
降維概述(I)
在現實世界中,很多事物被表示為高維資料——如語音訊號,影象,視訊,文字文件,手寫字母或數字,指紋和高光譜影象等。 我們通常需要分析和處理大量的資料,For instance, 我們需要鑑別person‘s fingerprint, 通過keyword在網路中搜索文件,去發現影象中某些潛在的模式,從視訊中跟蹤物體等等。 To complete these tasks, we develop systems to process data。 但是,由於資料分佈在高維,直接處理會非常複雜和不穩定,以至於 infeasible. 實際上,很多systems只在低維空間中有效。當資料的維度超過了系統處理的限度,資料將無法被處理。因此,為了在這些systems中處理高維資料,必須對資料降維。
降維的典型事件:
- Fingerprint identification 指紋識別
- Face recognition
- Hyperspectral image analysis/processing 高光譜影象分析/處理
- Text document classification/search
- Data visualization
- Data feature extraction資料特徵提取

High Dimension Data Acquisition 高維資料採集
In dimensionality reduction (DR), 一個object通常轉換為一個向量(also called a point), 然後,這個object集合變成一個數據集,這個資料集是包含所有object的同維向量。Geometrically, 一個數據集在歐式空間中表現為一個點群(point cloud)。根據資料處理的目標(the goals of the data processing),一個object集合可能會轉換為多個數據集。下面給出一些轉換例項:Collection of Images in Face Recognition
人臉識別演算法基於面部表情資料集(facial databases),一個典型的facial databases包含大量來自不同人的facial images,每個人的影象可能處於不同的光照條件,不同的姿態,表情以及不同的年齡。在一個數據集中,所有的影象大小(size)或者說是解析度(resolution)相同。下圖給出了從一個facial databases資料集中提取的部分影象,這些影象可以在www.cs.nyu.edu/˜roweis/data.html中下載:

通常,facial images可以是灰度圖或者是彩色圖。在DR中,將每一個facial images轉換為一個向量。例如,每一個灰度影象的resolution是 N = m x n; 在可以把它拉成一個N維的向量。每個彩色影象可以轉換為一個N = m x n x 3 維的向量(彩色影象有R,G,B三個通道)。因此,一個有k張影象的資料集可以表示為

資料集
Handwriting Letters and Digits
手寫數字和字母轉換成向量的方法和人臉影象類似。在手寫數字和手寫字母的原始影象中,背景用二值數字1表示,字母和數字的部分是0,為了得到稀疏的表示,在轉換成二值向量的過程中,0和1互換,因此,一個手寫數字或字母的影象轉換成一個N維空間中的向量集合。下圖是手寫數字影象,背景值為0.

在處理時,一個集合通常表示為一個N x k的矩陣,每一列表示一副影象,k是影象的個數。類似於人臉影象,有兩個主要的處理任務:識別和分類。通過兩個引數分類這樣一個集合,我們將其降到兩維,而在識別中,我們要將這些數字影象從k維降到s維。
Text Documents
關鍵字查詢是網上的一種常見的搜尋方式,為了從搜尋結果中分類文件,通常將一個文件轉換成一個詞項--詞頻(term-frequency)向量,首先,建立一個關鍵字字典(keyword dictionary),包含n個關鍵字。計算每個文件中關鍵字出現的次數,為文件建立一個n維的term-frequency向量。During the vector conversion for a set of documents, we deploy a few filtering methods to omit empty documents, remove common terms, and sometimes stem the vocabulary.(資料集構建過程中的處理方法)For example, the toolkit developed by McCallum [2] can remove the common terms, and the algorithm developed by Porter [3] can be used to stem vocabulary (處理工具). Each document vector is then normalized(正則化處理)to a unit vector before further processing. The text document data of four newsgroups(新聞資料集展示): sci.crypt, sci.med, sci. space, and soc.religion.christian, and the data Reuters-21578: Text Categorization Test Collection Distribution 1.0 can be obtained from www.daviddlewis.com/resources/testcollections/reuters21578/.
Hyperspectral Images
高光譜影象通過高光譜感測器獲取,收集地理/地質geological/geographical影象資料作為一系列相同場景影象的集合, 每一副影象表示5-10 nm (nanometers)的電磁波譜的一個範圍(also called spectral band光譜帶),通常,一個高光譜影象的集合包含成百個範圍between 350 nm and 3500 nm的電磁波譜的窄小的spectral band。Hyperspectral images 通常形成一個三維的高光譜影象的立方體(or HSI cube) 用於影象處理和分析。如下圖:

令




一個物體的材質在raster cell中可以通過它的spectral curves識別出來。高光譜感測器掃描的一個空間域
典型的hyperspectral sensors的精確度測量有兩種方法。光譜解析度(which is the width of each band of the captured spectrum)和空間解析度(which is the size of a raster in an HSI)。因為高光譜感測器能夠收集大量非常窄的波段,這使得我們可以識別物體及時只捕獲了一小部分畫素。spatial resolution contributes to the effectiveness of spectral resolution,這一點很重要。例如,如果空間解析度很低,多個物體被捕獲到一個柵格里面,使得識別物體非常困難。另一方面,如果一個畫素覆蓋的區域太小,感測器捕獲的能量太低使得信噪比(signal-to-noise ratio)過高而不能保持特徵的可信度。為了獲得高空間解析度的影象高解析度(HRI)的黑白或彩色相機被整合到HRI系統中。沒有加入HRI的高光譜感測器只能捕獲每畫素一平方米的影象,而加入HRI的HSI感測器能捕獲每平方英寸一畫素的影象。
一些HSI資料是免費的,free HSI data的網站有:
- Jet Propulsion Laboratory, California Institute of Technology: aviris.jpl.nasa.gov/html/data.html
- L. Biehl: https://engineering.purdue.edu/∼biehl/MultiSpec/hyperspectral.html (Purdue University)
- Army Geospatial Center: www.agc.army.mil/Hypercube
 ,亦可以被認為是不同波段影象的集合
,亦可以被認為是不同波段影象的集合 ,這取決於影象處理的目標。
生成的HSI資料有其特殊的格式,通常包括一個頭檔案(with the extension .hdr)一個波長描述檔案(with the extension.wvl) ,一個數據檔案(without extension, or with the extension . dat)。所有這些檔案的檔名相同。The head file describes
how to read the raw data in the data file, and the wavelength description file provides the wavelength information for each band image.(每個檔案的作用)。
,這取決於影象處理的目標。
生成的HSI資料有其特殊的格式,通常包括一個頭檔案(with the extension .hdr)一個波長描述檔案(with the extension.wvl) ,一個數據檔案(without extension, or with the extension . dat)。所有這些檔案的檔名相同。The head file describes
how to read the raw data in the data file, and the wavelength description file provides the wavelength information for each band image.(每個檔案的作用)。
Curse of the Dimensionality維度災難
當我們處理高維資料時,我們會遇到維度災難,DR是避免它的一種方法。The term curse of the dimensionality was first coined by Bellman [4],用來描述當(數學)空間維度增加時,分析和組織高維空間(通常有成百上千維),因體積指數增加而遇到各種問題場景。這樣的難題在低維空間中不會遇到,如物理空間通常只用三維來建模。舉例來說,100個平均分佈的點能把一個單位區間以每個點距離不超過0.01取樣;而當維度增加到10後,如果以相鄰點距離不超過0.01小方格取樣一單位超正方體,則需要1020 個取樣點:所以,這個10維的超正方體也可以說是比單位區間大1018倍。(這個是Richard Bellman所舉的例子) 在很多領域中,如取樣、組合數學、機器學習和資料探勘都有提及到這個名字的現象。這些問題的共同特色是當維數提高時,空間的體積提高太快,因而可用資料變得很稀疏。稀疏性對於任何要求有統計學意義的方法而言都是一個問題,為了獲得在統計學上正確並且有可靠的結果,用來支撐這一結果所需要的資料量通常隨著維數的提高而呈指數級增長。而且,在組織和搜尋資料時也有賴於檢測物件區域,這些區域中的物件通過相似度屬性而形成分組。然而在高維空間中,所有的資料都很稀疏,從很多角度看都不相似,因而平常使用的資料組織策略變得極其低效。Volume of Cubes and Spheres 立方體和球體體積
當一個度量,如歐幾里德距離使用很多座標來定義時,不同的樣本對之間的距離已經基本上沒有差別。
一種用來描述高維歐幾里德空間的巨型性的方法是將超球體中半徑 和維數
和維數 的比例,和超立方體中邊長
的比例,和超立方體中邊長 和等值維數的比例相比較。
這樣一個球體的體積計算如下:
和等值維數的比例相比較。
這樣一個球體的體積計算如下:
立方體的體積計算如下: 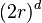
隨著空間維度的增加,相對於超立方體的體積來說,超球體的體積就變得微不足道了。這一點可以從當趨於無窮時比較前面的比例清楚地看出:
當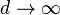 。
因此,在某種意義上,幾乎所有的高維空間都遠離其中心,或者從另一個角度來看,高維單元空間可以說是幾乎完全由超立方體的“邊角”所組成的,沒有“中部”,這對於理解卡方分佈是很重要的直覺理解。
給定一個單一分佈,由於其最小值和最大值與最小值相比收斂於0,因此,其最小值和最大值的距離變得不可辨別。
。
因此,在某種意義上,幾乎所有的高維空間都遠離其中心,或者從另一個角度來看,高維單元空間可以說是幾乎完全由超立方體的“邊角”所組成的,沒有“中部”,這對於理解卡方分佈是很重要的直覺理解。
給定一個單一分佈,由於其最小值和最大值與最小值相比收斂於0,因此,其最小值和最大值的距離變得不可辨別。 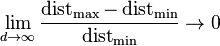 .
.
這通常被引證為距離函式在高維環境下失去其意義的例子。
Geometric Structure of High-Dimensional Data and Dimensionality Reduction . Jianzhong Wang