料預處理階段消耗的時間佔整個模型開發時間的80%以上,該階段主要的工作包括資料獲取、探索性資料分析、缺失值處理、資料校準、資料抽樣、資料轉換,還包括離散變數的降維、連續變數的優先分段等工作。
明確了要解決的問題後,接下來我們就要蒐集相關的資料了。此處,我們以網際網路上經常被用來研究信用風險評級模型的加州大學機器學習資料庫中的german credit data為例,來詳細講述個人客戶信用風險評級模型的開發方法。
German credit data 的資料來自”klaR”包
install.packages(“klaR”)
library(“klaR”)
data(GermanCredit)
View(GermanCredit) #檢視該資料集
- 1
- 2
- 3
- 4
- 5
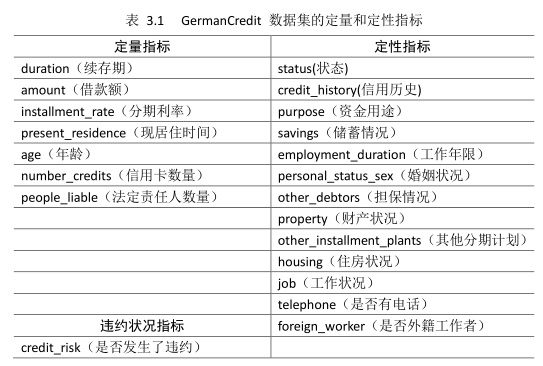
該資料集包含了1000個樣本,每個樣本包括了21個變數(屬性),其中包括1個違約狀態變數“credit_risk”,剩餘20個變數包括了所有的定量和定性指標,分別如表3.1所示。
接下來,我們需要檢查資料的質量,主要包括缺失值情況、異常值情況及其他處理方法。缺失值和異常值處理的基本原則是處理前後的分佈總體保持一致。
3.21 使用者資料的缺失值處理:
http://blog.csdn.net/lll1528238733/article/details/76599626
3.22 使用者資料的異常值處理:
http://blog.csdn.net/lll1528238733/article/details/76599792
需要特別說明的是,在實際的樣本蒐集和資料預處理中,我們應該首先對個人客戶的違約做出定義,並根據對違約的定義對蒐集的樣本進行必要的校準。一般情況下,我們蒐集的資料為非標準化的資料,如表3.2所示,該表中假設蒐集的是前10個客戶在兩年內的歷史違約情況。
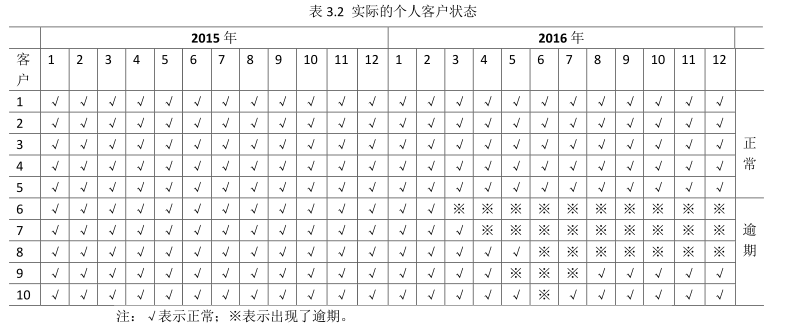
在表3.2所示的資料集中,如果我們假設連續出現三個月逾期可被定義為違約,則客戶6至客戶9可被確認為違約。然而,為了明確違約的概念,我們還需要確定基準時間和觀察時間視窗。如果當前時間是2016年7月末,則只有6和7兩個客戶為違約,其他客戶均屬於正常客戶,如果當前時間是2016年9月末,則只有6、7、8三個客戶為違約,客戶9已經自愈,則再次變成正常客戶。
結合上述分析,在明確評分卡要解決的實際問題時,還應該確定表現時間視窗和觀察時間視窗,而這兩個視窗的確定,需要根據我們蒐集的資料來具體確定。他們的確定方法,分別如下:
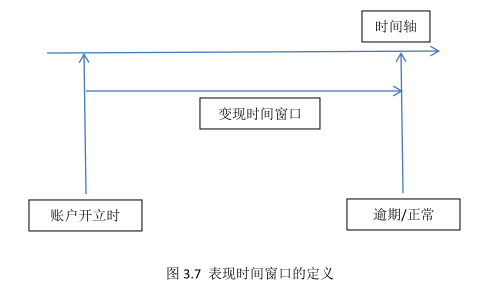
在確定變現時間視窗的長度時,我們通常需要客戶從開始開立融資類業務時到最近時間點(或至少兩年以上的歷史逾期情況)的逾期表現,用圖形表示,如圖3.7所示。
按照圖3.7所示的表現時間視窗的定義方法,我們對樣本總體進行統計分析,以逾期90天定義為違約,會得出表3.3所示的統計結果。
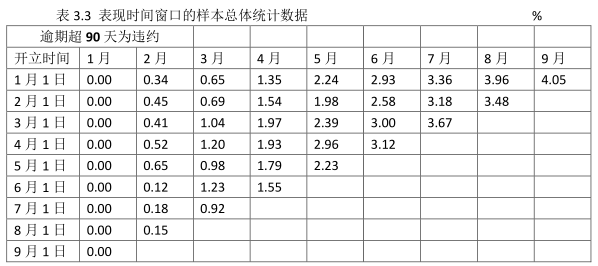
表3.3中8月最後一列資料3.48%表示,2.1日開立的所有賬戶中,8個月後出現逾期90天以上的賬戶佔樣本的比重為3.48%。我們通過這樣統計方法,並繪製樣本總體的違約狀態變化曲線,即可得到如圖3.8所示的曲線。從圖3.8所示的曲線中我們可以看出,在賬戶開立第11個月到第13個月時,客戶的違約狀態達到穩定狀態,曲線變得非常平穩。此時,我們可以確定評分卡的表現時間視窗為11個月到13個月,即我們將違約狀態變得穩定的時間段確定為表現時間視窗。這種方法可使我們開發的評分卡模型的區分能力和預測能力準確性均達到最優穩定狀態。
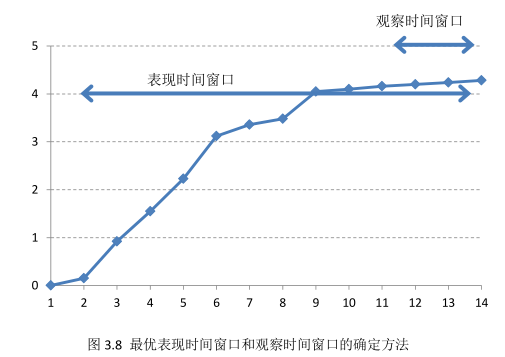
由圖3.8的曲線可以看出,客戶開立融資類業務的賬戶的起始階段發生違約的頻率是不斷增多的,但隨著時間的推移發生違約的客戶的佔比處於穩定狀態。那麼,我們在開發信用風險評分卡模型時,需要選擇客戶違約處於穩定狀態的時間點來作為最優表現時間視窗,這樣既可以最大限度地降低模型的不穩定性,也可以避免低估最終的違約樣本的比率。例如,當我們選擇表現時間視窗為6個月時,樣本總體中的違約樣本佔比僅為3%左右,而實際違約樣本佔比約為4.5%。
上例中,觀察時間視窗我們確定為90天,當然也可以是60天或30天,但當觀察時間視窗確定為30天時,客戶的違約狀態將會更快地達到穩定狀態。如果我們按照某個監管協議(如巴塞爾協議)的要求開發信用風險評分卡模型,則觀察時間視窗也要按照監管協議的要求確定。除此之外,觀察時間視窗的確定要根據樣本總體和證券公司的風險偏好綜合考慮確定。但在個人信用風險評級模型開發領域,大多數將逾期90天及以上定義為個人客戶的違約狀態。
以上講的都是開發申請者評分卡模型時表現時間視窗的確定方法,在開發個人客戶的行為評分卡和催收評分卡模型時,表現時間視窗的確定方法也算是類似的。但開發這兩類模型時,表現時間視窗的長度卻跟申請者評分模型有較大不同,如催收評分卡模型的表現時間視窗通常設定為2周,甚至更短的時間。因為實際業務開展過程中,通常客戶逾期超過2周,就要啟動催收程式了。
個人客戶的信用風險評級模型開發進行至此時,我們已經得到了沒有缺失值和異常值的樣本總體,違約的定義確定了,表現時間視窗和觀察時間視窗也確定了。接下來,我們將進入評分卡模型開發的第三步資料集準備階段了。
3.3 資料集準備
