
目標檢測演算法(二)——具體原理以及實現
1.1光流法原理
光流的概念是Gibson在1950年首先提出來的。它是空間運動物體在觀察成像平面上的畫素運動的瞬時速度,是利用影象序列中畫素在時間域上的變化以及相鄰幀之間的相關性來找到上一幀跟當前幀之間存在的對應關係,從而計算出相鄰幀之間物體的運動資訊的一種方法。一般而言,光流是由於場景中前景目標本身的移動、相機的運動,或者兩者的共同運動所產生的。其計算方法可以分為三類:
(1)基於區域或者基於特徵的匹配方法;
(2)基於頻域的方法;
(3)基於梯度的方法;
簡單來說,光流是空間運動物體在觀測成像平面上的畫素運動的“瞬時速度”。光流的研究是利用影象序列中的畫素強度資料的時域變化和相關性來確定各自畫素位置的“運動”。研究光流場的目的就是為了從圖片序列中近似得到不能直接得到的運動場。
光流法的前提假設:
(1)相鄰幀之間的亮度恆定;
(2)相鄰視訊幀的取幀時間連續,或者,相鄰幀之間物體的運動比較“微小”;
(3)保持空間一致性;即,同一子影象的畫素點具有相同的運動
這裡有兩個概念需要解釋:
運動場,其實就是物體在三維真實世界中的運動;
光流場,是運動場在二維影象平面上的投影。

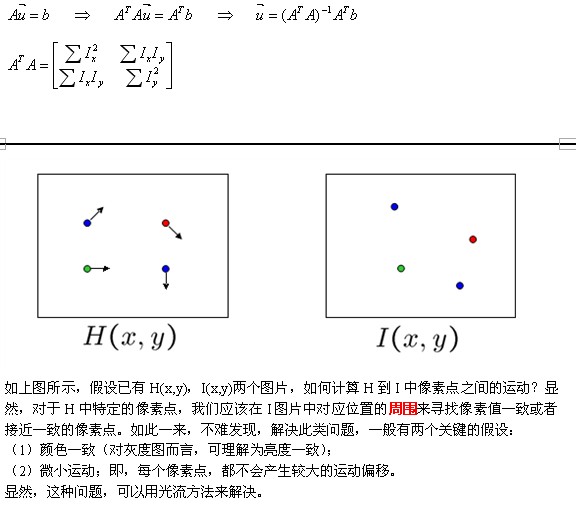

如上圖所示,H中的畫素點(x,y)在I中的移動到了(x+u,y+v)的位置,偏移量為(u,v)。
光流法用於目標檢測的原理:給影象中的每個畫素點賦予一個速度向量,這樣就形成了一個運動向量場。在某一特定時刻,影象上的點與三維物體上的點一一對應,這種對應關係可以通過投影來計算得到。根據各個畫素點的速度向量特徵,可以對影象進行動態分析。如果影象中沒有運動目標,則光流向量在整個影象區域是連續變化的。當影象中有運動物體時,目標和背景存在著相對運動。運動物體所形成的速度向量必然和背景的速度向量有所不同,如此便可以計算出運動物體的位置。需要提醒的是,利用光流法進行運動物體檢測時,計算量較大,無法保證實時性和實用性。
光流法用於目標跟蹤的原理:
(1)對一個連續的視訊幀序列進行處理;
(2)針對每一個視訊序列,利用一定的目標檢測方法,檢測可能出現的前景目標;
(3)如果某一幀出現了前景目標,找到其具有代表性的關鍵特徵點(可以隨機產生,也可以利用角點來做特徵點);
(4)對之後的任意兩個相鄰視訊幀而言,尋找上一幀中出現的關鍵特徵點在當前幀中的最佳位置,從而得到前景目標在當前幀中的位置座標;
(5)如此迭代進行,便可實現目標的跟蹤;
1.2 光流法實現
opencv的光流實現由好幾個方法可以(也就是說有好幾個函式可以用),每個函式當然也對應著不同的原理,那麼它的效果以及演算法的速度等等就會有一些差別。主要包括以下幾種:
calcOpticalFlowPyrLK
calcOpticalFlowFarneback
calcOpticalFlowBM
calcOpticalFlowHS
calcOpticalFlowSF
這裡先簡單介紹下calcOpticalFlowPyrLK函式
calcOpticalFlowPyrLK函式使用形式:
calcOpticalFlowPyrLK(prevImg,nextImg,prevPts,nextPts,status,err)
這個函式還有一些可選引數,一大堆,詳細的說明可以看
這裡只是貼出了主要的幾個輸入輸出:
prevImg:就是你需要輸入計算光流的前一幀影象
nextImg就是下一幀影象(可以看到一次光流就是在兩針影象之間找不同)。
prevPts是前一幀影象中的特徵點,這個特徵點必須自己去找,所以在使用calcOpticalFlowPyrLK函式的時候,前面需要有一個找特徵點的操作,那麼一般就是找影象的角點,就是一個畫素點與周圍畫素點都不同的那個點,這個角點特徵點的尋找,opencv也提供夜歌函式:goodFeatureToTrack()(後面再介紹這個函式)。那麼關於特徵點有沒有其他的方式呢?肯定是有的而且還很多吧。
