
kmp模板模板模板
此文章轉自dalao部落格:http://www.cnblogs.com/SYCstudio/p/7194315.html
KMP演算法(研究總結,字串)
引入
首先我們來看一個例子,現在有兩個字串A和B,問你在A中是否有B,有幾個?為了方便敘述,我們先給定兩個字串的值
A="abcaabababaa"
B="abab"
那麼普通的匹配是怎麼操作的呢?
當然就是一位一位地比啦。(下面用藍色表示已經匹配,黑色表示匹配失敗)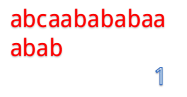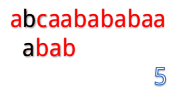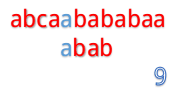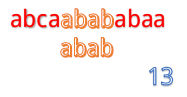
但是我們發現這樣匹配很浪費!
為什麼這麼說呢,我們看到第4步: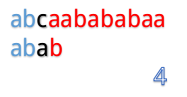
在第4步的時候,我們發現第3位上c與a不匹配,然後第五步的時候我們把B串向後移一位,再從第一個開始匹配。
這裡就有一個對已知資訊很大的浪費,因為根據前面的匹配結果,我們知道B串的前兩位是ab,所以不管怎麼移,都是不能和b匹配的,所以應該直接跳過對A串第二位的匹配,對於A串的第三位也是同理。
或許這這個例子還不夠經典,我們再舉一個。
A="abbaabbbabaa"
B="abbaaba"
在這個例子中,我們依然從第1位開始匹配,直到匹配失敗:
abbaabbbabba
abbaaba
我們發現第7位不匹配
那麼我們若按照原來的方式繼續匹配,則是把B串向後移一位,重新從第一個字元開始匹配
abbaabbbabba
_abbaaba
依然不匹配,那我們就要繼續往後移咯。
且住!
既然我們已經匹配了前面的6位,那麼我們也就知道了A串這6位和B串的前6位是匹配的,我們能否利用這個資訊來優化我們的匹配呢?
也就是說,我們能不能在上面匹配失敗後直接跳到:
abbaabbbabba
____abbaaba
這樣就可以省去很多不必要的匹配。
KMP演算法
KMP演算法就是解決上面的問題的,在講述之前,我們先擺出兩個概念:
字首:指的是字串的子串中從原串最前面開始的子串,如abcdef的字首有:a,ab,abc,abcd,abcde
字尾:指的是字串的子串中在原串結尾處結尾的子串,如abcdef的字尾有:f,ef,def,cdef,bcdef
KMP演算法引入了一個F陣列(在很多文章中會稱為next,但筆者更習慣用F,這更方便表達),F[i]表示的是前i的字元組成的這個子串最長的相同字首字尾的長度!
怎麼理解呢?
例如字串aababaaba的相同字首字尾有a和aaba,那麼其中最長的就是aaba。
KMP演算法的難理解之處與本文敘述的約定
在繼續我們的講述之前,筆者首先講一下為什麼KMP演算法不是很好理解。
雖然說網上關於KMP演算法的部落格、教程很多,但筆者查閱很多資料,詳細講述過程及原理的不多,真正講得好的文章在定義方面又有細微的不同(當然,真正寫得好的文章也有,這裡就不一一列舉),比如說有些從1開始標號,有些next表示的是前一個而有些是當前的,通讀下來,難免會混亂。
那麼,為了防止讀者在接下來的內容中感到和筆者之前學習時同樣的困惑,在這裡先對下文做一些說明和約定。
1.本文中,所有的字串從0開始編號
2.本文中,F陣列(即其他文章中的next),F[i]表示0~i的字串的最長相同字首字尾的長度。
F陣列的運用
那麼現在假設我們已經得到了F的所有值,我們如何利用F陣列求解呢?
