
【機器學習】主成分分析詳解
一、PCA簡介
1. 相關背景
主成分分析(Principal Component Analysis,PCA), 是一種統計方法。通過正交變換將一組可能存在相關性的變數轉換為一組線性不相關的變數,轉換後的這組變數叫主成分。
上完陳恩紅老師的《機器學習與知識發現》和季海波老師的《矩陣代數》兩門課之後,頗有體會。最近在做主成分分析和奇異值分解方面的專案,所以記錄一下心得體會。
在許多領域的研究與應用中,往往需要對反映事物的多個變數進行大量的觀測,收集大量資料以便進行分析尋找規律。多變數大樣本無疑會為研究和應用提供了豐富的資訊,但也在一定程度上增加了資料採集的工作量,更重要的是在多數情況下,許多變數之間可能存在相關性,從而增加了問題分析的複雜性,同時對分析帶來不便。如果分別對每個指標進行分析,分析往往是孤立的,而不是綜合的。盲目減少指標會損失很多資訊,容易產生錯誤的結論。
因此需要找到一個合理的方法,在減少需要分析的指標同時,儘量減少原指標包含資訊的損失,以達到對所收集資料進行全面分析的目的。由於各變數間存在一定的相關關係,因此有可能用較少的綜合指標分別綜合存在於各變數中的各類資訊。主成分分析與因子分析就屬於這類降維的方法。
2. 問題描述
下表1是某些學生的語文、數學、物理、化學成績統計:
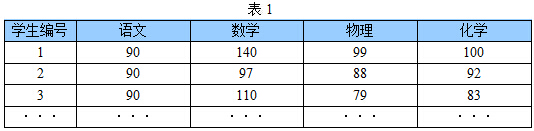
首先,假設這些科目成績不相關,也就是說某一科目考多少分與其他科目沒有關係。那麼一眼就能看出來,數學、物理、化學這三門課的成績構成了這組資料的主成分(很顯然,數學作為第一主成分,因為數學成績拉的最開)。為什麼一眼能看出來?因為座標軸選對了!下面再看一組學生的數學、物理、化學、語文、歷史、英語成績統計,見表2,還能不能一眼看出來:
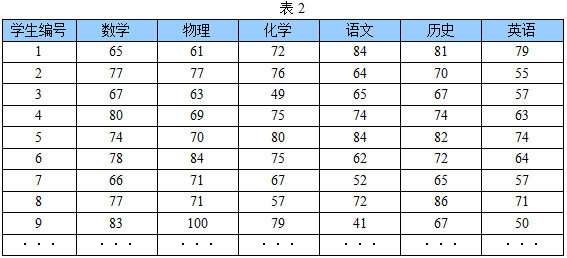
資料太多了,以至於看起來有些凌亂!也就是說,無法直接看出這組資料的主成分,因為在座標系下這組資料分佈的很散亂。究其原因,是因為無法撥開遮住肉眼的迷霧~如果把這些資料在相應的空間中表示出來,也許你就能換一個觀察角度找出主成分。如下圖1所示:
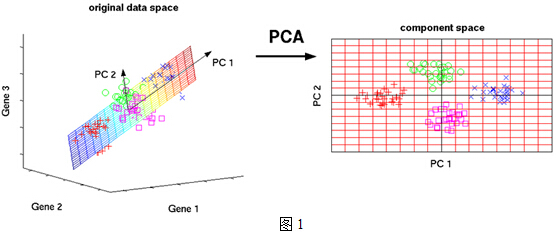
但是,對於更高維的資料,能想象其分佈嗎?就算能描述分佈,如何精確地找到這些主成分的軸?如何衡量你提取的主成分到底佔了整個資料的多少資訊?所以,我們就要用到主成分分析的處理方法。
3. 資料降維
為了說明什麼是資料的主成分,先從資料降維說起。資料降維是怎麼回事兒?假設三維空間中有一系列點,這些點分佈在一個過原點的斜面上,如果你用自然座標系x,y,z這三個軸來表示這組資料的話,需要使用三個維度,而事實上,這些點的分佈僅僅是在一個二維的平面上,那麼,問題出在哪裡?如果你再仔細想想,能不能把x,y,z座標系旋轉一下,使資料所在平面與x,y平面重合?這就對了!如果把旋轉後的座標系記為x’,y’,z’,那麼這組資料的表示只用x’和y’兩個維度表示即可!當然了,如果想恢復原來的表示方式,那就得把這兩個座標之間的變換矩陣存下來。這樣就能把資料維度降下來了!但是,我們要看到這個過程的本質,如果把這些資料按行或者按列排成一個矩陣,那麼這個矩陣的秩就是2!這些資料之間是有相關性的,這些資料構成的過原點的向量的最大線性無關組包含2個向量,這就是為什麼一開始就假設平面過原點的原因!那麼如果平面不過原點呢?這就是資料中心化的緣故!將座標原點平移到資料中心,這樣原本不相關的資料在這個新座標系中就有相關性了!有趣的是,三點一定共面,也就是說三維空間中任意三點中心化後都是線性相關的,一般來講n維空間中的n個點一定能在一個n-1維子空間中分析!