在缺失值和處理完成後,我們就得到了可用作信用風險評級模型開發的樣本總體。通常為了驗證評級模型的區分能力和預測準確性,我們需要將樣本總體分為樣本集和測試集,這種分類方法被稱為樣本抽樣。常用的樣本抽樣方法包括簡單隨機抽樣、分層抽樣和整群抽樣三種。
資料集準備:
http://blog.csdn.net/lll1528238733/article/details/76599861
3.4 變數篩選
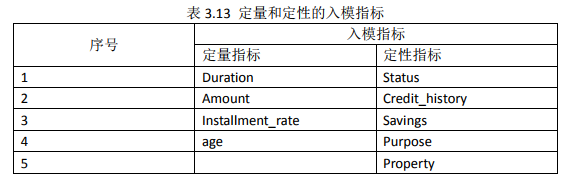
模型開發的前三步主要講的是資料處理的方法,從第四步開始我們將逐步講述模型開發的方法。在進行模型開發時,並非我們收集的每個指標都會用作模型開發,而是需要從收集的所有指標中篩選出對違約狀態影響最大的指標,作為入模指標來開發模型。接下來,我們將分別介紹定量指標和定性指標的篩選方法。
3.41 定量指標的篩選方法
http://blog.csdn.net/lll1528238733/article/details/76600019
3.42 定性指標的篩選方法
http://blog.csdn.net/lll1528238733/article/details/76600147
3.5 WOE值計算
對入模的定量和定性指標,分別進行連續變數分段(對定量指標進行分段),以便於計算定量指標的WOE和對離散變數進行必要的降維。對連續變數的分段方法通常分為等距分段和最優分段兩種方法。等距分段是指將連續變數分為等距離的若干區間,然後在分別計算每個區間的WOE值。最優分段是指根據變數的分佈屬性,並結合該變數對違約狀態變數預測能力的變化,按照一定的規則將屬性接近的數值聚在一起,形成距離不相等的若干區間,最終得到對違約狀態變數預測能力最強的最優分段。
我們首先選擇對連續變數進行最優分段,在連續變數的分佈不滿足最優分段的要求時,在考慮對連續變數進行等距分段。此處,我們講述的連續變數最優分段演算法是基於條件推理樹(conditional inference trees, Ctree)的遞迴分割演算法,其基本原理是根據自變數的連續分佈與因變數的二元分佈之間的關係,採用遞迴的迴歸分析方法,逐層遞迴滿足給定的顯著性水平,此時獲取的分段結果(位於Ctree的葉節點上)即為連續變數的最優分段。其核心演算法用函式ctree()表示。
評分卡模型開發-WOE值計算:
http://blog.csdn.net/lll1528238733/article/details/76600598
3.6 基於邏輯迴歸的標準評分卡實現
由邏輯迴歸的基本原理,我們將客戶違約的概率表示為p,則正常的概率為1-p。因此,可以得到:
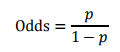
此時,客戶違約的概率p可表示為:
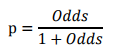
評分卡設定的分值刻度可以通過將分值表示為比率對數的線性表示式來定義,即可表示為下式:
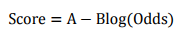
其中,A和B是常數。式中的負號可以使得違約概率越低,得分越高。通常情況下,這是分值的理想變動方向,即高分值代表低風險,低分值代表高風險。
邏輯迴歸模型計算比率如下所示:
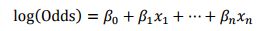
其中,用建模引數擬合模型可以得到模型引數β0,β1,…,βn。β0,β1,…,βn。為二元變數,表示變數i是否取第j個值。上式可重新表示為:
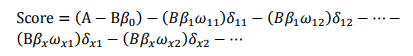
此式即為最終評分卡公式。如果x1…xnx1…xn的第j行的分值取決於以下三個數值:
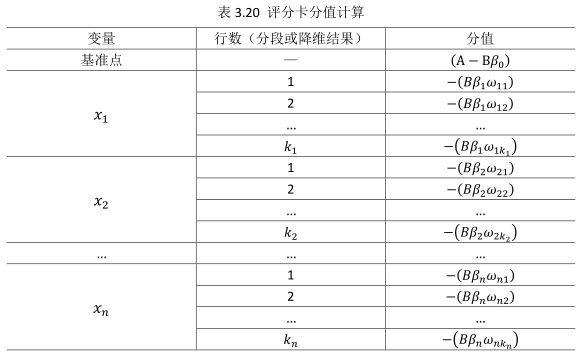
(1)刻度因子B;
(2)邏輯迴歸方程的引數βiβi
綜上,我們詳細講述了模型開發及生成標準評分卡各步驟的處理結果,自動生成標準評分卡的R完整程式碼:
library(klaR)
library(InformationValue)
data(GermanCredit)
train_kfold<-sample(nrow(GermanCredit),800,replace = F)
train_kfolddata<-GermanCredit[train_kfold,] #提取樣本資料集
test_kfolddata<-GermanCredit[-train_kfold,] #提取測試資料集
credit_risk<-ifelse(train_kfolddata[,"credit_risk"]=="good",0,1)
#將違約樣本用“1”表示,正常樣本用“0”表示。
tmp<-train_kfolddata[,-21]
data<-cbind(tmp,credit_risk)
quant_vars<-c("duration","amount","installment_rate","present_residence","age",
"number_credits","people_liable","credit_risk")
#獲取定量指標
quant_GermanCredit<-data[,quant_vars] #提取定量指標
#逐步迴歸法,獲取自變數中對違約狀態影響最顯著的指標
base.mod<-lm(credit_risk~1,data = quant_GermanCredit)
#獲取線性迴歸模型的截距
