
推薦系統——關聯規則
購物籃分析(關聯規則挖掘,頻繁規則挖掘)
名詞解釋:
挖掘資料集(事務資料集,交易資料集):購物籃資料
頻繁模式:頻繁地出現在資料集中的模式,例如項集,子結構,子序列等
挖掘目標:頻繁模式,頻繁項集,關聯規則等
關聯規則:牛奶=》雞蛋【支援度=2%,置信度=60%】
支援度:分析中的全部事物的2%同時購買了牛奶和雞蛋
置信度:購買了牛奶的筒子有60%也購買了雞蛋
最小支援度閾值和最小置信度閾值:由挖掘者或領域專家設定
項集:項(商品)的集合
k-項集:k個項組成的集合
頻繁項集:滿足最小支援度的項集,頻繁k-項集一般記為Lk
強關聯規則:滿足最小支援度閾值和最小置信度閾值的規則
我感覺:主要就是挖掘頻繁模式或者頻繁項集(頻繁項集是頻繁模式的一種),進而找到關聯規則。
關聯規則挖掘:Apriori演算法
兩步過程:找出所有頻繁項集;由頻繁項集產生強關聯規則
演算法:Apriori
例子:
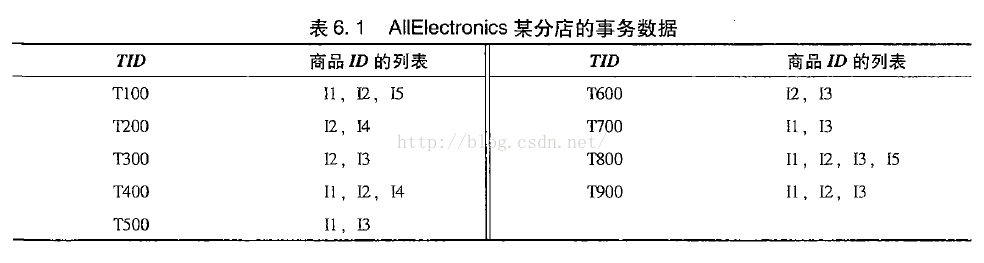
Apriori演算法的工作過程:
步驟說明:
掃描D,對每個候選項計數,生成候選1-項集C1
定義最小支援度閾值為2,從C1生成頻繁1-項集L1
通過L1xL1生成候選2-項集C2
掃描D,對C2裡每個項計數,生成頻繁2-項集L2
計算L3xL3,利用apriori性質:頻繁項集的子集必然是頻繁的,我們可以刪去一部分項,從而得到C3,由C3再經過支援度計數生成L3
可見Apriori演算法可以分成連線,剪枝兩個步驟不斷迴圈重複

由頻繁項集提取關聯規則:
例子:我們計算出頻繁項集{I1,I2,I5},能提取哪些規則?
I1^I2=>I5,由於{I1,I2,I5}出現了2次,{I1,I2}出現了4次,故置信度為2/4=50%
類似可以算出

演算法的缺點:L1到C2是笛卡爾積,如果L1比較大,C2難以想象,如果要控制L1較小,則需要提高支援度。有時候不需要提交支援度,那怎麼樣進行優化呢?
提高Apriori的效率:
基於雜湊的演算法(基本不用,不做講解)
基於FP tree的演算法(如下)
TP樹:
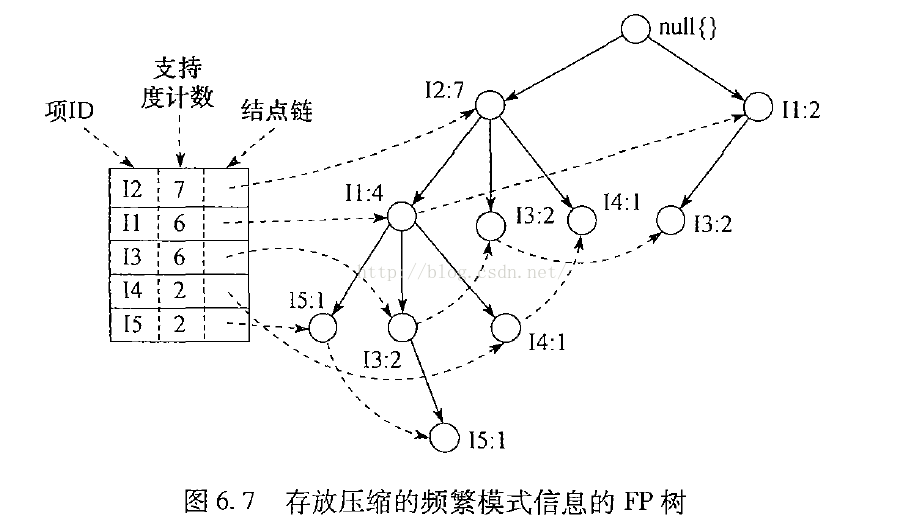
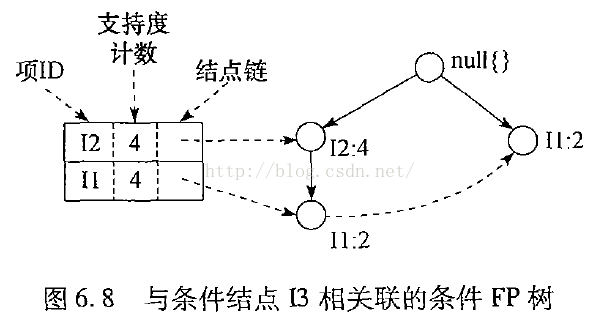
挖掘過程圖示:

FP-Growth演算法虛擬碼:

FPGrowth演算法出來以後,因為他很耗記憶體(建立樹),一臺機器的記憶體可能不夠,所以我們如果能把他分散在多臺計算機裡面計算的話,那麼可以減少我們計算的複雜程度,
進而誕生出了PFP
分散式FP-Growth

如果reduce階段採用上述,reduce階段資料量一樣會非常大,一樣沒有解決問題,若果吧reduce的任務放在多個機器上,會有多臺機器之間的互動(資料丟失,互動),也沒有解決問題,可以採用對映的方式,機器直接也不會資料存在丟失或者互動。如下步驟(G-List):
主要步驟:
將資料集分片
計數,產生排序的F-List
將物品分組,產生G-List(這個樣子可以導致reduce在許多臺機器上同時執行)
(PFP演算法關鍵步驟)並行FP-Growth過程
聚合結果
應用:網頁中的最佳拍檔:如下所示:

使用者行為的一些思量:
互斥的商品,例如同類的自行車,汽車,內容相近的書籍,此時不能使用套餐推薦
推薦相近商品的時候使用瀏覽記錄,使用購買記錄更類似於關聯規則挖掘
考慮興趣的時效性,例如已經購買了某種自行車,就沒必要再向使用者推薦相近的自行車
總結一下:當我們推薦相近商品的時候,最好可以使用瀏覽記錄來進行推薦,使用基於物品的協同過濾演算法;
如果要推薦套餐的話,最好是基於購買記錄,購物籃分析,用關聯模式挖掘(關聯規則挖掘)。