nextPts引數就是計算特徵點在第二幅影象中的新的位置,然後輸出。特徵點的新位置可能變化了,也可能沒有變化,那麼這種狀態就存放在後一個引數status中。err就是新舊兩個特徵點位置的誤差了,也是一個輸出矩陣。
其他引數預設吧。
關於特徵角點檢測函式goodFeatureToTrack()
goodFeaturesToTrack(image,corners,maxCorners,qualityLevel,minDistance)
函式的引數:
image輸入影象;
corners輸出的特徵點系列,每一個元素就是一個特徵點的位置。
maxCorners規定的特徵點最大數目,比如一副影象你可以找到很多特徵點,但是隻是取前maxCorners個具有最大特徵的那些點作為最後的特徵點,至於怎麼判斷哪些點的特徵更好了,opencv自有一個機制,隨便一個方法,比如計算一下這個點與周圍一定領域的點的灰度相差求和,認為這個和越大的那些點是不是越屬於特徵點。
qualityLevel是一個特徵點的取到水平,其實也是控制特徵點的選取的,看結果適當選取吧。
minDistance是特徵點與點之間的最小距離,一般我們如果想特徵點儘量分散一些,太密集了肯定不好,那麼我們可以通過這個引數。
比如說一個例子如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
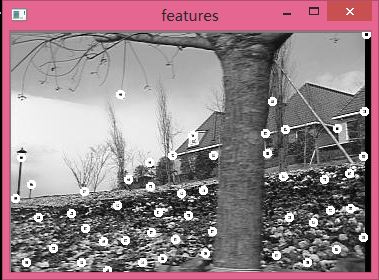
修改下 int maxCout = 100;//定義最大個數
double minDis = 10;//定義最小距離

下面通過這種特徵點來以及L-K光流法來檢測兩幅相鄰幀影象之間的移動點。首先自己準備兩幅圖吧,圖中要有運動的目標才好,然後我們就這兩幅圖簡單的看下里面的運動目標的特徵點的運動吧,一個簡單程式如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
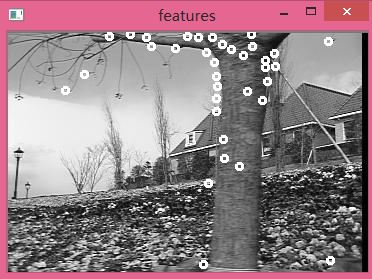
我的這兩幅樹葉圖是存在這一些變化的,尤其樹存在的地方,由於需要動態的來回切換著看才能看出變化,所以這裡不太好顯示這兩幅圖的變化,這裡吧他們相差的圖做出來如下:
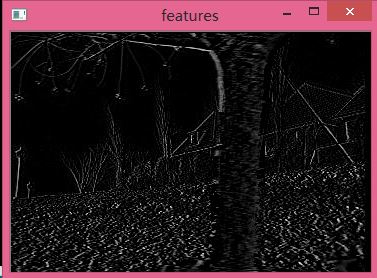
可以看到的是越白的地方就是存在著不一致,也就是存在著明顯運動的地方。和上面角點檢測的還是有點符合的。
當然,我這可能只是連續兩幀運動情況下的跟蹤的特徵點,如果是一個視訊(連續的很多幀),那麼把每兩幀之間的運動點連線起來,就可以發現運動的物體的整個軌跡了。像網上部落格有人做過的貼幾個: Opencv學習筆記(九)光流法
上節說到過的calcOpticalFlowPyrLK光流演算法,可以看到它實際上是一種稀疏特徵點的光流演算法,也就是說我們先找到那些(特徵)點需要進行處理,然後再處理,該節介紹下一個全域性性的密集光流演算法,也就是對每一個點都進行光流計算,函式為calcOpticalFlowFarneback。
首先介紹引數,詳細的介紹
引數一大推,得看一會。有些引數可能帶來的影響不是很大,那麼使用它推薦的引數即可。完整的引數達10個。按順序:
prevImg:輸入第一個圖
nextImg:輸入第二個圖
Flow:輸出的光流矩陣。矩陣大小同輸入的影象一樣大,但是矩陣中的每一個元素可不是一個值,而是兩個值,分別表示這個點在x方向與y方向的運動量(偏移量)。所以要把這個光流場矩陣顯示出來還真的需要費點力。那麼上面說的兩幅影象與這個光流場是什麼關係呢?如下:
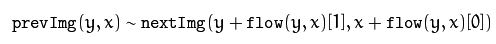
pyrScale:一個構造影象金字塔的引數,一般就認為是0.5最好了,也就是將影象縮小一半。那麼為什麼要構造金字塔呢?這應該是與演算法本身的設計有關,其實很多地方在檢測特徵的時候都會涉及到影象的金字塔,設想下如果有個特徵點在原始尺寸與其縮小的尺寸下都是特徵點的話,那麼這個特徵點就很有效了吧。
Levels:依然是與金字塔有關引數,常設值1.