all.mod<-lm(credit_risk~.,data = quant_GermanCredit)
#獲取完整的線性迴歸模型
stepMod<-step(base.mod,scope = list(lower=base.mod,upper=all.mod),
direction = "both",trace = 0,steps = 1000)
#採用雙向逐步迴歸法,篩選變數
shortlistedVars<-names(unlist(stepMod[[1]]))
#獲取逐步迴歸得到的變數列表
shortlistedVars<-shortlistedVars[!shortlistedVars %in%"(Intercept)"]
#刪除逐步迴歸的截距
print(shortlistedVars)
#輸出逐步迴歸後得到的變數
quant_model_vars<-c("duration","amount","installment_rate","age")
#完成定量入模指標
#提取資料集中全部的定性指標
factor_vars<-c("status","credit_history","purpose","savings","employment_duration",
"personal_status_sex","other_debtors","property",
"other_installment_plans","housing","job","telephone","foreign_worker")
#獲取所有名義變數
all_iv<-data.frame(VARS=factor_vars,IV=numeric(length(factor_vars)),
STRENGTH=character(length(factor_vars)),stringsAsFactors = F)
#初始化待輸出的資料框
for(factor_var in factor_vars)
{
all_iv[all_iv$VARS==factor_var,"IV"]<-InformationValue::IV(X=
data[,factor_var],Y=data$credit_risk)
#計算每個指標的IV值
all_iv[all_iv$VARS==factor_var,"STRENGTH"]<-attr(InformationValue::IV(X=
data[,factor_var],Y=data$credit_risk),"howgood")
#提取每個IV指標的描述
}
all_iv<-all_iv[order(-all_iv$IV),] #排序IV
qual_model_vars<-subset(all_iv,STRENGTH=="Highly Predictive")[1:5,]
qual_model_vars<-c("status","credit_history","savings","purpose","property")
#連續變數分段和離散變數降維
#1.變數duration
library(smbinning)
result<-smbinning(df=data,y="credit_risk",x="duration",p=0.05)
result$ivtable
duration_Cutpoint<-c()
duration_WoE<-c()
duration<-data[,"duration"]
for(i in 1:length(duration))
{
if(duration[i]<=8)
{
duration_Cutpoint[i]<-"<= 8"
duration_WoE[i]<--1.5670
}
if(duration[i]<=33&duration[i]>8)
{
duration_Cutpoint[i]<-"<= 33"
duration_WoE[i]<--0.0924
}
if(duration[i]> 33)
{
duration_Cutpoint[i]<-"> 33"
duration_WoE[i]<-0.7863
}
}
#2.變數amount
result<-smbinning(df=data,y="credit_risk",x="amount",p=0.05)
result$ivtable
amount_Cutpoint<-c()
amount_WoE<-c()
amount<-data[,"amount"]
for(i in 1:length(amount))
{
if(amount[i]<= 3913)
{
amount_Cutpoint[i]<-"<= 3913"
amount_WoE[i]<--0.2536
}
if(amount[i]<= 9283&amount[i]> 3913)
{
amount_Cutpoint[i]<-"<= 9283"
amount_WoE[i]<-0.4477
}
if(amount[i]> 9283)
{
amount_Cutpoint[i]<-"> 9283"
amount_WoE[i]<-1.3109
}
}
#3.變數age
result<-smbinning(df=data,y="credit_risk",x="age",p=0.05)
result$ivtable
age_Cutpoint<-c()
age_WoE<-c()
age<-data[,"age"]
for(i in 1:length(age))
{
if(age[i]<= 34)
{
age_Cutpoint[i]<-"<= 34"