上一段文字中,認為把資料降維後並沒有丟棄任何東西,因為這些資料在平面以外的第三個維度的分量都為0。現在,假設這些資料在z’軸有一個很小的抖動,那麼我們仍然用上述的二維表示這些資料,理由是我們可以認為這兩個軸的資訊是資料的主成分,而這些資訊對於我們的分析已經足夠了,z’軸上的抖動很有可能是噪聲,也就是說本來這組資料是有相關性的,噪聲的引入,導致了資料不完全相關,但是,這些資料在z’軸上的分佈與原點構成的夾角非常小,也就是說在z’軸上有很大的相關性,綜合這些考慮,就可以認為資料在x’,y’ 軸上的投影構成了資料的主成分!
課堂上老師談到的特徵選擇的問題,其實就是要剔除的特徵主要是和類標籤無關的特徵。而這裡的特徵很多是和類標籤有關的,但裡面存在噪聲或者冗餘。在這種情況下,需要一種特徵降維的方法來減少特徵數,減少噪音和冗餘,減少過度擬合的可能性。
PCA的思想是將n維特徵對映到k維上(k<n),這k維是全新的正交特徵。這k維特徵稱為主成分,是重新構造出來的k維特徵,而不是簡單地從n維特徵中去除其餘n-k維特徵。
二、PCA例項
現在假設有一組資料如下:
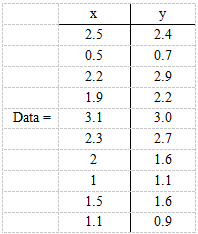
行代表了樣例,列代表特徵,這裡有10個樣例,每個樣例兩個特徵。可以這樣認為,有10篇文件,x是10篇文件中“learn”出現的TF-IDF,y是10篇文件中“study”出現的TF-IDF。
第一步,中心化(均值化)目的是為了方便後面求解。從協方差矩陣的定義看: Σ=E{(x-E(x)) * (x-E(x))T},PCA的第一步就是要去均值化。求分別求x和y的平均值,然後對於所有的樣例,都減去對應的均值。這裡x的均值是1.81,y的均值是1.91,那麼一個樣例減去均值後即為(0.69,0.49),得到
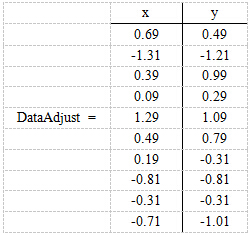
第二步,求特徵協方差矩陣,如果資料是3維,那麼協方差矩陣是
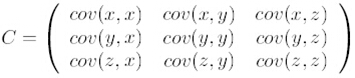
這裡只有x和y,求解得
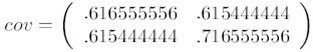
對角線上分別是x和y的方差,非對角線上是協方差。協方差是衡量兩個變數同時變化的變化程度。協方差大於0表示x和y若一個增,另一個也增;小於0表示一個增,一個減。如果x和y是統計獨立的,那麼二者之間的協方差就是0;但是協方差是0,並不能說明x和y是獨立的。協方差絕對值越大,兩者對彼此的影響越大,反之越小。協方差是沒有單位的量,因此,如果同樣的兩個變數所採用的量綱發生變化,它們的協方差也會產生樹枝上的變化。
第三步,求協方差的特徵值和特徵向量,得到
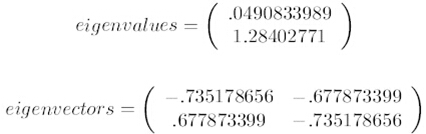
上面是兩個特徵值,下面是對應的特徵向量,特徵值0.0490833989對應特徵向量為,這裡的特徵向量都歸一化為單位向量。
第四步,將特徵值按照從大到小的順序排序,選擇其中最大的k個,然後將其對應的k個特徵向量分別作為列向量組成特徵向量矩陣。
