
熱度演算法和個性化推薦
今日頭條的走紅帶動了“個性化推薦”的概念,自此之後,內容型的產品,個性化演算法就逐漸從賣點變為標配。伴隨著“機器學習”,“大資料”之類的熱詞和概念,產品的檔次瞬間提高了很多。而各種推薦演算法絕不僅僅是研發自己的任務,作為產品經理,必須深入到演算法內部,參與演算法的設計,以及結合內容對演算法不斷“調教”,才能讓產品的推薦演算法不斷完善,最終與自己的內容雙劍合璧。
本文以新聞產品為例,結合了我之前產品從零積累使用者的經驗,整理了作為PM需要了解的基本演算法知識和實操。
一、演算法的發展階段
個性化推薦不是產品首次釋出時就能帶的,無論是基於使用者行為的個性化,還是基於內容相似度的個性化,都建立在大量的使用者數和內容的基礎上。產品釋出之初,一般兩邊的資料都有殘缺,因此個性化推薦也無法開展。
所以在產品發展的初期,推薦內容一般採用更加聚合的“熱度演算法”,顧名思義就是把熱點的內容優先推薦給使用者。雖然無法做到基於興趣和習慣為每一個使用者做到精準化的推薦,但能覆蓋到大部分的內容需求,而且啟動成本比個性化推薦演算法低太多。
因此內容型產品,推薦在釋出初期用熱度演算法實現冷啟動,積累了一定量級以後,才能逐漸開展個性化推薦演算法。
二、熱度演算法
2.1 熱度演算法基本原理
需要了解的是,熱度演算法也是需要不斷優化去完善的,基本原理:
新聞熱度分 = 初始熱度分 + 使用者互動產生的熱度分 – 隨時間衰減的熱度分
新聞入庫後,系統為之賦予一個初始熱度值,該新聞就進入了推薦列表進行排序;隨著新聞不斷被使用者點選閱讀,收藏,分享等,這些使用者行為被視作幫助新聞提升熱度,系統需要為每一種新聞賦予熱度值;同時,新聞是有較強時效性的內容,因此新聞釋出之後,熱度必須隨著新聞變得陳舊而衰減。
新聞的熱度就在這些演算法的綜合作用下不斷變化,推薦列表的排序也就不斷變化。
2.2 初始熱度不應該一致
上面的演算法為每一條入庫的新聞賦予了同樣的熱度值,但在現實使用後發現行不通,例如娛樂類別比文化類別受歡迎程度本身就高很多;或者突發了嚴重的災害或事故;或是奧運會期間,體育類別的關注度突然高了起來;而此時如果還是每條新聞給同樣的熱度就不能貼合實際了。
解決辦法就是把初始熱度設定為變數:
(1)按照新聞類別給予新聞不同的初始熱度,讓使用者關注度高的類別獲得更高的初始熱度分,從而獲得更多的曝光,例如:

(2)對於重大事件的報道,如何讓它入庫時就有更高的熱度,我們採用的是熱詞匹配的方式。
即對大型新聞站點的頭條,Twitter熱點,競品的頭條做監控和扒取,並將這批新聞的關鍵詞維護到熱詞庫並保持更新;每條新聞入庫的時候,讓新聞的關鍵詞去匹配熱詞庫,匹配度越高,就有越高的初始熱度分。
這樣處理後,重大事件發生時,Twitter和入口網站的爭相報道會導致熱詞集中化,所有匹配到這些熱詞的新聞,即報道同樣事件的新聞,會獲得很高的初始熱度分。
2.3 使用者行為分規則不是固定不變的
解決了新聞入庫的初始分之後,接下來是新聞熱度分的變化。先要明確使用者的的哪些行為會提高新聞的熱度值,然後對這些行為賦予一定的得分規則。例如對於單條新聞,使用者可以點選閱讀(click),收藏(favor),分享(share),評論(comment)這四種行為,我們為不同的行為賦予分數,就能得到新聞的實時使用者行為分為:
這裡對不同行為賦予的分數為1,5,10,20,但這個值不能是一成不變的;當用戶規模小的時候,各項事件都小,此時需要提高每個事件的行為分來提升使用者行為的影響力;當用戶規模變大時,行為分也應該慢慢降低,因此做內容運營時,應該對行為分不斷調整。