Winsize:相當於一個均值濾波的作用,視窗大小決定了其噪聲的抑制能力什麼的。
Iterations:在每層金字塔上的迭代次數。
polyN:點與附近領域點之間的聯絡作用,一般為5,7等等即可。
polySigma :畫素點的一個平滑水平,一般1-1.5即可。
Flags:一個標記,決定計算方法。
具體怎麼影響結果的,可以自己去嘗試。
下面對上節使用到的兩幅圖,通過這個方法來計算這兩幀影象中存在的光流場,也就是把上述的Flow找出來,那些引數也決定了Flow找出來的不一樣。簡單的程式如下:
- 1
- 2
- 3
- 4
-
相關推薦
目標檢測演算法(二)——具體原理以及實現
1.1光流法原理 光流的概念是Gibson在1950年首先提出來的。它是空間運動物體在觀察成像平面上的畫素運動的瞬時速度,是利用影象序列中畫素在時間域上的變化以及相鄰幀之間的相關性來找到上一幀跟當前幀之間存在的對應關係,從而計算出相鄰幀之間物體的運動資訊的一種方法。一般而言,光流是由
經典論文重讀---目標檢測篇(二):Fast RCNN
核心思想 RCNN的缺點 R-CNN is slow because it performs a ConvNet forward pass for each object proposal, without sharing computation. SPPnet的缺
使用tensorflow object detection API 訓練自己的目標檢測模型 (二)
在上一篇部落格"使用tensorflow object detection API 訓練自己的目標檢測模型 (一)"中介紹瞭如何使用LabelImg標記資料集,生成.xml檔案,經過個人的手工標註,形成了一個大概有兩千張圖片的資料集。 但是這仍然不滿足t
異常點檢測演算法(二)矩陣分解
前面一篇文章《異常點檢測演算法(一)》簡要的介紹瞭如何使用概率統計的方法來計算異常點,本文將會介紹一種基於矩陣分解的異常點檢測方法。在介紹這種方法之前,先回顧一下主成分分析(Principle Component Analysis)這一基本的降維方法。 (一)主成分分析(Principle Componen
目標檢測演算法(一)——常見演算法比較
一、分類:幀間差分法、背景減除法和光流法。 (1)背景減除法通過統計前若千巾貞的變化情況,從而學習背景擾動的規律。此類演算法的缺點是由於通常需要緩衝若干幀頻來學習背景,因此往往需要消耗大量的記憶體,這使其使用範圍受到了限制。此外,對於大範圍的背景擾動,此類演算法的檢測
論文筆記:目標檢測演算法(R-CNN,Fast R-CNN,Faster R-CNN,YOLOv1-v3)
R-CNN(Region-based CNN) motivation:之前的視覺任務大多數考慮使用SIFT和HOG特徵,而近年來CNN和ImageNet的出現使得影象分類問題取得重大突破,那麼這方面的成功能否遷移到PASCAL VOC的目標檢測任務上呢?基於這個問題,論文提出了R-CNN。 基本步驟:如下圖
基礎演算法(二):Kmeans聚類演算法的基本原理與應用
Kmeans聚類演算法的基本原理與應用 內容說明:主要介紹Kmeans聚類演算法的數學原理,並使用matlab程式設計實現Kmeans的簡單應用,不對之處還望指正。 一、Km
深入淺出PID控制演算法(二)————PID演算法離散化和增量式PID演算法原理及Matlab實現
引言 上篇介紹了連續系統的PID演算法,但是計算機控制是一種取樣控制,他只能根據取樣時刻的偏差來計算控制量,因此計算機控制系統中,必須對公式進行離散化,具體就是用求和代替積分,用向後差分來代替微分,使模擬PID離散化為數字形式的差分方程。 準備工
微信公眾平臺開發教程(二) 基本原理及消息接口
username 普通用戶 縮放 地理位置 cfb 位置 註意 獲得 基本 一、基本原理 在開始做之前,大家可能對這個很感興趣,但是又比較茫然。是不是很復雜?很難學啊? 其實恰恰相反,很簡單。為了打消大家的顧慮,先簡單介紹了微信公眾平臺的基本原理。 微信服務器就相當於一個轉
