
【資料結構】LinkedList原理及實現學習總結
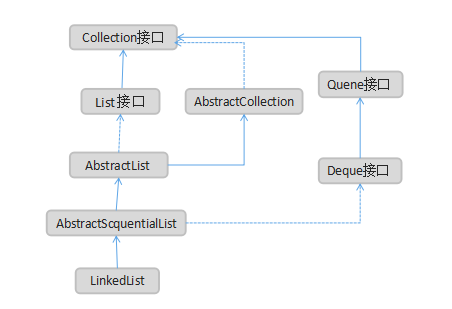
一、LinkedList實現原理概述
LinkedList 和 ArrayList 一樣,都實現了 List 介面,但其內部的資料結構有本質的不同。LinkedList 是基於連結串列實現的(通過名字也能區分開來),所以它的插入和刪除操作比 ArrayList 更加高效。但也是由於其為基於連結串列的,所以隨機訪問的效率要比 ArrayList 差。
二、LinkedList類定義
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E - LinkedList 是一個繼承於AbstractSequentialList的雙向連結串列。它也可以被當作堆疊、佇列或雙端佇列進行操作。
- LinkedList 實現 List 介面,能對它進行佇列操作。
- LinkedList 實現 Deque 介面,即能將LinkedList當作雙端佇列使用。
- LinkedList 實現了Cloneable介面,即覆蓋了函式clone(),能克隆。
- LinkedList 實現java.io.Serializable介面,這意味著LinkedList支援序列化,能通過序列化去傳輸。
- LinkedList 是非同步的。
為什麼要繼承自AbstractSequentialList ?
AbstractSequentialList 實現了get(int index)、set(int index, E element)、add(int index, E element) 和 remove(int index)這些骨幹性函式。降低了List介面的複雜度。這些介面都是隨機訪問List的,LinkedList是雙向連結串列;既然它繼承於AbstractSequentialList,就相當於已經實現了“get(int index)這些介面”。
此外,我們若需要通過AbstractSequentialList自己實現一個列表,只需要擴充套件此類,並提供 listIterator() 和 size() 方法的實現即可。若要實現不可修改的列表,則需要實現列表迭代器的 hasNext、next、hasPrevious、previous 和 index 方法即可。
LinkedList的類圖關係:
三、LinkedList資料結構原理
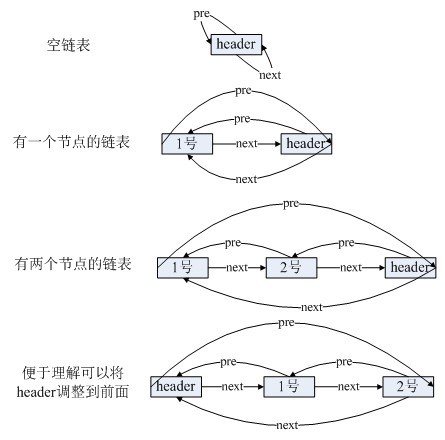
LinkedList底層的資料結構是基於雙向迴圈連結串列的,且頭結點中不存放資料,如下:
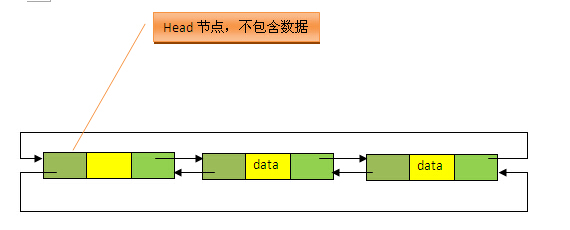
既然是雙向連結串列,那麼必定存在一種資料結構——我們可以稱之為節點,節點例項儲存業務資料,前一個節點的位置資訊和後一個節點位置資訊,如下圖所示:

四、私有屬性
LinkedList中之定義了兩個屬性:
private transient Entry<E> header = new Entry<E>(null, null, null);2 private transient int size = 0;header是雙向連結串列的頭節點,它是雙向連結串列節點所對應的類Entry的例項。Entry中包含成員變數: previous, next, element。其中,previous是該節點的上一個節點,next是該節點的下一個節點,element是該節點所包含的值。
size是雙向連結串列中節點例項的個數。
首先來了解節點類Entry類的程式碼。
private static class Entry<E> {
E element;
Entry<E> next;
Entry<E> previous;
Entry(E element, Entry<E> next, Entry<E> previous) {
this.element = element;
this.next = next;
this.previous = previous;
}
}節點類很簡單,element存放業務資料,previous與next分別存放前後節點的資訊(在資料結構中我們通常稱之為前後節點的指標)。
}
五、構造方法
LinkedList提供了兩個構造方法。
public LinkedList() {
header.next = header.previous = header;
}
public LinkedList(Collection<? extends E> c) {
this();
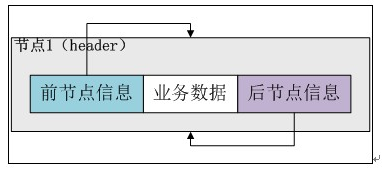