當然也有偷懶的辦法,那就是把使用者規模考慮進去,算固定使用者數的行為分,即:
這樣就保證了在不同使用者規模下,使用者行為產生的行為分基本穩定。
2.4 熱度隨時間的衰減不是線性的
由於新聞的強時效性,已經發布的新聞的熱度值必須隨著時間流逝而衰減,並且趨勢應該是衰減越來越快,直至趨近於零熱度。換句話說,如果一條新聞要一直處於很靠前的位置,隨著時間的推移它必須要有越來越多的使用者來維持。
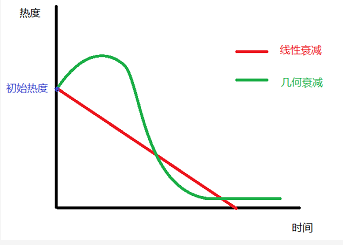
我們要求推薦給使用者的新聞必須是24h以內,所以理論上講,衰減演算法必須保證在24h後新聞的熱度一定會衰減到很低,如果是線性衰減,當某些新聞突然有大量使用者閱讀,獲得很高的熱度分時,可能會持續排名靠前很久,讓使用者覺得內容更新過慢。
參考牛頓冷卻定律,時間衰減因子應該是一個類似於指數函式:
其中T0是新聞釋出時間,T1是當前時間。
而由於熱度的發展最終是一個無限趨近於零熱度的結果,最終的新聞的熱度演算法也調整為:
2.5 其他影響因素
很多新聞產品會給使用者“贊”,“踩”或“不在推薦此類”的選項,這些功能不僅適用於個性化推薦,對熱度演算法也有一定的作用。
新聞的推送會造成大量的開啟,在計算熱度的時候需要排除掉相關的影響。類似於這樣的因素,都會對熱度演算法產生影響,因此熱度演算法上線後,依然需要不斷地“調教”。建議把所有的調整指標做成可配項,例如初始熱度分,行為事件分,衰減因子等,從而讓產品和運營能實時調整和驗證效果,達到最佳狀態。
三、基於內容的推薦演算法
現在,你的內容產品順利度過了早期階段,擁有了幾萬甚至十幾萬級別的日活。這時候,你發現熱度演算法導致使用者的閱讀內容過於集中,而個性化和長尾化的內容卻鮮有人看,看來是時候開展個性化推薦,讓使用者不僅能讀到大家都喜歡的內容,也能讀到只有自己感興趣的內容。
個性化推薦一般有兩種通用的解決方案,一是基於內容的相關推薦,二是基於使用者的協同過濾。 由於基於使用者的協同過濾對使用者規模有較高要求,因此更多使用基於內容的相關推薦來切入。
這裡引入一個概念叫“新聞特徵向量”來標識新聞的屬性,以及用來對比新聞之間的相似度。我們把新聞看作是所有關鍵詞(標籤)的合集,理論上,如果兩個新聞的關鍵詞越類似,那兩個新聞是相關內容的可能性更高。 新聞特徵向量是由新聞包含的所有關鍵詞決定的。得到新聞特徵向量的第一步,是要對新聞內容進行到關鍵詞級別的拆分。
3.1 分詞
分詞需要有兩個庫,即正常的詞庫和停用詞庫。正常詞庫類似於一本詞典,是把內容拆解為詞語的標準;停用詞庫則是在分詞過程中需要首先棄掉的內容。
停用詞主要是沒有實際含義的,例如“The”,“That”,“are”之類的助詞;表達兩個詞直接關係的,例如“behind”,“under”之類的介詞,以及很多常用的高頻但沒有偏向性的動詞,例如“think”“give”之類。顯而易見,這些詞語對於分詞沒有任何作用,因此在分詞前,先把這些內容剔除。
剩下對的內容則使用標準詞庫進行拆詞,拆詞方法包含正向匹配拆分,逆向匹配拆分,最少切分等常用演算法,這裡不做展開。
因為網路世界熱詞頻出, 標準詞庫和停用詞庫也需要不斷更新和維護,例如“藍瘦香菇”,“套路滿滿”之類的詞語,可能對最終的效果會產生影響,如果不及時更新到詞庫裡,演算法就會“一臉懵逼”了。
因此,推薦在網上查詢或購買那些能隨時更新的詞庫,各種語種都有。
3.2 關鍵詞指標
前面已經說過,新聞特徵向量是該新聞的關鍵詞合集,那關鍵詞的重合度就是非常重要的衡量指標了。
那麼問題來了,如果兩條新聞的關鍵詞重合度達到80%,是否說明兩條新聞有80%的相關性呢?