age_WoE[i]<-0.2279
}
if(age[i] > 34)
{
age_Cutpoint[i]<-" > 34"
age_WoE[i]<--0.3059
}
}
#4.變數installment_rate等距分段
install_data<-data[,c("installment_rate","credit_risk")]
tb1<-table(install_data)
total<-list()
for(i in 1:nrow(tb1))
{
total[i]<-sum(tb1[i,])
}
t.tb1<-cbind(tb1,total)
goodrate<-as.numeric(t.tb1[,"0"])/as.numeric(t.tb1[,"total"])
badrate<-as.numeric(t.tb1[,"1"])/as.numeric(t.tb1[,"total"])
gb.tbl<-cbind(t.tb1,goodrate,badrate)
Odds<-goodrate/badrate
LnOdds<-log(Odds)
tt.tb1<-cbind(gb.tbl,Odds,LnOdds)
WoE<-log((as.numeric(tt.tb1[,"0"])/700)/(as.numeric(tt.tb1[,"1"])/300))
all.tb1<-cbind(tt.tb1,WoE)
all.tb1
installment_rate_Cutpoint<-c()
installment_rate_WoE<-c()
installment_rate<-data[,"installment_rate"]
for(i in 1:length(installment_rate))
{
if(installment_rate[i]==1)
{
installment_rate_Cutpoint[i]<-"=1"
installment_rate_WoE[i]<-0.06252036
}
if(installment_rate[i]==2)
{
installment_rate_Cutpoint[i]<-"=2"
installment_rate_WoE[i]<-0.1459539
}
if(installment_rate[i]==3)
{
installment_rate_Cutpoint[i]<-"=3"
installment_rate_WoE[i]<--0.03937517
}
if(installment_rate[i]==4)
{
installment_rate_Cutpoint[i]<-"=4"
installment_rate_WoE[i]<--0.1657562
}
}
#定性指標的降維和WoE
discrete_data<-data[,c("status","credit_history","savings","purpose",
"property","credit_risk")]
summary(discrete_data)
#對purpose指標進行降維
x<-discrete_data[,c("purpose","credit_risk")]
d<-as.matrix(x)
for(i in 1:nrow(d))
{
#合併car(new)、car(used)
if(as.character(d[i,"purpose"])=="car (new)")
{
d[i,"purpose"]<-as.character("car(new/used)")
}
if(as.character(d[i,"purpose"])=="car (used)")
{
d[i,"purpose"]<-as.character("car(new/used)")
}
#合併radio/television、furniture/equipment
if(as.character(d[i,"purpose"])=="radio/television")
{
d[i,"purpose"]<-as.character("radio/television/furniture/equipment")
}
if(as.character(d[i,"purpose"])=="furniture/equipment")
{
d[i,"purpose"]<-as.character("radio/television/furniture/equipment")
}
#合併others、repairs、business
if(as.character(d[i,"purpose"])=="others")
{
d[i,"purpose"]<-as.character("others/repairs/business")
}
if(as.character(d[i,"purpose"])=="repairs")
{
d[i,"purpose"]<-as.character("others/repairs/business")
}
if(as.character(d[i,"purpose"])=="business")
{
d[i,"purpose"]<-as.character("others/repairs/business")
}
#合併retraining、education
if(as.character(d[i,"purpose"])=="retraining")
{
d[i,"purpose"]<-as.character("retraining/education")
