
讀書筆記30:Recognize Actions by Disentangling Components of Dynamics(CVPR2018)
摘要首先介紹背景:儘管近些年動作識別領域的進展很大,但是其效率還是很有限的,將appearance和motion分別對待的方法常常會有需要大量計算資源計算optical flow的問題;依賴於在原始video上進行3D卷積的方法表現又常常不是很好。本文提出了一種representation learning的模型可以直接從原始的video中提取出運動資訊的三個組成部分(不依賴於opticalflow),分別是static appearance的representation、apparent motion和appearance change。
一個簡單的模型示意圖如下
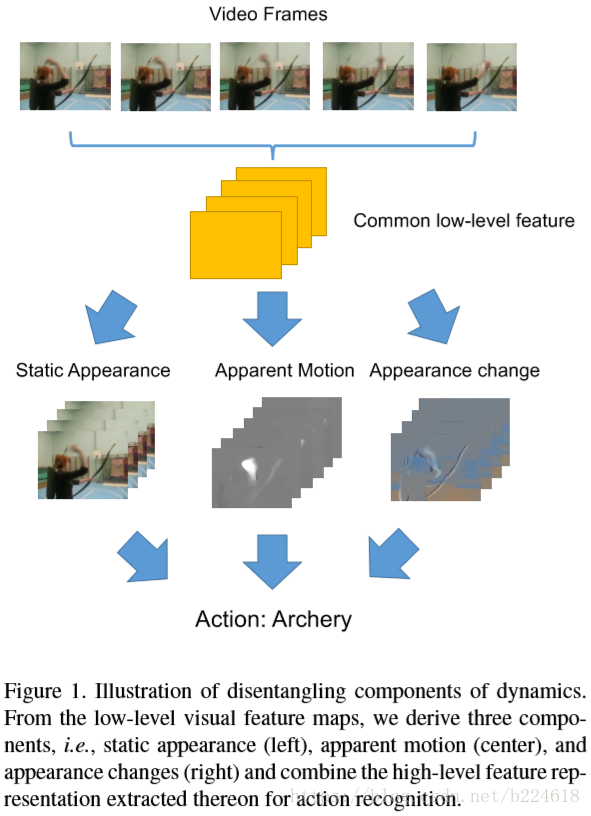
本文將video視作short-term的dynamics和long-term的時序結構(temporal structure),本文將注意力集中在short-term的dynamics上,使用TSN來進行long-term temporal structure的模擬。上圖展示的就是short-term representation,包括static appearance、apparent motion和appearance changes三個部分,給定一段video,模型會先通過幾層卷積網路計算常規的low-level features,之後通過三個分支提取三個組成部分,具體來講分別是用3D pooling抓取static appearance,用cost volume processing抓取apparent motion,最後的用warped feature difference表示appearance changes。這些不同的模組通過unified network整合到一起,生成最終的prediction。
本文的這個模型主要是抓取短程的short-term dynamics,然後和其他high level model結合起來抓取long-term temporal structure(例如用TSN和LSTM)。
下圖是一個更加詳細一些的模型示意圖
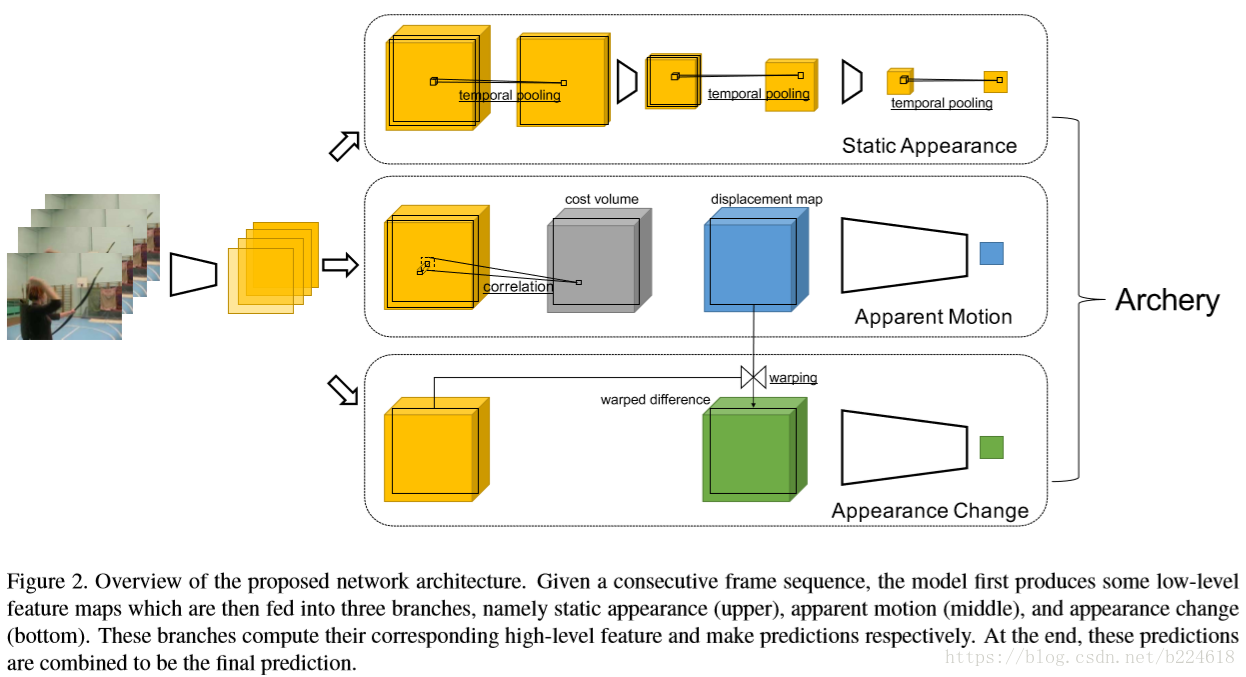
模型的輸入是短的video clip,因為模型處理的是short-term dynamics,輸入的video clip先通過卷積層轉化為64 channel的feature map(好像一開始都喜歡轉化為64channel的,lindahua的那篇sgtcn也是如此),然後,三個分支都用這個feature map進行進一步的高層次特徵的提取,接下來具體介紹這第三個分支都是如何提取相應的高層次資訊的。
第一個分支是static appearance branch,這個分支是想要從觀察到的場景中得到static appearance的representation,在主流的模型中,appearance feature一般都是一幀一幀計算的,這樣容易受到異常值的干擾,比如哪裡模糊了,哪一幀攝像機突然動了之類的影響。因此,本文的思想是要在neighborhood中選擇響應最高的,而不是每一幀都保留。基於這種思想,此分支的設計如下圖