這裡特徵值只有兩個,我們選擇其中最大的那個,這裡是1.28402771,對應的特徵向量是(-0.677873399, -0.735178656)T。
第五步,將樣本點投影到選取的特徵向量上。假設樣例數為m,特徵數為n,減去均值後的樣本矩陣為DataAdjust(m*n),協方差矩陣是n*n,選取的k個特徵向量組成的矩陣為EigenVectors(n*k)。那麼投影后的資料FinalData為
FinalData(10*1) = DataAdjust(10*2矩陣) x 特徵向量(-0.677873399, -0.735178656)T
得到的結果是
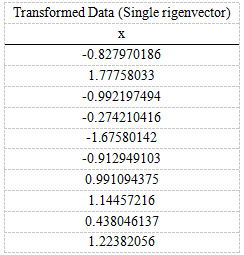
這樣,就將原始樣例的n維特徵變成了k維,這k維就是原始特徵在k維上的投影。
上面的資料可以認為是learn和study特徵融合為一個新的特徵叫做LS特徵,該特徵基本上代表了這兩個特徵。上述過程如下圖2描述:
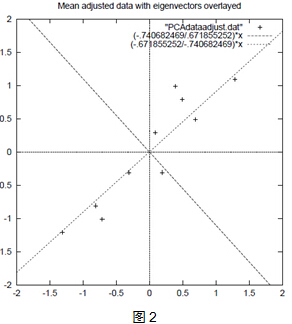
正號表示預處理後的樣本點,斜著的兩條線就分別是正交的特徵向量(由於協方差矩陣是對稱的,因此其特徵向量正交),最後一步的矩陣乘法就是將原始樣本點分別往特徵向量對應的軸上做投影。
整個PCA過程貌似及其簡單,就是求協方差的特徵值和特徵向量,然後做資料轉換。但是有沒有覺得很神奇,為什麼求協方差的特徵向量就是最理想的k維向量?其背後隱藏的意義是什麼?整個PCA的意義是什麼?
三、PCA推導
先看下面這幅圖:
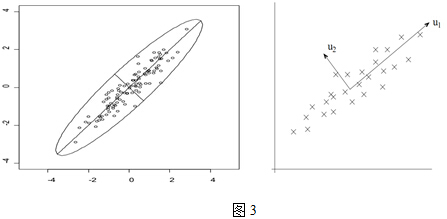
在第一部分中,我們舉了一個學生成績的例子,裡面的資料點是六維的,即每個觀測值是6維空間中的一個點。我們希望將6維空間用低維空間表示。
先假定只有二維,即只有兩個變數,它們由橫座標和縱座標所代表;因此每個觀測值都有相應於這兩個座標軸的兩個座標值;如果這些資料形成一個橢圓形狀的點陣,那麼這個橢圓有一個長軸和一個短軸。在短軸方向上,資料變化很少;在極端的情況,短軸如果退化成一點,那只有在長軸的方向才能夠解釋這些點的變化了;這樣,由二維到一維的降維就自然完成了。
上圖中,u1就是主成分方向,然後在二維空間中取和u1方向正交的方向,就是u2的方向。則n個數據在u1軸的離散程度最大(方差最大),資料在u1上的投影代表了原始資料的絕大部分資訊,即使不考慮u2,資訊損失也不多。而且,u1、u2不相關。只考慮u1時,二維降為一維。
橢圓的長短軸相差得越大,降維也越有道理。
1. 最大方差理論
在訊號處理中認為訊號具有較大的方差,噪聲有較小的方差,信噪比就是訊號與噪聲的方差比,越大越好。如前面的圖,樣本在u1上的投影方差較大,在u2上的投影方差較小,那麼可認為u2上的投影是由噪聲引起的。
因此我們認為,最好的k維特徵是將n維樣本點轉換為k維後,每一維上的樣本方差都很大。
比如我們將下圖中的5個點投影到某一維上,這裡用一條過原點的直線表示(資料已經中心化):
