
TextRank演算法抽取關鍵詞
PageRank
由於TextRank是由大名鼎鼎的Google的PageRank演算法轉化而來,所以這裡先介紹一下PageRank演算法。
PageRank最開始用來計算網頁的重要性。在衡量一個網頁的排名時,直覺告訴我們:
(1)一個網頁被更多網頁連結時,就應該越重要,其排名就應該越靠前。
(2)排名高的網頁應具有更大的表決權,即當一個網頁被排名高的網頁所連結時,其重要性也應該提高。
所以基於以上兩點,PageRank演算法所建立的模型非常簡單:一個網頁的排名等於所有連結到該網頁的網頁的加權排名之和。
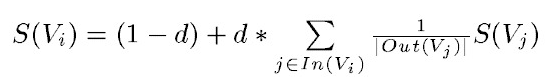
整個www可以看作一張有向圖圖,節點是網頁。如果網頁A存在到網頁B的連結,那麼有一條從網頁A指向網頁B的有向邊。
S(Vi)是網頁i的中重要性(PR值)。d是阻尼係數,一般設定為0.85。In(Vi)是存在指向網頁i的連結的網頁集合。Out(Vj)是網頁j中的連結存在的連結指向的網頁的集合,|Out(Vj)|是集合中元素的個數。
通俗來說也就是,對於網頁i來說,它的重要性,取決於指向網頁i的每個網頁的重要性之和來決定的。每個指向到網頁i的重要性S(Vj)還需要對所有它所指出去的頁面平分,所以要除以|Out(Vj)。同時,該頁面S(Vj)的重要性不能單單由其他的連結頁面決定,還包含一定的概率來決定要不要接受由其他頁面來決定,這也就是d的作用。
但是,為了獲得某個網頁的重要性,而需要知道其他網頁的重要性,這不就等同於“是先有雞還是先有蛋”的問題了麼?幸運的是,PageRank採用power iteration方法破解了這個問題怪圈。先給定一個初始值,然後通過多輪迭代求解,迭代到最後就會收斂於一個結果。當差別小於某個閾值時,就可以結束迭代了。
TextRank
正規的TextRank公式在PageRank的公式的基礎上,引入了邊的權值的概念,代表兩個句子的相似度。
TextRank 一般模型可以表示為一個有向有權圖 G =(V, E), 由點集合 V和邊集合 E 組成, E 是V ×V的子集。圖中任兩點 Vi , Vj 之間邊的權重為 wji , 對於一個給定的點 Vi, In(Vi) 為 指 向 該 點 的 點 集 合 , Out(Vi) 為點 Vi 指向的點集合。點 Vi 的得分定義如下:
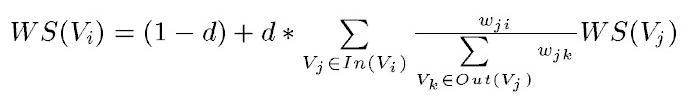
其中, d 為阻尼係數, 取值範圍為 0 到 1, 代表從圖中某一特定點指向其他任意點的概率, 一般取值為 0.85。
使用TextRank 演算法計算圖中各點的得分時, 需要給圖中的點指定任意的初值, 並遞迴計算直到收斂, 即圖中任意一點的誤差率小於給定的極限值時就可以達到收斂, 一般該極限值取 0.0001。
由於引入了句子的相似度,所以正規的TextRank公式是用來從文章中自動抽取關鍵句,但是我們現在是想計算關鍵字,如果把一個單詞視為一個句子的話,那麼所有句子(單詞)構成的邊的權重都是0(沒有交集,沒有相似性),所以分子分母的權值w約掉了,演算法退化為PageRank。所以說,關鍵字提取演算法也就是PageRank。
對於提取關鍵詞來說,假如設視窗大小為5,In(Vi)是與詞i的距離不大於5的詞的集合。Out(Vj)是與詞j距離不大於5詞的集合,|Out(Vj)|是集合中元素的個數。
樣例
對於句子:
程式設計師(英文Programmer)是從事程式開發、維護的專業人員。一般將程式設計師分為程式設計人員和程式編碼人員,但兩者的界限並不非常清楚,特別是在中國。軟體從業人員分為初級程式設計師、高階程式設計師、系統分析員和專案經理四大類。
首先對這句話分詞,得出分詞結果:
[程式設計師/n, (, 英文/nz, programmer/en, ), 是/v, 從事/v, 程式/n, 開發/v, 、/w, 維護/v, 的/uj, 專業/n, 人員/n, 。/w, 一般/a, 將/d, 程式設計師/n, 分為/v, 程式/n, 設計/vn, 人員/n, 和/c, 程式/n, 編碼/n, 人員/n, ,/w, 但/c, 兩者/r, 的/uj, 界限/n, 並/c, 不/d, 非常/d, 清楚/a, ,/w, 特別/d, 是/v, 在/p, 中國/ns, 。/w, 軟體/n, 從業/b, 人員/n, 分為/v, 初級/b, 程式設計師/n, 、/w, 高階/a, 程式設計師/n, 、/w, 系統/n, 分析員/n, 和/c, 專案/n, 經理/n, 四/m, 大/a, 類/q, 。/w]
然後去掉裡面的停用詞,比如標點符號、常用詞、以及“名詞、動詞、形容詞、副詞之外的詞”。得出實際有用的詞語:
[程式設計師, 英文, 程式, 開發, 維護, 專業, 人員, 程式設計師, 分為, 程式, 設計, 人員, 程式, 編碼, 人員, 界限, 特別, 中國, 軟體, 人員, 分為, 程式設計師, 高階, 程式設計師, 系統, 分析員, 專案, 經理]
然後我們首先計算距離每個詞距離不大於視窗大小的詞的集合,然後根據公式進行迭代,直到所有詞的重要性收斂到某一個值的時候,就可以停止迭代並輸出結果。
程式碼
|
輸出結果
|
對結果進行Map排序之後的結果:
|
可以看出結果還是有一定說服性的。