}
if(as.character(d[i,"purpose"])=="education")
{
d[i,"purpose"]<-as.character("retraining/education")
}
}
new_data<-cbind(discrete_data[,c(-4,-6)],d)
#替換原資料集中的“purpose”指標的值
woemodel<-woe(credit_risk~.,data = new_data,zeroadj=0.5,applyontrain=TRUE)
woemodel$woe
#1.status
status<-as.matrix(new_data[,"status"])
colnames(status)<-"status"
status_WoE<-c()
for(i in 1:length(status))
{
if(status[i]=="... < 100 DM")
{
status_WoE[i]<--0.8671300
}
if(status[i]=="0 <= ... < 200 DM")
{
status_WoE[i]<--0.4240681
}
if(status[i]=="... >= 200 DM / salary for at least 1 year")
{
status_WoE[i]<-0.4129033
}
if(status[i]=="no checking account")
{
status_WoE[i]<-1.2237524
}
}
#2.credit_history
credit_history<-as.matrix(new_data[,"credit_history"])
colnames(credit_history)<-"credit_history"
credit_history_WoE<-c()
for(i in 1:length(credit_history))
{
if(credit_history[i]=="no credits taken/all credits paid back duly")
{
credit_history_WoE[i]<--1.53771824
}
if(credit_history[i]=="all credits at this bank paid back duly")
{
credit_history_WoE[i]<--1.00079000
}
if(credit_history[i]=="existing credits paid back duly till now")
{
credit_history_WoE[i]<--0.09646414
}
if(credit_history[i]=="delay in paying off in the past")
{
credit_history_WoE[i]<--0.01996074
}
if(credit_history[i]=="critical account/other credits existing")
{
credit_history_WoE[i]<-0.77276102
}
}
#3.savings
savings<-as.matrix(new_data[,"savings"])
colnames(savings)<-"savings"
savings_WoE<-c()
for(i in 1:length(savings))
{
if(savings[i]=="... < 100 DM")
{
savings_WoE[i]<--0.3051490
}
if(savings[i]=="100 <= ... < 500 DM")
{
savings_WoE[i]<--0.2267733
}
if(savings[i]=="500 <= ... < 1000 DM")
{
savings_WoE[i]<-0.8340112
}
if(savings[i]=="... >= 1000 DM")
{
savings_WoE[i]<-1.1739617
}
if(savings[i]=="unknown/no savings account")
{
savings_WoE[i]<-0.7938144
}
}
#4.property
property<-as.matrix(new_data[,"property"])
colnames(property)<-"property"
property_WoE<-c()
for(i in 1:length(property))
{
if(property[i]=="real estate")
{
property_WoE[i]<-0.49346566
}
if(property[i]=="building society savings agreement/life insurance")
{
property_WoE[i]<--0.16507975
}
if(property[i]=="car or other")
{
property_WoE[i]<-0.08054425
}
if(property[i]=="unknown/no property")
{
property_WoE[i]<--0.65586969
}
}
#5.purpose
purpose<-as.matrix(new_data[,"purpose"])
colnames(purpose)<-"purpose"