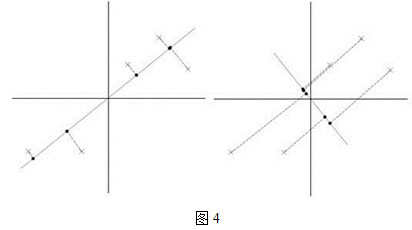
假設我們選擇兩條不同的直線做投影,那麼左右兩條中哪個好呢?根據我們之前的方差最大化理論,左邊的好,因為投影后的樣本點之間方差最大(也可以說是投影的絕對值之和最大)。
計算投影的方法見下圖5:

圖中,紅色點表示樣例,藍色點表示在u上的投影,u是直線的斜率也是直線的方向向量,而且是單位向量。藍色點是在u上的投影點,離原點的距離是<x,u>(即xTu或者uTx)。
2. 最小二乘法
我們使用最小二乘法來確定各個主軸(主成分)的方向。
對給定的一組資料(下面的闡述中,向量一般均指列向量):
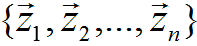
其資料中心位於:
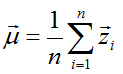
資料中心化(將座標原點移到樣本點的中心點):
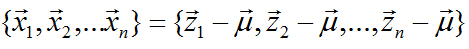
中心化後的資料在第一主軸u1方向上分佈散的最開,也就是說在u1方向上的投影的絕對值之和最大(也可以說方差最大),計算投影的方法上面已經闡述,就是將x與u1做內積,由於只需要求u1的方向,所以設u1也是單位向量。
在這裡,也就是最大化下式:
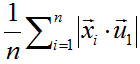
由矩陣代數相關知識可知,可以對絕對值符號項進行平方處理,比較方便。所以進而就是最大化下式:
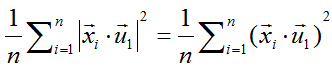
兩個向量做內積,可以轉化成矩陣乘法:
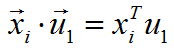
所以目標函式可以表示為:
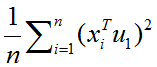
括號裡面就是矩陣乘法表示向量內積,由於列向量轉置以後是行向量,行向量乘以列向量得到一個數,一個數的轉置還是其本身,所以又可以將目標函式化為:
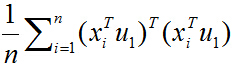
去括號:
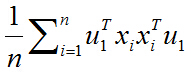
又由於u1和i無關,可以拿到求和符外面,上式化簡為:
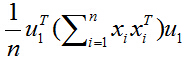
學過矩陣代數的同學可能已經發現了,上式括號裡面求和後的結果,就相當於一個大矩陣乘以自身的轉置,其中,這個大矩陣的形式如下:
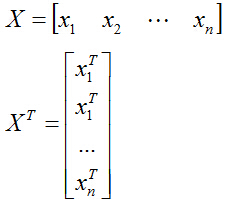
X矩陣的第i列就是xi
於是有:
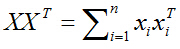
所以目標函式最終化為:
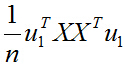
其中的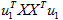
我們假設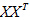