其實不是,舉個例子:
(1)一條“廣州摩拜單車投放量激增”的新聞,主要講摩拜單車的投放情況,這篇新聞裡“摩拜單車”是一個非常高頻的詞彙,新聞在結尾有一句“最近廣州天氣不錯,大家可以騎單車出去散心”。因此“廣州天氣”這個關鍵詞也被收錄進了特徵向量。
(2)另外一條新聞“廣州回南天即將結束,天氣持續好轉”,這篇新聞結尾有一句“天氣好轉,大家可以騎個摩拜單車出門溜溜啦”,新聞裡面“廣州天氣”是非常高頻的詞彙,“摩拜單車”儘管被收錄,但只出現了一次。
這兩個新聞的關鍵詞雖然類似,講的卻是完全不同的內容,相關性很弱。如果只是看關鍵詞重合度,出現錯誤判斷的可能性就很高;所以特徵向量還需要有第二個關鍵詞的指標,叫新聞內頻率,稱之為TF(Term Frequency),衡量每個關鍵詞在新聞裡面是否高頻。
那麼問題來了,如果兩條新聞的關鍵詞重合度高,新聞中關鍵詞的頻率也相差無幾,是否說明相關性很強呢?
理論上是的,但又存在另外一種情況:如果我們新聞庫裡所有的新聞都是講廣州的,廣州天氣,廣州交通,廣州經濟,廣州體育等,他們都是講廣州相關的情況,關鍵詞都包含廣州,天河,越秀,海珠(廣州各區)等,並且有著類似的頻率,因此演算法很容易將它們判斷為強相關新聞;從地域角度講,這種相關性確實很強,但從內容類別層面,其實沒有太多相關性,如果我是一個體育迷,你給我推薦天氣,交通之類的內容,就沒多大意義了。
因此引入第三個關鍵詞的指標,即關鍵詞在在所有文件中出現的頻率的相反值,稱之為IDF(Inverse Document Frequency)。為什麼會是相反值?因為一個關鍵詞在某條新聞出現的頻率最大,在所有文件中出現的頻率越小,該關鍵詞對這條新聞的特徵標識作用越大。
這樣每個關鍵詞對新聞的作用就能被衡量出來即,這也就是著名的TF-IDF模型。
3.3 相關性演算法
做完分詞和關鍵詞指標後,每一篇新聞的特徵就能用關鍵詞的集合來標識了:
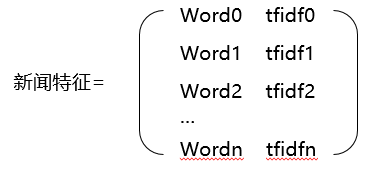
其中word0,1,2……n是新聞的所有關鍵詞,tfidf0,1,2……n則是每個關鍵詞的tfidf值。
兩個新聞的相似度就能通過重合的關鍵詞的tfidf值來衡量了。根據之前所學的知識,幾何中夾角餘弦可以用來衡量兩個向量的方向的差異性,因此在我們的演算法中使用夾角餘弦來計算新聞關鍵詞的相似度。夾角越小,相似度越高。
有了關鍵詞和各關鍵詞的tfidf之後,就可以計算新聞的相似度了。假設兩條新聞的特徵列表如下:
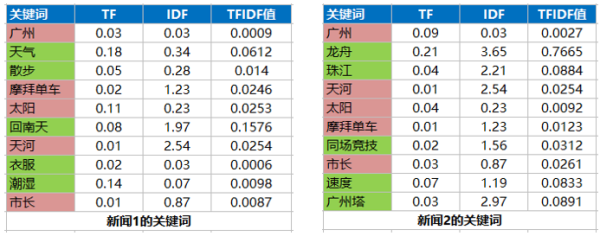
可以看到兩條新聞有5個重合的關鍵詞:廣州,摩拜單車,太陽,天河和市長,因此兩條新聞的相關性由這5個關鍵詞決定,計算方式如下:
得出兩條新聞的相關性最終值;用同樣的方法能得出一條新聞與新聞庫裡面所有內容的相關性。
3.4 使用者特徵
得到新聞特徵以後,還需要得到使用者特徵才能對兩者進行匹配和推薦,那怎麼獲得使用者特徵呢?
