
HDFS小檔案處理及解決方案
阿新 • • 發佈:2019-01-08
小檔案為什麼會成為問題?
小檔案的解決方案包括哪些?
有沒有自己的解決方案?
Hadoop Archive具體是如何處理小檔案的?
Sequence file是如何解決小檔案的?
CombineFileInputFormat是如何解決小檔案的?

1、 概述
小檔案是指檔案size小於HDFS上block大小的檔案。這樣的檔案會給hadoop的擴充套件性和效能帶來嚴重問題。首先,在HDFS中,任何block,檔案或者目錄在記憶體中均以物件的形式儲存,每個物件約佔150byte,如果有1000 0000個小檔案,每個檔案佔用一個block,則namenode大約需要2G空間。如果儲存1億個檔案,則namenode需要20G空間(見參考資料[1][4][5])。這樣namenode記憶體容量嚴重製約了叢集的擴充套件。 其次,訪問大量小檔案速度遠遠小於訪問幾個大檔案。HDFS最初是為流式訪問大檔案開發的,如果訪問大量小檔案,需要不斷的從一個datanode跳到另一個datanode,嚴重影響效能。最後,處理大量小檔案速度遠遠小於處理同等大小的大檔案的速度。每一個小檔案要佔用一個slot,而task啟動將耗費大量時間甚至大部分時間都耗費在啟動task和釋放task上。 本文首先介紹了hadoop自帶的解決小檔案問題的方案(以工具的形式提供),包括Hadoop Archive,Sequence file和CombineFileInputFormat;然後介紹了兩篇從系統層面解決HDFS小檔案的論文,一篇是中科院計算所2009年發表的,用以解決HDFS上儲存地理資訊小檔案的方案;另一篇是IBM於2009年發表的,用以解決HDFS上儲存ppt小檔案的方案。
2、 HDFS檔案讀寫流程
3、 Hadoop自帶的解決方案
4、 小檔案問題解決方案 上一節中提到的方案均需要使用者自己編寫程式,每隔一段時間對小檔案進行merge以便減少小檔案數量。那麼能不能直接將小檔案處理模組嵌到HDFS中,以便自動識別使用者上傳的小檔案,然後自動對它們進行merge呢? 本節介紹了兩篇論文針試圖在系統層面解決HDFS小檔案問題。這兩篇論文對不同的應用提出瞭解決方案,實際上思路類似:在原有HDFS基礎上新增一個小檔案處理模組,當一個檔案到達時,判斷該檔案是否屬於小檔案,如果是,則交給小檔案處理模組處理,否則,交給通用檔案處理模組處理。小檔案處理模組的設計思想是,先將很多小檔案合併成一個大檔案,然後為這些小檔案建立索引,以便進行快速存取和訪問。 論文[4]針對WebGIS系統的特點提出瞭解決HDFS小檔案儲存的方案。WebGIS是結合web和地理資訊系統(GIS)而誕生的一種新系統。在WebGIS中,為了使瀏覽器和伺服器之間傳輸的資料量儘可能地少,資料通常被切分成KB的小檔案儲存在分散式檔案系統中。論文結合WebGIS中資料相關性特徵,將儲存相鄰地理位置資訊的小檔案合併成一個大的檔案,併為這些小檔案建立索引以便對小檔案進行存取。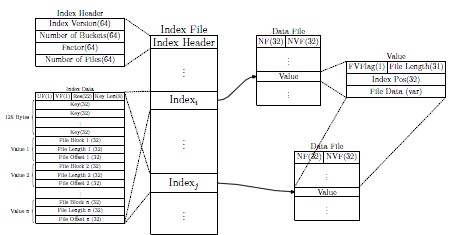
該論文將size小於16MB的檔案當做小檔案,需將它們合併成64MB(預設的block size),並建立索引,索引結構和檔案儲存方式見上圖。索引方式是一般的定長hash索引。 論文[5]針對Bluesky系統(http://www.bluesky.cn/)的特點提出瞭解決HDFS小檔案儲存的方案。Bluesky是中國電子教學共享系統,裡面的ppt檔案和視訊均存放在HDFS上。該系統的每個課件由一個ppt檔案和幾張該ppt檔案的預覽快照組成。當用戶請求某頁ppt時,其他相關的ppt可能在接下來的時間內也會被檢視,因而檔案的訪問具有相關性和本地性。本文主要有2個idea:第一,將屬於同一個課件的檔案合併成一個大檔案,以提高小檔案儲存效率。第二,提出了一種two-level prefetching機制以提高小檔案讀取效率,即索引檔案預取和資料檔案預取。索引檔案預取是指當用戶訪問某個檔案時,該檔案所在的block對應的索引檔案被載入到記憶體中,這樣,使用者訪問這些檔案時不必再與namenode互動了。資料檔案預取是指使用者訪問某個檔案時,將該檔案所在課件中的所有檔案載入到記憶體中,這樣,如果使用者繼續訪問其他檔案,速度會明顯提高。 下圖展示的是在BlueSky中上傳檔案的過程: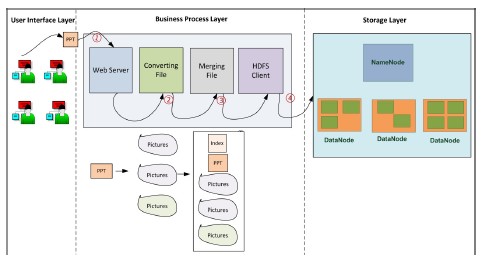
下圖展示的是在BlueSky中閱覽檔案的過程:
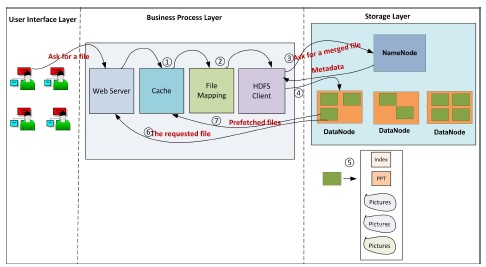
5、 總結 Hadoop目前還沒有一個系統級的通用的解決HDFS小檔案問題的方案。它自帶的三種方案,包括Hadoop Archive,Sequence file和CombineFileInputFormat,需要使用者根據自己的需要編寫程式解決小檔案問題;而第四節提到的論文均是針對特殊應用提出的解決方案,沒有形成一個比較通用的技術方案。
小檔案的解決方案包括哪些?