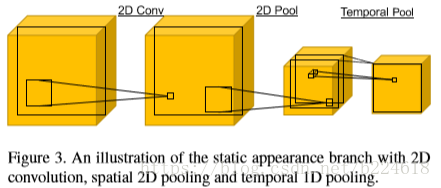
首先進行2D卷積,用來抓取visual pattern,接著進行spatial的2D pooling,接著是1D的temporal pooling(temporal pooling就是為了使feature更加穩定而設計的),這個模式不斷地重複,不斷地提取特徵,2D pooling和3D pooling相結合的模式其實相當於3D pooling,可以在spatial temporal維度上都將activation進行池化,在不斷地迭代中,每一幀的分斌率都在下降,但是channel數量卻在上升,最終每一個畫素點的channel數都會由64變成1024,這也就得到了最終的static appearance component。
作者將這個模組與已有的3D卷積模型進行了對比,提出本文這個static appearance branch更加的合適,首先是因為這個branch是為了抓取一些static的appearance feature,而不是抓取dynamic資訊,因此這種設計的表達能力已經夠了,並且對資源的花費更小;第二點說的其實還是節約資源好訓練, 3D卷積網路由於引數數量遠多於本文的這個模型,因此需要更多地樣本,迭代更多次來進行訓練,而本文的這個3D pooling是不需要引數的,而2D的卷積層可以使用一些已經訓練好的CNN模型(應該是用已有的模型初始化,否則就沒有需要訓練的部分了)。
第二個branch是apparent motion branch,這個branch意在捕捉空間位置上feature point的移動。以往的工作通常是用optical flow來表示這個motion資訊,但是optical flow太耗費資源,並且常常需要額外的模組(extra module,不是很懂這個額外的需求是什麼)。在本文的設計中,作者探索了另一條路來表示這個很重要的motion data,是直接通過cost volume來進行motion representation,cost volume是一個在low-level的視覺任務中常用的東西,例如在optical flow estimation中起到一箇中間步驟的作用。據作者所知,本文是第一個直接用cost volume進行motion representation,進而進行action recognition的工作。
cost volume是在連續的frame的feature map之間兩兩進行計算的,例如兩個feature map和
,建立的cost volume
是通過將每一個點在一定大小的視窗中和其neighborhood進行對比得到的,視窗的大小是
,也就是每一個點都對應一個這麼大的視窗,這個視窗內每一個數值都是這個點的neighborhood和這個點對比計算出來的similarity,在本文中,具體採用的是cosine similarity,
表示的就是
和
之間的cosine similarity,這裡的