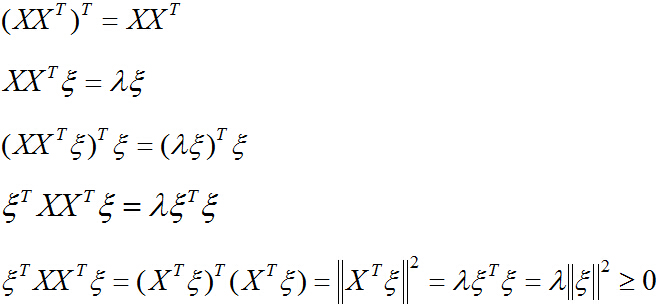
所以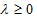
下面我們求解最大值、取得最大值時u1的方向這兩個問題。
先解決第一個問題,對於向量x的二範數平方為:
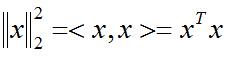
同樣,目標函式也可以表示成對映後的向量的二範數平方:
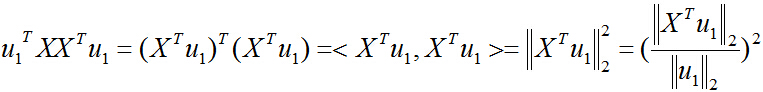
把二次型化成一個範數的形式,由於u1取單位向量,最大化目標函式的基本問題也就轉化為:對一個矩陣,它對一個向量做變換,變換前後的向量的模長伸縮尺度如何才能最大?我們有矩陣代數中的定理知,向量經矩陣對映前後的向量長度之比的最大值就是這個矩陣的最大奇異值,即:
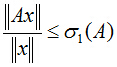
式中,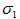
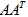
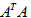
針對本問題來說,
再解決第二個問題,對一般情況,設對稱陣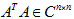
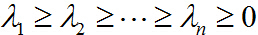
相應的單位特徵向量為:
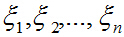
任取一個向量x,用特徵向量構成的空間中的這組基表示為:
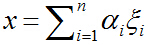
則:
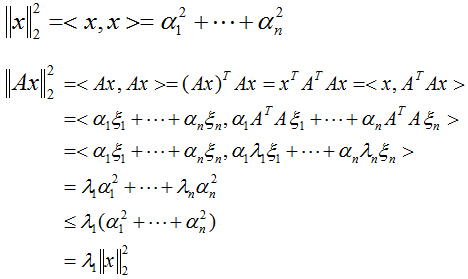
所以:
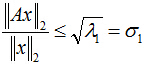
針對第二個問題,我們取上式中的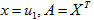
的最大特徵值時,對應的特徵向量的方向,就是第一主成分u1的方向!(第二主成分的方向為
證明完畢。
3.拉格朗日乘法求主軸方向:
求目標函式最大值值也可以根據拉格朗日乘法:
目標函式為:Max(u.T*S*)其中S為上面的矩陣X*X.T
約束條件為:u.T*u=1 (前面假設u為單位向量)

上面可知目標函式的最大值實際上就是求最大特徵值.
主成分所佔整個資訊的百分比可用下式計算:
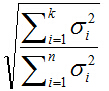
式中分母為
有些研究工作表明,所選的主軸總長度佔所有主軸長度之和的大約85% 即可,其實,這只是一個大體的說法,具體選多少個,要看實際情況而定。
4.結論
一般的,如果我們有M個N維向量,想將其變換為由R個N維向量表示的新空間中,那麼首先將R個基按行組成矩陣A,然後將向量按列組成矩陣B,那麼兩矩陣的乘積AB就是變換結果,其中AB的第m列為A中第m列變換後的結果。