需要通過使用者的行為來獲得,使用者通過閱讀,點贊,評論,分享來表達自己對新聞內容的喜愛;跟熱度排名類似,我們對使用者的各種行為賦予一定的“喜愛分”,例如閱讀1分,點贊2分,評論5分等,這樣新聞特徵跟使用者行為結合後,就能得到使用者的特徵分。
而隨著使用者閱讀的新聞數越來越多,該使用者的標籤也越來越多,並且越發精準。
從而當我們拿到新聞的特徵後,就能與使用者的關鍵詞列表做匹配,得出新聞與使用者閱讀特徵的匹配度,做出個性化推薦。
3.5 其他運用
除了個性化推薦,基於內容的相關性演算法能精準地給出一篇新聞的相關推薦列表,對相關閱讀的實現非常有意義。此外,標籤系統對新聞分類的實現和提升準確性,也有重要的意義。
3.6 優缺點
基於內容的推薦演算法有幾個明顯優點:
-
對使用者數量沒有要求,無論日活幾千或是幾百萬,均可以採用;因此個性化推薦早期一般採用這種方式;
-
每個使用者的特徵都是由自己的行為來決定的,是獨立存在的,不會有互相干擾,因此惡意刷閱讀等新聞不會影響到推薦演算法。
而最主要的缺點就是確定性太強了,所有推薦的內容都是由使用者的閱讀歷史決定,所以沒辦法挖掘使用者的潛在興趣;也就是由於這一點,基於內容的推薦一般與其他推薦演算法同時存在。
四、基於使用者的協同推薦
終於,經過團隊的努力,你的產品已經有了大量活躍使用者了,這時候你開始不滿足於現有的演算法。雖然基於內容的推薦已經很精準了,但總是少了那麼一點性感。因為你所有給使用者的內容都是基於他們的閱讀習慣推薦的,沒能給使用者“不期而遇”的感覺。
於是,你就開始做基於使用者的協同過濾了。
基於使用者的協同過濾推薦演算法,簡單來講就是依據使用者A的閱讀喜好,為A找到與他興趣最接近的群體,所謂“人以群分”,然後把這個群體裡其他人喜歡的,但是A沒有閱讀過的內容推薦給A;舉例我是一個足球迷,系統找到與我類似的使用者都是足球的重度閱讀者,但與此同時,這些“足球群體”中有一部分人有看NBA新聞的習慣,系統就可能會給我推薦NBA內容,很可能我也對NBA也感興趣,這樣我在後臺的興趣圖譜就更完善了。
4.1 使用者群體劃分
做基於使用者的協同過濾,首先就要做使用者的劃分,可以從三方面著手:
(1)外部資料的借用
這裡使用社交平臺數據的居多,現在產品的登入體系一般都借用第三方社媒的登入體系,如國外的Facebook、Twitter,國內的微信、微博,借用第三方賬戶的好處多多,例如降低門檻,方便傳播等,還能對個性化推薦起到重要作用。因為第三方賬戶都是授權獲取部分使用者資訊的,往往包括性別,年齡,工作甚至社交關係等,這些資訊對使用者群劃分很有意義。
此外還有其他的一些資料也能借用,例如IP地址,手機語種等。
使用這些資料,你很容易就能得到一個使用者是北京的還是上海的,是大學生還是創業者,並依據這些屬性做準確的大類劃分。比如一篇行業投資分析出來後,“上海創業圈”這個群體80%的使用者都看過,那就可以推薦給剩下的20%。
(2)產品內主動詢問
常見在產品首次啟動的時候,彈框詢問使用者是男是女,職業等,這樣能對內容推薦的冷啟動提供一些幫助。但總體來說,價效比偏低,只能詢問兩三個問題並對使用者的推薦內容做非常粗略的劃分,同時要避免打擾到使用者;這種做法算是基於使用者個性化的雛形。
(3)對比使用者特徵
前文已經提到過,新聞的特徵加使用者的閱讀資料能得到使用者的特徵,那就可以通過使用者特徵的相似性來劃分群體。
4.2 內容推薦實施
我們結合一個很小的例項來了解使用者協同過濾的原理,包括如何計算使用者之間的相似性和如何做出推薦。假設有A、B、C、D和E共5個使用者,他們各自閱讀了幾篇新聞並做出了閱讀,贊,收藏,評論,分享操作,我們對這幾種行為賦予的分數分別為1分、2分、3分、4分和5分,這樣使用者對每條新聞都有自己的得分,其中“-”表示未閱讀,得分如下:
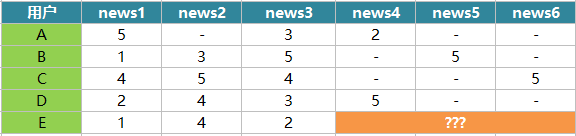
接下來,我們需要給使用者E推薦4,5,6中的哪一篇?