addAll(c);第一個構造方法不接受引數,將header例項的previous和next全部指向header例項(注意,這個是一個雙向迴圈連結串列,如果不是迴圈連結串列,空連結串列的情況應該是header節點的前一節點和後一節點均為null),這樣整個連結串列其實就只有header一個節點,用於表示一個空的連結串列。
執行完建構函式後,header例項自身形成一個閉環,如下圖所示:
第二個構造方法接收一個Collection引數c,呼叫第一個構造方法構造一個空的連結串列,之後通過addAll將c中的元素全部新增到連結串列中。
六、元素新增
下面說明雙向連結串列新增元素add()的原理:
// 將元素(E)新增到LinkedList中
public boolean add(E e) {
// 將節點(節點資料是e)新增到表頭(header)之前。
// 即,將節點新增到雙向連結串列的末端。 addBefore(e, header);
return true;
}
public void add(int index, E element) {
addBefore(element, (index==size ? header : entry(index)));
}
private Entry<E> addBefore(E e, Entry<E> entry) {
Entry<E> newEntry = new Entry<E>(e, entry, entry.previous);
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
size++;
modCount++;
return newEntry;
}addBefore(E e,Entry entry)方法是個私有方法,所以無法在外部程式中呼叫(當然,這是一般情況,你可以通過反射上面的還是能呼叫到的)。
addBefore(E e,Entry entry)先通過Entry的構造方法建立e的節點newEntry(包含了將其下一個節點設定為entry,上一個節點設定為entry.previous的操作,相當於修改newEntry的“指標”),之後修改插入位置後newEntry的前一節點的next引用和後一節點的previous引用,使連結串列節點間的引用關係保持正確。之後修改和size大小和記錄modCount,然後返回新插入的節點。
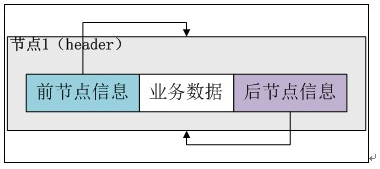
下面分解“新增第一個資料”的步驟:
第一步:初始化後LinkedList例項的情況:
第二步:初始化一個預新增的Entry例項(newEntry)。
Entry newEntry = newEntry(e, entry, entry.previous);
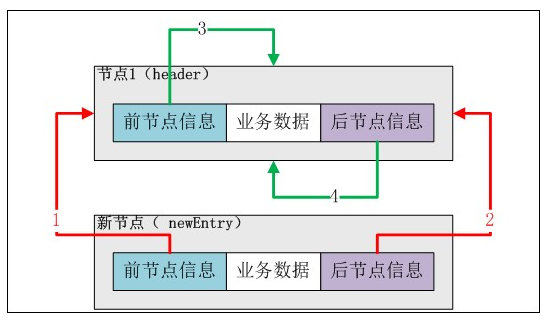
第三步:調整新加入節點和頭結點(header)的前後指標。
newEntry.previous.next = newEntry;
newEntry.previous即header,newEntry.previous.next即header的next指向newEntry例項。在上圖中應該是“4號線”指向newEntry。
newEntry.next.previous = newEntry;
newEntry.next即header,newEntry.next.previous即header的previous指向newEntry例項。在上圖中應該是“3號線”指向newEntry。
調整後如下圖所示:
圖——加入第一個節點後LinkedList示意圖
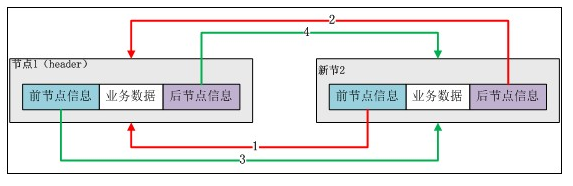
下面分解“新增第二個資料”的步驟:
第一步:新建節點。
圖——新增第二個節點
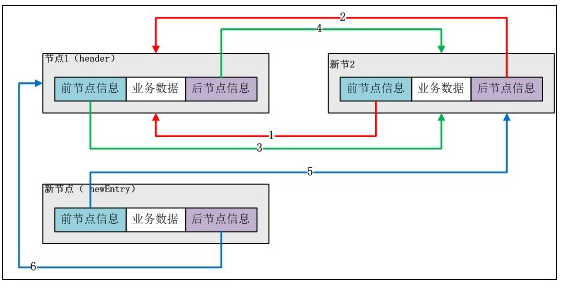
第二步:調整新節點和頭結點的前後指標資訊。
圖——調整前後指標資訊
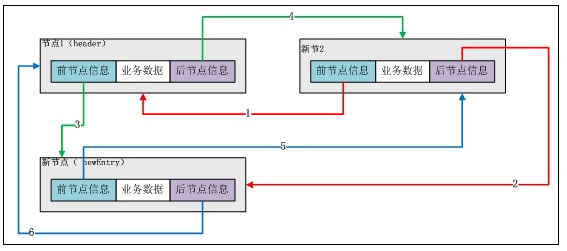
新增後續資料情況和上述一致,LinkedList例項是沒有容量限制的。
總結,addBefore(E e,Entry entry)實現在entry之前插入由e構造的新節點。而add(E e)實現在header節點之前插入由e構造的新節點。為了便於理解,下面給出插入節點的示意圖。
public void addFirst(E e) {
addBefore(e, header.next);
}
public void addLast(E e) {
addBefore(e, header);