對應數學表達:
 其中pipi是一個行向量,表示第i個基,ajaj是一個列向量,表示第j個原始資料記錄。
其中pipi是一個行向量,表示第i個基,ajaj是一個列向量,表示第j個原始資料記錄。
上述分析同時給矩陣相乘找到了一種物理解釋:兩個矩陣相乘的意義是將右邊矩陣中的每一列列向量變換到左邊矩陣中每一行行向量為基所表示的空間中去。這種操作便是降維。
補充知識:矩陣的乘法實際上就是在不同基上的投影。
B-基的概念
給出下面這個向量:
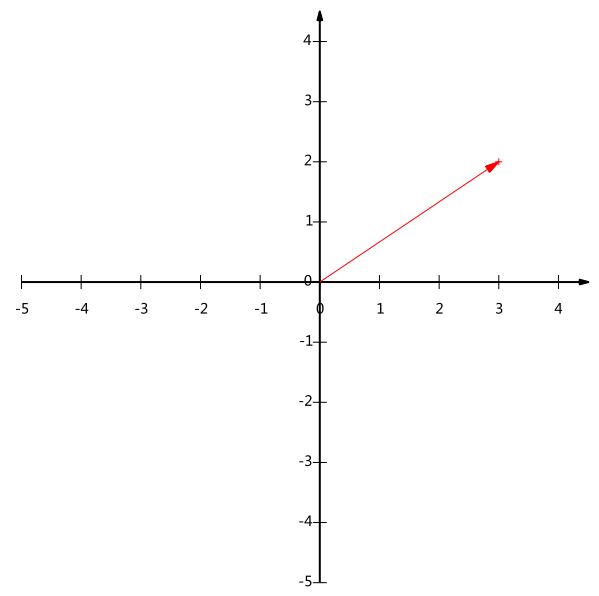
在代數表示方面,我們經常用線段終點的點座標表示向量,例如上面的向量可以表示為(3,2),這是我們再熟悉不過的向量表示。
不過我們常常忽略,只有一個(3,2)本身是不能夠精確表示一個向量的。我們仔細看一下,這裡的3實際表示的是向量在x軸上的投影值是3,在y軸上的投影值是2。也就是說我們其實隱式引入了一個定義:以x軸和y軸上正方向長度為1的向量為標準。那麼一個向量(3,2)實際是說在x軸投影為3而y軸的投影為2。注意投影是一個向量,所以可以為負。
更正式的說,向量(x,y)實際上表示線性組合:
x(1,0)T+y(0,1)Tx(1,0)T+y(0,1)T
不難證明所有二維向量都可以表示為這樣的線性組合。此處(1,0)和(0,1)叫做二維空間中的一組基。
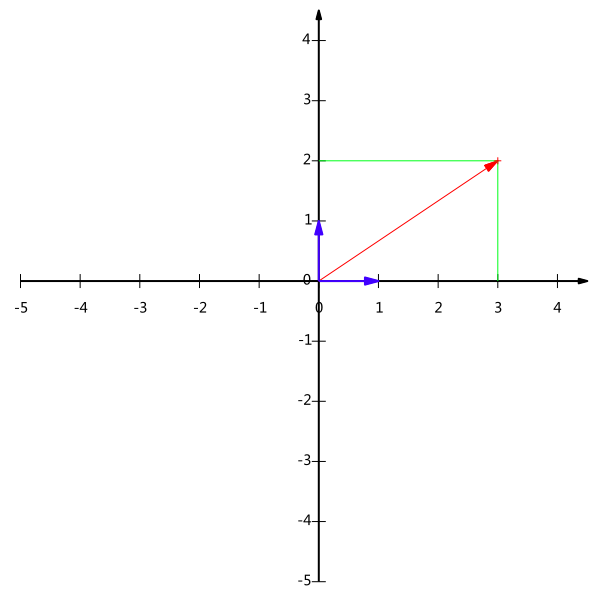
同樣我們可以利用基變換的矩陣表示進行求解:
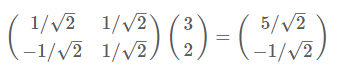
再舉一例:(1,1),(2,2),(3,3),想變換到剛才那組基上,則可以這樣表示:
 於是一組向量的基變換被幹淨的表示為矩陣的相乘。
於是一組向量的基變換被幹淨的表示為矩陣的相乘。
推廣成一般性結論:
一般的,如果我們有M個N維向量,想將其變換為由R個N維向量表示的新空間中,那麼首先將R個基按行組成矩陣A,然後將向量按列組成矩陣B,那麼兩矩陣的乘積AB就是變換結果,其中AB的第m列為A中第m列變換後的結果。
對應數學表達:
其中pipi是一個行向量,表示第i個基,ajaj是一個列向量,表示第j個原始資料記錄。
上述分析同時給矩陣相乘找到了一種物理解釋:兩個矩陣相乘的意義是將右邊矩陣中的每一列列向量變換到左邊矩陣中每一行行向量為基所表示的空間中去。這種操作便是降維。
關於最優基的選擇就是上面求第一主成分的事情了。
5.意義
PCA將n個特徵降維到k個,可以用來進行資料壓縮,例如100維的向量最後可以用10維來表示,那麼壓縮率為90%。同樣影象處理領域的KL變換使用PCA做影象壓縮,人臉檢測和匹配。比如如下摘自另一篇部落格上的Matlab實驗結果:



可見測試樣本為人臉的樣本的重建誤差顯然小於非人臉的重建誤差。
from:http://blog.jobbole.com/109015/
https://www.cnblogs.com/xingshansi/p/6445625.html