使用者的閱讀特徵向量由使用者所有的閱讀資料決定,我們以使用者E閱讀過的新聞資料作為參考標準,來找到與E最相似的使用者。
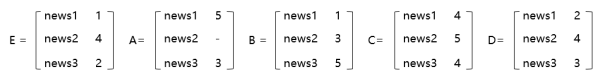
多維向量的距離需要通過歐幾里得距離公式來計算,數值越小,向量距離約接近。
算出結果:
-
distance(E,A)=4.123 (使用者A沒有閱讀news2,因此news2的資料不能用來計算與使用者E的相似度,這裡取1,3)
-
distance(E,B)=3.162
-
distance(E,C)=3.742
-
distance(E,D)=1.414
因此得出結果:使用者D是與使用者E閱讀喜好最接近的那個,應該優先歸為同一類使用者。最終結論根據使用者D的閱讀資料,優先推薦news4。
4.3 內容選取
我們通過閱讀特徵向量把使用者做群體劃分後,接下來就是如何獲取新聞推薦的優先順序。上面的例子裡面只需要選出一個相似使用者,並且使用者A,B,C,D都只閱讀news4,5,6中的一條,所以比較簡單,但現實情況中,同一個使用者群體閱讀的新聞多且隨機,使用者互動更是錯綜複雜,如何得出推薦新聞的優先順序呢?
假設使用者X在系統歸屬於群體A,這個群體有n個使用者,分別為A0,A1,A2……An,這些使用者的集合用S(X,n)表示。
-
首先,我們需要把集合中所有使用者互動過(閱讀,評論等)的新聞提取出來;
-
需要剔除掉使用者X已經看過的新聞,這些就不用再推薦了,剩下的新聞集合有m條,用N(X,m)來表示;
-
對餘下的新聞進行評分和相似度加權的計算,計算包括兩部分,一是使用者X與S(X,n) 每一個使用者的相似性,二是每個使用者對新聞集N(X,m)中每條新聞的喜好,這樣就能得到每條新聞相對於使用者X的最終得分;
-
將N(X,m)中的新聞列表按照得分高低的順序推薦給使用者。
4.4 優缺點
相比於基於內容的推薦演算法,基於使用者的協同過濾同樣優缺點明顯。
優點主要在於對分詞等演算法的精確度無太大要求,推薦都是基於使用者的行為資料去不斷學習和完善;同時能發現使用者的潛在閱讀興趣,能“製造驚喜”。
缺點則是啟動的門檻高,使用者量不夠時幾乎無法開展;並且學習量不夠時推薦結果較差。
五、總結
關於個性化推薦的演算法,在網上有很多資料,也有很多其他的實現方法,因為筆者瞭解也有限,所以也不敢描述。如有興趣可以自行搜尋。熱度和個性化推薦演算法,作為大部分內容型產品的核心賣點之一,依然在不斷地進化和完善中。沒有哪種演算法是完美的,甚至沒有哪種演算法是一定優於其他的,在實際使用中,很多產品都是多演算法結合去做好內容推薦。
而產品經理在演算法的實施中,絕對不是一句“我們要做個性化推薦”就完事的,必須深入演算法內部,對演算法的原理做深入瞭解,然後結合自己的產品特徵來部署和優化。
相關推薦
熱度演算法和個性化推薦
今日頭條的走紅帶動了“個性化推薦”的概念,自此之後,內容型的產品,個性化演算法就逐漸從賣點變為標配。伴隨著“機器學習”,“大資料”之類的熱詞和概念,產品的檔次瞬間提高了很多。而各種推薦演算法絕不僅僅是研發自己的任務,作為產品經理,必須深入到演算法內部,參與演算
基於Spark ALS演算法的個性化推薦