purpose_WoE<-c()
for(i in 1:length(purpose))
{
if(purpose[i]=="car(new/used)")
{
purpose_WoE[i]<--0.11260594
}
if(purpose[i]=="domestic appliances")
{
purpose_WoE[i]<-0.53602528
}
if(purpose[i]=="others/repairs/business")
{
purpose_WoE[i]<--0.09146793
}
if(purpose[i]=="radio/television/furniture/equipment")
{
purpose_WoE[i]<--0.23035114
}
if(purpose[i]=="retraining/education")
{
purpose_WoE[i]<--0.43547619
}
}
#入模定量和定性指標
model_data<-cbind(data[,quant_model_vars],data[,qual_model_vars])
#入模定量和定性指標的WOE
credit_risk<-as.matrix(data[,"credit_risk"])
colnames(credit_risk)<-"credit_risk"
model_data_WOE<-as.data.frame(cbind(duration_WoE,amount_WoE,age_WoE,
installment_rate_WoE,status_WoE,credit_history_WoE,
savings_WoE,property_WoE,purpose_WoE,credit_risk))
#入模定量和定性指標“分段”
model_data_Cutpoint<-cbind(duration_Cutpoint,amount_Cutpoint,age_Cutpoint,
installment_rate_Cutpoint,status,credit_history,
savings,property,purpose)
#邏輯迴歸
m<-glm(credit_risk~.,data=model_data_WOE,family = binomial())
alpha_beta<-function(basepoints,baseodds,pdo)
{
beta<-pdo/log(2)
alpha<-basepoints+beta*log(baseodds)
return(list(alpha=alpha,beta=beta))
}
coefficients<-m$coefficients
#通過指定特定比率(1/20)的特定分值(50)和比率翻番的分數(10),來計算評分卡的係數alpha和beta
x<-alpha_beta(50,0.05,10)
#計算基礎分值
basepoint<-round(x$alpha-x$beta*coefficients[1])
#1.duration_score
duration_score<-round(as.matrix(-(model_data_WOE[,"duration_WoE"]*
coefficients["duration_WoE"]*x$beta)))
colnames(duration_score)<-"duration_score"
#2.amount_score
amount_score<-round(as.matrix(-(model_data_WOE[,"amount_WoE"]*
coefficients["amount_WoE"]*x$beta)))
colnames(amount_score)<-"amount_score"
#3.age_score
age_score<-round(as.matrix(-(model_data_WOE[,"age_WoE"]*
coefficients["age_WoE"]*x$beta)))
colnames(age_score)<-"age_score"
#4.installment_rate_score
installment_rate_score<-round(as.matrix(-(model_data_WOE[,"installment_rate_WoE"]*
coefficients["installment_rate_WoE"]*x$beta)))
colnames(installment_rate_score)<-"installment_rate_score"
#5.status_score
status_score<-round(as.matrix(-(model_data_WOE[,"status_WoE"]*
coefficients["status_WoE"]*x$beta)))
colnames(status_score)<-"status_score"
#6.credit_history_score
credit_history_score<-round(as.matrix(-(model_data_WOE[,"credit_history_WoE"]*
coefficients["credit_history_WoE"]*x$beta)))
colnames(credit_history_score)<-"credit_history_score"
#7.savings_score