}看上面的示意圖,結合addBefore(E e,Entry entry)方法,很容易理解addFrist(E e)只需實現在header元素的下一個元素之前插入,即示意圖中的一號之前。addLast(E e)只需在實現在header節點前(因為是迴圈連結串列,所以header的前一個節點就是連結串列的最後一個節點)插入節點(插入後在2號節點之後)。
七、刪除資料remove()
public E remove(int index) {
Entry e = get(index);
remove(e);
return e.element;
}
private void remove(E e) {
if (e == header)
throw new NoSuchElementException();
// 將前一節點的next引用賦值為e的下一節點
e.previous.next = e.next;
// 將e的下一節點的previous賦值為e的上一節點
e.next.previous = e.previous;
// 上面兩條語句的執行已經導致了無法在連結串列中訪問到e節點,而下面解除了e節點對前後節點的引用
e.next = e.previous = null;
// 將被移除的節點的內容設為null
e.element = null;
// 修改size大小
size--;
}由於刪除了某一節點因此調整相應節點的前後指標資訊,如下:
e.previous.next = e.next;//預刪除節點的前一節點的後指標指向預刪除節點的後一個節點。
e.next.previous = e.previous;//預刪除節點的後一節點的前指標指向預刪除節點的前一個節點。
清空預刪除節點:
e.next = e.previous = null;
e.element = null;
交給gc完成資源回收,刪除操作結束。
與ArrayList比較而言,LinkedList的刪除動作不需要“移動”很多資料,從而效率更高。
八、資料獲取get()
Get(int)方法的實現在remove(int)中已經涉及過了。首先判斷位置資訊是否合法(大於等於0,小於當前LinkedList例項的Size),然後遍歷到具體位置,獲得節點的業務資料(element)並返回。
注意:為了提高效率,需要根據獲取的位置判斷是從頭還是從尾開始遍歷。
// 獲取雙向連結串列中指定位置的節點
private Entry<E> entry(int index) {
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+size);
Entry<E> e = header;
// 獲取index處的節點。
// 若index < 雙向連結串列長度的1/2,則從前先後查詢;
// 否則,從後向前查詢。
if (index < (size >> 1)) {
for (int i = 0; i <= index; i++)
e = e.next;
} else {
for (int i = size; i > index; i--)
e = e.previous;
}
return e;
}注意細節:位運算與直接做除法的區別。先將index與長度size的一半比較,如果index
九、 清除資料clear()
public void clear() {
Entry<E> e = header.next;
// e可以理解為一個移動的“指標”,因為是迴圈連結串列,所以回到header的時候說明已經沒有節點了
while (e != header) {
// 保留e的下一個節點的引用
Entry<E> next = e.next;
// 解除節點e對前後節點的引用
e.next = e.previous = null;
// 將節點e的內容置空
e.element = null;
// 將e移動到下一個節點
e = next;
}
// 將header構造成一個迴圈連結串列,同構造方法構造一個空的LinkedList
header.next = header.previous = header;
// 修改size
size = 0;
modCount++;
}十、資料包含 contains(Object o)
public boolean contains(Object o) {
return indexOf(o) != -1;
}
// 從前向後查詢,返回“值為物件(o)的節點對應的索引” 不存在就返回-1
public int indexOf(Object o) {
int index = 0;
if (o==null) {
for (Entry e = header.next; e != header; e = e.next) {
if (e.element==null)