今天來使用spark中的ALS演算法做一個小推薦。需要資料的話可以點選檢視,在文末點選閱讀原文即可獲取。其實在R中還有一個包可以做推薦,那就是recommenderlab。如果資料量不大的時候可以使用r
個性化推薦演算法------基於內容的推薦和基於鄰域的協同過濾
這篇文章主要討論了個性推薦演算法中,基於內容推薦和基於鄰域的協同過濾推薦的分析比較。 資料集:使用者對電影的歷史評價記錄,只有喜歡與不喜歡,喜歡用1表示,不喜歡用2表示,格式如下: 使用者歷史電影評分
機器學習的13種演算法和4種學習方法,推薦給大家
機器學習的演算法很多。很多時候困惑人們都是,很多演算法是一類演算法,而有些演算法又是從其他演算法中延伸出來的。這裡,我們從兩個方面來給大家介紹,第一個方面是學習的方式,第二個方面是演算法的分類。 一、4大主要學習方式 1.監督式學習 在監督式學習下,輸入資料被稱為“訓練資料”,
BAT大牛親授-個性化推薦演算法實戰
第1章 個性化推薦演算法綜述 個性化推薦演算法綜述部分,主要介紹個性化推薦演算法綜述,本課程內容大綱以及本課程所需要準備的程式設計環境與基礎知識。 1-1 個性化推薦演算法綜述 1-2 個性化召回演算法綜述
BAT大牛親授--個性化推薦演算法實戰
第1章 個性化推薦演算法綜述個性化推薦演算法綜述部分,主要介紹個性化推薦演算法綜述,本課程內容大綱以及本課程所需要準備的程式設計環境與基礎知識。 第2章 基於鄰域的個性化召回演算法LFM本章節重點介紹一種基於鄰域的個性化召回演算法,LFM。從LFM演算法的理論知識與數學原理進行介紹。並結合公開資料集,程式碼
BAT大牛親授 個性化推薦演算法實戰
第1章 個性化推薦演算法綜述個性化推薦演算法綜述部分,主要介紹個性化推薦演算法綜述,本課程內容大綱以及本課程所需要準備的程式設計環境與基礎知識。 第2章 基於鄰域的個性化召回演算法LFM本章節重點介紹一種基於鄰域的個性化召回演算法,LFM。從LFM演算法的理論知識與數學原理進行介紹。並結合公開資料集,程式碼
BAT大牛親授--個性化推薦演算法實戰完整資源
BAT大牛親授--個性化推薦演算法實戰完整資源 獲取資源請掃描二維碼 回覆BAT大牛 獲取資源請掃描二維碼 回覆BAT大牛 獲取資源請掃描二維碼 回覆BAT大牛 第1章 個性化推薦演算法綜述 個性化推薦演算法綜述部分,主要介紹個性化推薦演算法綜述,本課程內容大綱
詳解個性化推薦五大最常用演算法
推薦系統,是當今網際網路背後的無名英雄。 我們在某寶首頁看見的商品,某條上讀到的新聞,甚至在各種地方看見的廣告,都有賴於它。 昨天,一個名為Stats&Bots的部落格詳解了構建推薦系統的五種方法。 量子位編譯如下: 現在,許多公司都在用大資料來向用戶進行
基於使用者的推薦演算法和基於商品的推薦演算法
基於使用者的協同過濾 如圖1所示,在推薦系統中,用m×n的打分矩陣表示使用者對物品的喜好情況,一般用打分來表示使用者對商品的喜好程度,分數越高表示該使用者對這個商品越感興趣,而數值為空表示不瞭解或是沒有買過這個商品。 圖1 用於個性化推薦系統的打分矩陣 如圖2所示
推薦演算法和機器學習系列
【編者按】推薦系統在各種系統中廣泛使用,推薦演算法則是其中最核心的技術點,InfoQ接下來將會策劃系列文章來為讀者深入介紹。推薦演算法綜述分文五個部分,本文作為第一篇,將會簡要介紹推薦系統演算法的主要種類。其中包括演算法的簡要描述、典型的輸入、不同的細分型別以及其優點和缺點。