savings_score<-round(as.matrix(-(model_data_WOE[,"savings_WoE"]*
coefficients["savings_WoE"]*x$beta)))
colnames(savings_score)<-"savings_score"
#8.property_score
property_score<-round(as.matrix(-(model_data_WOE[,"property_WoE"]*
coefficients["property_WoE"]*x$beta)))
colnames(property_score)<-"property_score"
#9.purpose_score
purpose_score<-round(as.matrix(-(model_data_WOE[,"purpose_WoE"]*
coefficients["purpose_WoE"]*x$beta)))
colnames(purpose_score)<-"purpose_score"
#輸出最終的CSV格式的打分卡
#1.基礎分值
r1<-c("","basepoint",20)
m1<-matrix(r1,nrow = 1)
colnames(m1)<-c("Basepoint","Basepoint","Score")
#2.duration的分值
duration_scoreCard<-cbind(as.matrix(c("Duration","",""),ncol=1),
unique(cbind(duration_Cutpoint,duration_score)))
#View(duration_scoreCard)
#3.amount的分值
amount_scoreCard<-cbind(as.matrix(c("Amount","",""),ncol=1),
unique(cbind(amount_Cutpoint,amount_score)))
#View(amount_scoreCard)
#4.age的分值
age_scoreCard<-cbind(as.matrix(c("Age",""),ncol=1),
unique(cbind(age_Cutpoint,age_score)))
#View(age_scoreCard)
#5.installment_rate的分值
installment_rate_scoreCard<-cbind(as.matrix(c("Installment_rate","","",""),ncol=1),
unique(cbind(installment_rate_Cutpoint,installment_rate_score)))
#View(installment_rate_scoreCard)
#6.status的分值
status_scoreCard<-cbind(as.matrix(c("Status","","",""),ncol=1),
unique(cbind(status,status_score)))
#View(status_scoreCard)
#7.credit_history的分值
credit_history_scoreCard<-cbind(as.matrix(c("Credit_history","","","",""),ncol=1),
unique(cbind(credit_history,credit_history_score)))
#View(credit_history_scoreCard)
#8.savings的分值
savings_scoreCard<-cbind(as.matrix(c("Savings","","","",""),ncol=1),
unique(cbind(savings,savings_score)))
#View(savings_scoreCard)
#9.property的分值
property_scoreCard<-cbind(as.matrix(c("Property","","",""),ncol=1),
unique(cbind(property,property_score)))
#View(property_scoreCard)
#10.purpose的分值
purpose_scoreCard<-cbind(as.matrix(c("Purpose","","","",""),ncol=1),
unique(cbind(purpose,purpose_score)))
#View(purpose_scoreCard)
scoreCard_CSV<-rbind(m1,duration_scoreCard,amount_scoreCard,age_scoreCard,
installment_rate_scoreCard,status_scoreCard,credit_history_scoreCard,
savings_scoreCard,property_scoreCard,purpose_scoreCard)
#將標準評分卡輸出到專案檔案中,且命名為ScoreCard.CSV,調整格式即可得到標準評分卡
write.csv(scoreCard_CSV,"C:/Users/ZL/Desktop/creditcard_model/ScoreCard.CSV")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 40