
個性化推薦演算法 綜述
隨著網際網路的迅速發展,接入網際網路的網頁與伺服器數量也以指數形式迅猛增長。網際網路的發展,使得海量資訊以飛快的更新速度在我們眼前不斷呈現。例如,卓越亞馬遜上存在著上千萬的圖書,NetFlix上有數萬部電影。如此眾多的資訊,遍歷一遍都變得十分艱難,更何況要在其中找到自己感興趣的部分。傳統的搜尋策略,為每個使用者的相同查詢提供完全相同的搜尋結果,無法針對不同使用者的個人需求提供個性化服務。資訊爆炸增長反而使資訊的獲取效率變低了。這種現象被稱為資訊過載。如今有效解決資訊過載的工具之一便是個性化推薦。推薦問題從根本上來說就是“代替使用者評估它從未看過的產品”[1-5]。這些產品包括書、電影、CD、網頁、甚至可以是飯店、音樂、繪畫等等——是一個從已知到未知的過程。
1 推薦問題的定義
假設C是使用者集合,S是所有可能被推薦的條目的集合。那麼我們可以在使用者集合和條目集合的笛卡爾乘積之上定義一個效用函式u,來衡量條目s對使用者c的有用程度,比如:푢:퐶×푆→푅,其中R是一個良序集(例如一定範圍內的實數或者非負整數),那麼對於任意使用者푐∈퐶,我們需要選擇條目푠'∈푆從而最大化使用者的效用值,也就是說:
![]()
其示意圖見圖1
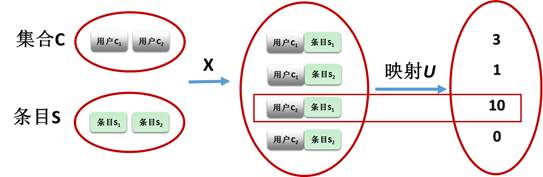
Figure 1. Illustration of Recommendation Algorithm
圖1 推薦演算法示意圖
在一般的推薦系統中,效用值通常用使用者評分或者是標記喜歡與否來衡量。但從原始的形式化定義出發,這個效用函式可以是任意形態,比如使用者點選、收藏,或停留時間、回訪,甚至是網站的銷量、利潤等,只要它滿足效用函式的基本性質(可加性、傳遞性和三角不等式)。在這樣的問題定義框架下,推薦問題轉化為優化問題,個性化推薦演算法的選擇與推薦問題本身相互解耦。
我們只需關心演算法對解決問題的效果和演算法本身的效率,從而在最大程度上體現了對演算法的包容性,各式各樣的演算法都可以在統一的框架下為最終的優化目標充分展開競爭。
過去20年,個性化推薦演算法得到長足的發展和進步。自從20世紀90年代中期第一篇系統介紹協同過濾演算法的論文發表以來,針對個性化推薦系統的演算法優化,學術界和工業界的研究學者和實踐者們從不同的領域出發,提出了各種模型和解決方案。
粗略統計,所涉及到的學科包括人工智慧、機器學習、認知科學、資訊抽取、資料探勘、預測理論、近似理論,甚至是管理科學、市場營銷和心理學。所使用的演算法除了傳統的協同過濾,還包括圖模型(Graph Model)、矩陣分解(
Table 1 Categories of Recommendation Algorithm
表1 推薦演算法分類
|
基於內容 |
TF-IDF 聚類 最大熵 相似度度量 |
貝葉斯分類 決策樹 神經網路 專家系統 知識推理 |
|
協同過濾 |
K近鄰 聚類 連結分析 關聯規則 相似度度量 |
貝葉斯分類 決策樹 神經網路 矩陣分解 概率模型 圖模型 Boosting Topic Model 迴歸分析 |
|
混合式 |
線性組合 投票機制 meta-heuristics |
Ensemble 統一推薦框架 |
早期的推薦系統文獻中一般從所選取的角度和所採用的技術兩個不同的維度對個性化推薦演算法進行劃分。從選取的角度不同,可以分為基於內容的演算法、協同過濾演算法,以及混合式演算法三大類。從具體技術角度,可以分為基於記憶體(Memory-based)的演算法和基於模型(Model based)的演算法兩種形式。
2.1 基於內容的演算法
基於內容的推薦是從資訊抽取領域自然而然發展起來的一類演算法,其出發點是在對文字資訊和條目元資訊進行整理、建模的基礎上,針對使用者的不同興趣偏好進行推送。
最初,基於內容的推薦其實是協同過濾的衍生。他不依賴於使用者對產品的評價,而是根據使用者所選擇的產品內容資訊計算使用者之間的相似度進行推薦的。基於內容的演算法根本在於資訊獲取和資訊過濾。因為在文字資訊獲取與過濾方面較為常數,現有很多基於內容的推薦系統都是通過分析產品的文字資訊進行推薦。
在資訊抽取領域,最常用的文字抽取方法便是TF-IDF方法:
假設有N個文字檔案,關鍵詞푘푖在푛푖個檔案中出現,設푓푖푗為關鍵詞푘푖在檔案푑푗中出現的次數,那麼푘푖在푑푗中的詞頻푇퐹푖푗定義為:
![]()
其中分母的最大值可以通過計算푑푗中所有關鍵詞푘푧的頻率得到。
在許多檔案中同時出現的關鍵詞對於表示檔案的特性, 區分檔案的關聯性是沒有貢獻的. 因此TFij與這個關鍵詞在檔案中出現數的逆( IDFi ) 一起使用, IDFi的定義為:
![]()
檔案dj可表示成向量:
![]()
其中:
![]()
這樣,使用者的配置檔案和產品都可以表示成TD-IDF模型,通過計算兩者的相關度進行推薦:
![]()
rc,s可以用二者的餘弦相似度計算,如:
![]()
與基於內容的推薦相對應,協同過濾推薦並不關心條目的具體屬性,而是對使用者群整體的評分資訊進行整理和建模,根據使用者行為找出口味相似的使用者群或者風格類似的條目,在此基礎上進行推薦。
協同過濾演算法的核心思想是,先根據使用者的歷史資訊計算使用者間的相似度,再根據相似使用者的喜好,為鄰居使用者推薦類似的產品。協同過濾最大特點是對產品格式沒有特殊要求,可以處理難以文字化的產品如音樂、視訊等。
協同過濾可以分為基於記憶的和基於模型的演算法。
基於記憶的演算法會根據目前系統中所有打過分的產品進行預測。這一類演算法不需要預先訓練模型,只需定期對評分資料進行預處理,比如計算使用者或條目的相似性,在給使用者進行推薦時,整個過程都可以在記憶體中完成。我們所熟知的基於餘弦相似和K近鄰的標準協同過濾演算法就屬於這個範疇,此外還有各種利用聚類做推薦的演算法、關聯規則、連結分析等。由於這類演算法更多強調規則而非模型,有時也把基於記憶體的演算法稱為啟發式推薦演算法。
基於模型的推薦演算法則有一個獨立的模型訓練階段,利用全體或部分評分資料訓練一個模型,這一步一般是離線完成的,線上推薦時則林勇訓練好的模型實時做出相應。在這個框架下,可以利用人工智慧和機器學習領域多年研究的各種模型和成果,演算法的設計和實現過程要更加規範。
3.1 預測準確度
預測準確度考慮推薦演算法的預測打分與使用者實際打分的相似程度。預測準確度的一個經典度量方法是度量系統的預測打分與使用者的實際打分的平均絕對誤差(Mean Absolute Error)。
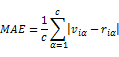
其中,c為系統中使用者i打分產品的個數,![]() 為使用者的實際打分,
為使用者的實際打分,![]() 為系統的預測打分。
為系統的預測打分。
這種方法有兩個優點:一是計算方法比較簡單,便於直觀上的理解;二是對於不同的系統,其平局絕對誤差是不同的,從而能區別不同系統的絕對誤差。
除了平均絕對誤差之外,還有平均平方誤差(Mean Square Error)和標準平均絕對誤差(NormalizedMean Absolute Error)等方法。其中,平均平方誤差定義如下:
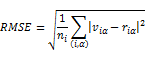
其中,![]() 為系統中使用者一產品對
為系統中使用者一產品對![]() 的個數。在平局平方誤差計算中,預測打分與實際打分作差之後還有一個平方操作,這樣打分誤差的影響會比平局絕對誤差大。
的個數。在平局平方誤差計算中,預測打分與實際打分作差之後還有一個平方操作,這樣打分誤差的影響會比平局絕對誤差大。
3.2 分類準確度
分類準確度定義為推薦演算法對一個產品使用者是否喜歡判定正確的比例。因此,當用戶只有二元選擇時,用分類準確度進行評價較為合適。而且這種方法受打分稀疏性的影響。雖然目前有一些方法處理打分稀疏性問題,但效果並不理想。
另一種廣泛應用的分類準確度指標為準確率、召回率以及相關指標。但準確率和召回率的計算又成了另一個新的問題。另外一個度量系統分類準確度的重要指標就是ROC曲線。
4 總結
個性化推薦問題是個系統性問題,設計多個學科,個性化推薦演算法也可以包羅永珍。相關領域的新進展,對使用者行為的洞察,一個新的想法,都可以成為新的個性化推薦演算法的基礎。在工業界的時間領域,則不必糾結於演算法種類上的劃分或學科間的門戶之見,但瞭解前人的工作,深入理解演算法的理論來源和數學基礎,無疑是有助於演算法的改進和效果的提升。新的理論層出不窮,新的演算法也是百花怒放,把無助基礎和根本,使用效果來檢驗,方可立於不敗之地。
轉載至:http://blog.sciencenet.cn/blog-795423-702315.html