什麼是推薦演算法和主要方法
在現今的推薦技術和演算法中,最被大家廣泛認可和採用的就是基於協同過濾的推薦方法。 標題 ##1. 什麼是推薦演算法 推薦演算法最早在1992年就提出來了,但是火起來實際上是最近這些年的事情,因為網際網路的爆發,有了更大的資料量可以供我們使用,推薦演算法才有了
演算法和資料結構書籍推薦
資料結構 資料結構與演算法分析_Java語言描述(第2版) 演算法 計算機演算法基礎 演算法導論 程式設計之法_面試和演算法心得 coding 程式設計師程式碼面試指南_IT名企演算法與資料結構題目最優解 LeetCode/LintCode
個性化推薦演算法的理論建立
1.例子解析(item協同過濾) 1.1推薦思路 假如有A,B,C,D四個使用者,且每個使用者對a,b,c,d四個專案有過點選瀏覽,關係圖如下: 首先該演算法的基本思想是協同過濾,協同過濾的方式是基於使用者行為的,如果喜
推薦演算法概述:基於內容的推薦演算法、協同過濾推薦演算法和基於知識的推薦演算法
所謂推薦演算法就是利用使用者的一些行為,通過一些數學演算法,推測出使用者可能喜歡的東西。推薦演算法主要分為兩種 1. 基於內容的推薦 基於內容的資訊推薦方法的理論依據主要來自於資訊檢索和
今日頭條個性化推薦演算法
要點: 1. 協同過濾 基於投票的規則,若某個使用者組對某篇文章投票較多,則判斷該使用者組對該篇文章較感興趣 2. 使用者屬於多組情況處理 若某個使用者屬於多個組,則採用加權平均的方式選取得分最高的文章進行推薦,權重係數利用邏輯迴歸確定。 w1(組的權重係數)*該組對某文章
如何實現基於內容和使用者畫像的個性化推薦
基於內容和使用者畫像的個性化推薦,有兩個實體:內容和使用者。需要有一個聯絡這兩者的東西,即為標籤。內容轉換為標籤即為內容特徵化,使用者則稱為使用者特徵化。 因此,對於此種推薦,主要分為以下幾個關鍵部分: 標籤庫 內容特徵化 使用者特徵化 隱語義推薦 綜合上面講述的各個部分即可實現一個基於內容和使
Slope one—個性化推薦中最簡潔的協同過濾演算法
Slope One 是一系列應用於 協同過濾的演算法的統稱。由 Daniel Lemire和Anna Maclachlan於2005年發表的論文中提出。 [1]有爭議的是,該演算法堪稱基於專案評價的non-trivial 協同過濾演算法最簡潔的形式。該系列演算法的簡潔特
個性化推薦演算法 綜述
隨著網際網路的迅速發展,接入網際網路的網頁與伺服器數量也以指數形式迅猛增長。網際網路的發展,使得海量資訊以飛快的更新速度在我們眼前不斷呈現。例如,卓越亞馬遜上存在著上千萬的圖書,NetFlix上有數萬部電影。如此眾多的資訊,遍歷一遍都變得十分艱難,更何況要在其中找到自己感興趣的部分。傳統的搜尋策略,為每個
購物網站的推薦演算法-個性化推薦演算法中如何處理買了還推
1. 引言 目前在工業界推薦中廣泛使用的協同過濾演算法(Collaborative Filtering)主要分為user-based和item-based兩種型別,user-based多用於挖掘那些有共同興趣的小團體;而item-based側重於挖掘item之間