return index;
index++;
}
} else {
for (Entry e = header.next; e != header; e = e.next) {
if (o.equals(e.element))
return index;
index++;
}
}
return -1;
}indexOf(Object o)判斷o連結串列中是否存在節點的element和o相等,若相等則返回該節點在連結串列中的索引位置,若不存在則放回-1。
contains(Object o)方法通過判斷indexOf(Object o)方法返回的值是否是-1來判斷連結串列中是否包含物件o。
十一、資料複製clone()與toArray()
clone()
public Object clone() {
LinkedList<E> clone = null;
try {
clone = (LinkedList<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
clone.header = new Entry<E>(null, null, null);
clone.header.next = clone.header.previous = clone.header;
clone.size = 0;
clone.modCount = 0;
for (Entry<E> e = header.next; e != header; e = e.next)
clone.add(e.element);
return clone;
}呼叫父類的clone()方法初始化物件連結串列clone,將clone構造成一個空的雙向迴圈連結串列,之後將header的下一個節點開始將逐個節點新增到clone中。最後返回克隆的clone物件。
toArray()
public Object[] toArray() {
Object[] result = new Object[size];
int i = 0;
for (Entry<E> e = header.next; e != header; e = e.next)
result[i++] = e.element;
return result;
}建立大小和LinkedList相等的陣列result,遍歷連結串列,將每個節點的元素element複製到陣列中,返回陣列。
toArray(T[] a)
public <T> T[] toArray(T[] a) {
if (a.length < size)
a = (T[])java.lang.reflect.Array.newInstance(
a.getClass().getComponentType(), size);
int i = 0;
Object[] result = a;
for (Entry<E> e = header.next; e != header; e = e.next)
result[i++] = e.element;
if (a.length > size)
a[size] = null;
return a;
}先判斷出入的陣列a的大小是否足夠,若大小不夠則拓展。這裡用到了發射的方法,重新例項化了一個大小為size的陣列。之後將陣列a賦值給陣列result,遍歷連結串列向result中新增的元素。最後判斷陣列a的長度是否大於size,若大於則將size位置的內容設定為null。返回a。
從程式碼中可以看出,陣列a的length小於等於size時,a中所有元素被覆蓋,被拓展來的空間儲存的內容都是null;若陣列a的length的length大於size,則0至size-1位置的內容被覆蓋,size位置的元素被設定為null,size之後的元素不變。
為什麼不直接對陣列a進行操作,要將a賦值給result陣列之後對result陣列進行操作?
十二、遍歷資料:Iterator()
LinkedList的Iterator
除了Entry,LinkedList還有一個內部類:ListItr。
ListItr實現了ListIterator介面,可知它是一個迭代器,通過它可以遍歷修改LinkedList。
在LinkedList中提供了獲取ListItr物件的方法:listIterator(int index)。
public ListIterator<E> listIterator(int index) {
return new ListItr(index);
}該方法只是簡單的返回了一個ListItr物件。
LinkedList中還有通過整合獲得的listIterator()方法,該方法只是呼叫了listIterator(int index)並且傳入0。
十三、