有沒有自己的解決方案?
Hadoop Archive具體是如何處理小檔案的?
Sequence file是如何解決小檔案的?
CombineFileInputFormat是如何解決小檔案的?
1、 概述
小檔案是指檔案size小於HDFS上block大小的檔案。這樣的檔案會給hadoop的擴充套件性和效能帶來嚴重問題。首先,在HDFS中,任何block,檔案或者目錄在記憶體中均以物件的形式儲存,每個物件約佔150byte,如果有1000 0000個小檔案,每個檔案佔用一個block,則namenode大約需要2G空間。如果儲存1億個檔案,則namenode需要20G空間(見參考資料[1][4][5])。這樣namenode記憶體容量嚴重製約了叢集的擴充套件。 其次,訪問大量小檔案速度遠遠小於訪問幾個大檔案。HDFS最初是為流式訪問大檔案開發的,如果訪問大量小檔案,需要不斷的從一個datanode跳到另一個datanode,嚴重影響效能。最後,處理大量小檔案速度遠遠小於處理同等大小的大檔案的速度。每一個小檔案要佔用一個slot,而task啟動將耗費大量時間甚至大部分時間都耗費在啟動task和釋放task上。 本文首先介紹了hadoop自帶的解決小檔案問題的方案(以工具的形式提供),包括Hadoop Archive,Sequence file和CombineFileInputFormat;然後介紹了兩篇從系統層面解決HDFS小檔案的論文,一篇是中科院計算所2009年發表的,用以解決HDFS上儲存地理資訊小檔案的方案;另一篇是IBM於2009年發表的,用以解決HDFS上儲存ppt小檔案的方案。
2、 HDFS檔案讀寫流程
3、 Hadoop自帶的解決方案
4、 小檔案問題解決方案 上一節中提到的方案均需要使用者自己編寫程式,每隔一段時間對小檔案進行merge以便減少小檔案數量。那麼能不能直接將小檔案處理模組嵌到HDFS中,以便自動識別使用者上傳的小檔案,然後自動對它們進行merge呢? 本節介紹了兩篇論文針試圖在系統層面解決HDFS小檔案問題。這兩篇論文對不同的應用提出瞭解決方案,實際上思路類似:在原有HDFS基礎上新增一個小檔案處理模組,當一個檔案到達時,判斷該檔案是否屬於小檔案,如果是,則交給小檔案處理模組處理,否則,交給通用檔案處理模組處理。小檔案處理模組的設計思想是,先將很多小檔案合併成一個大檔案,然後為這些小檔案建立索引,以便進行快速存取和訪問。 論文[4]針對WebGIS系統的特點提出瞭解決HDFS小檔案儲存的方案。WebGIS是結合web和地理資訊系統(GIS)而誕生的一種新系統。在WebGIS中,為了使瀏覽器和伺服器之間傳輸的資料量儘可能地少,資料通常被切分成KB的小檔案儲存在分散式檔案系統中。論文結合WebGIS中資料相關性特徵,將儲存相鄰地理位置資訊的小檔案合併成一個大的檔案,併為這些小檔案建立索引以便對小檔案進行存取。
該論文將size小於16MB的檔案當做小檔案,需將它們合併成64MB(預設的block size),並建立索引,索引結構和檔案儲存方式見上圖。索引方式是一般的定長hash索引。 論文[5]針對Bluesky系統(http://www.bluesky.cn/)的特點提出瞭解決HDFS小檔案儲存的方案。Bluesky是中國電子教學共享系統,裡面的ppt檔案和視訊均存放在HDFS上。該系統的每個課件由一個ppt檔案和幾張該ppt檔案的預覽快照組成。當用戶請求某頁ppt時,其他相關的ppt可能在接下來的時間內也會被檢視,因而檔案的訪問具有相關性和本地性。本文主要有2個idea:第一,將屬於同一個課件的檔案合併成一個大檔案,以提高小檔案儲存效率。第二,提出了一種two-level prefetching機制以提高小檔案讀取效率,即索引檔案預取和資料檔案預取。索引檔案預取是指當用戶訪問某個檔案時,該檔案所在的block對應的索引檔案被載入到記憶體中,這樣,使用者訪問這些檔案時不必再與namenode互動了。資料檔案預取是指使用者訪問某個檔案時,將該檔案所在課件中的所有檔案載入到記憶體中,這樣,如果使用者繼續訪問其他檔案,速度會明顯提高。 下圖展示的是在BlueSky中上傳檔案的過程:
下圖展示的是在BlueSky中閱覽檔案的過程:
5、 總結 Hadoop目前還沒有一個系統級的通用的解決HDFS小檔案問題的方案。它自帶的三種方案,包括Hadoop Archive,Sequence file和CombineFileInputFormat,需要使用者根據自己的需要編寫程式解決小檔案問題;而第四節提到的論文均是針對特殊應用提出的解決方案,沒有形成一個比較通用的技術方案。
resource:http://www.aboutyun.com/thread-7391-1-1.html