指的是第t幀feature map中第i第j列的feature vector。另一個工作FlowNet中也進行過類似的操作,但是在那篇文章中用的不是cosine similarity,而是直接feature vector點乘,此外,FlowNet中生成的correlation map是和appearance feature一起送入下一層的,而本文的工作中,cost volume是隻關注motion information。
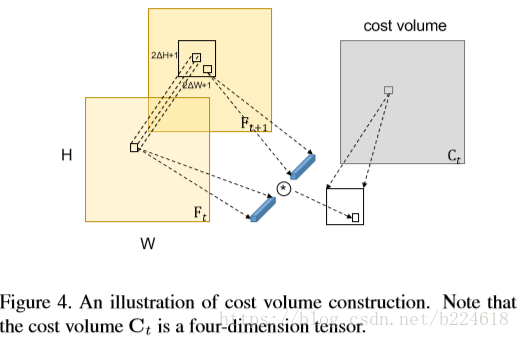
得到cost volume還不是最終要的結果,還要進一步得到一個低維的representation,更簡潔的表示motion data,畢竟原來的feature map是3維的,現在突然變成4維的,可能也不好一起處理。降維的方式是建立一個displacement map
用來表示從第t幀到t+1幀之間的motion,為了簡化表示,t和t+1都不寫了。在這個map上,每一個點都是一個長度為2的vector ,表示這個位置在x和y一個水平一個豎直方向上的移動。具體來講,計算公式如下:
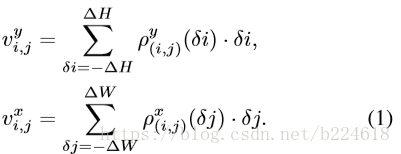
也就是為前述的cost volume中的每一個位置的window中的每一個位置在兩個方向上進行加權求和,分別得到兩個方向上的結果。而這個加權的係數和
由下式計算:
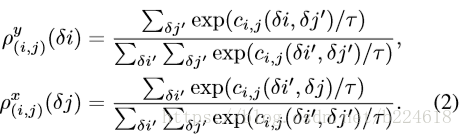
這裡面,也就是計算x方向上某一個
的權重時,就把第i行所有列的數值計算softmax值,這裡面τ是temperature coefficient,這個值越小,計算出來的概率分佈就越集中在概率值大的位置,t趨於0時,就接近於winner-take-all的形式,只保留概率最高的。實際試驗中這兩個
和
可以通過兩個方向上的softmax函式計算獲得,而最終的displacement map可以通過2D的卷積獲得。得到map之後,就可以繼續採用卷積網路來進行高層次特徵的提取了,最終還是得到1024channel的feature map,表示apparent motion
第三個branch是appearance change branch,這個branch是考慮到不同frame之間的變化不只有motion造成的,有的時候還可能有光照變化之類的變化產生,這種外觀的變化稱為appearance change,以往的方法可能就是將相鄰幀之間做差來獲取這個變化,但是那樣就會把motion變化和appearance變化混雜在一起,與本文想將其分解開來的願望相悖。因此本文采取的措施是先用前面所說的displacement map將第t幀進行一下warp,得到
,其實也就是生成一下沒有appearance change,只有motion displacement的下一幀feature map,再用這個只有motion change的feature map和兩種變化都有的t+1幀
相減
,得到的就是appearance change,稱之為warped differences,在warp的過程中,如果
哪個點需要用到上一幀feature範圍外的點進行計算,就置零。
本來作者在具體介紹三部分結構之後要介紹這三個部分得到的結果如何聚合,但是並沒有說,不過前面倒是說過這三個分支得到的結果是通過取平均的的方式聚合在一起的。