GCC編譯器原理(二)------編譯原理一:ELF文件
過程 外部文件 初始 cati tor 保護功能 編譯原理 外部 comm 二、ELF 文件介紹 2.1 可執行文件格式綜述 相對於其它文件類型,可執行文件可能是一個操作系統中最重要的文件類型,因為它們是完成操作的真正執行者。可執行文件的大小、運行速度、資源占用情況
Spring系列框架系統復習(二)spring原理-面試常遇到的問題
適配器 solver ring 兩種 頁面 筆記 分享圖片 tar 表現 1、什麽是DI機制? 依賴註入(Dependecy Injection)和控制反轉(Inversion of Control)是同一個概念,具體的講:當某個角色需要另外一個角色協助的時候,在傳統的程
資料結構與演算法(二)--遞迴
遞迴條件: 1.遞迴條件:每次調自己,然後記錄當時的狀態 2.基準條件:執行到什麼時候結束遞迴,不然遞迴就會無休止的呼叫自己, 遞迴的資料結構:棧(先進先出)和彈夾原理一樣,每一次呼叫自己都記錄了當時的一種狀態,然後把這種狀態的結果返回。 棧相對應的資料結構:佇列(先進後出
演算法(二)之排序
排序演算法很多,常用的排序演算法有:氣泡排序、插入排序、選擇排序、歸併排序、快速排序、計數排序、基數排序、桶排序。 接下來一一介紹幾種排序的時間複雜度及優缺點。 插入排序與氣泡排序的時間複雜度相同O(n^2),開發中我們更傾向插入排序,而不是氣泡排序 排序演算法執行效率: 1.最好、最壞、平均情況時間
圖——基本的圖演算法(二)圖的遍歷
圖——基本的圖演算法(二)圖的遍歷 1. 基本概念 圖的遍歷指的是從圖中的某個頂點出發訪問圖中其餘的頂點,且每個頂點只被訪問一次的這個過程。通常來說,圖的遍歷次序有兩種:深度優先遍歷(Depth first Search, DFS)和廣度優先遍歷(Breadth First Se
吳恩達老師機器學習筆記K-means聚類演算法(二)
運用K-means聚類演算法進行影象壓縮 趁熱打鐵,修改之前的演算法來做第二個練習—影象壓縮 原始圖片如下: 程式碼如下: X =imread('bird.png'); % 讀取圖片 X =im2double(X); % unit8轉成double型別 [m,n,z]=size
深入理解線性迴歸演算法(二):正則項的詳細分析
前言 當模型的複雜度達到一定程度時,則模型處於過擬合狀態,類似這種意思相信大家看到個很多次了,本文首先討論了怎麼去理解複雜度這一概念,然後回顧貝葉斯思想(原諒我有點囉嗦),並從貝葉斯的角度去理解正則項的含義以及正則項降低模型複雜度的方法,最後總結全文。 &nb
Logistic迴歸之梯度上升優化演算法(二)
Logistic迴歸之梯度上升優化演算法(二) 有了上一篇的知識儲備,這一篇部落格我們就開始Python3實戰 1、資料準備 資料集:資料集下載 資料集內容比較簡單,我們可以簡單理解為第一列X,第二列Y,第三列是分類標籤。根據標籤的不同,對這些資料點進行分類。
經典論文重讀---目標檢測篇(一):RCNN
核心思想 Since we combine region proposals with CNNs, we call our method R-CNN: Regions with CNN features. 即將生成proposal的方法與cnn提取特徵進行結合
「日常訓練&知識學習」莫隊演算法(二):樹上莫隊(Count on a tree II,SPOJ COT2)
題意與分析 題意是這樣的,給定一顆節點有權值的樹,然後給若干個詢問,每次詢問讓你找出一條鏈上有多少個不同權值。 寫這題之前要參看我的三個blog:CFR326D2E、CFR340D2E和HYSBZ-1086,然後再看這幾個Blog—— 參考A:https://blog.sengxian.com/algori
從零開始學演算法(二)選擇排序
從零開始學演算法(二)選擇排序 選擇排序 演算法介紹 演算法原理 演算法簡單記憶說明 演算法複雜度和穩定性 程式碼實現 選擇排序 程式碼是Javascript語言寫的(幾乎是虛擬碼) 演算