我們還是先給出一個例子(筆者用了好長時間才構造出這一個比較典型的例子啊):
A="abaabaabbabaaabaabbabaab"
B="abaabbabaab"
當然讀者可以通過手動模擬得出只有一個地方匹配
abaabaabbabaaabaabbabaab
那麼我們根據手動模擬,同樣可以計算出各個F的值
B="a b a a b b a b a a b "
F= 0 0 1 1 2 0 1 2 3 4 5(2017.7.25 Update 這裡之前有一個錯誤,感謝@ 歌古道指正)(2017.7.29 Update 好吧,這裡原來還有一個錯誤,已經更正啦感謝@iwangtst)
我們再用i表示當前A串要匹配的位置(即還未匹配),j表示當前B串匹配的位置(同樣也是還未匹配),補充一下,若i>0則說明i-1是已經匹配的啦(j同理)。
首先我們還是從0開始匹配: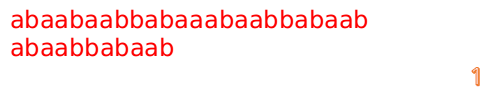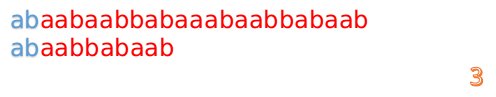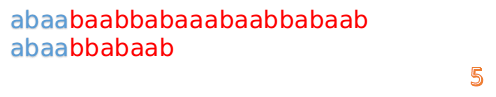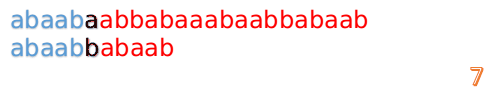
此時,我們發現,A的第5位和B的第5位不匹配(注意從0開始編號),此時i=5,j=5,那麼我們看F[j-1]的值:
F[5-1]=2;
這說明我們接下來的匹配只要從B串第2位開始(也就是第3個字元)匹配,因為前兩位已經是匹配的啦,具體請看圖: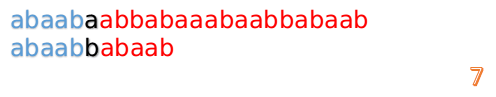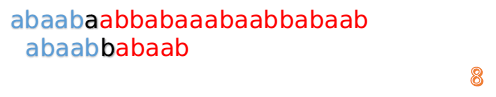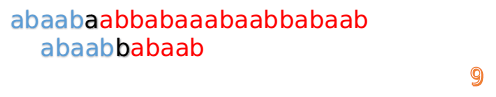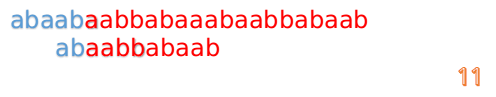
然後再接著匹配: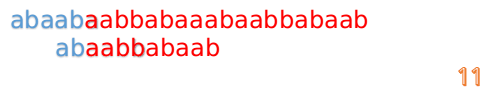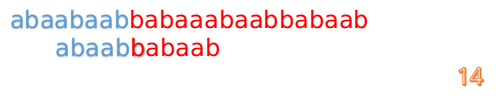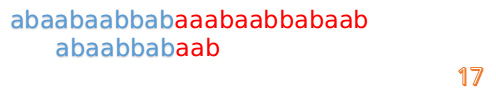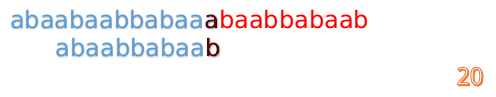
我們又發現,A串的第13位和B串的第10位不匹配,此時i=13,j=10,那麼我們看F[j-1]的值:
F[10-1]=4
這說明B串的0~3位是與當前(i-4)~(i-1)是匹配的,我們就不需要重新再匹配這部分了,把B串向後移,從B串的第4位開始匹配: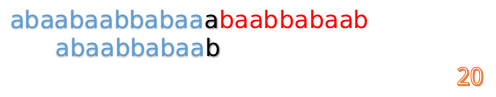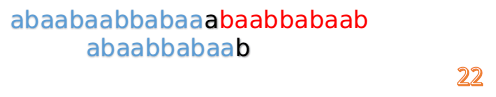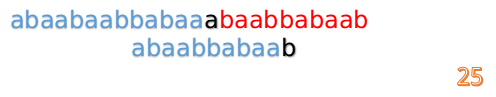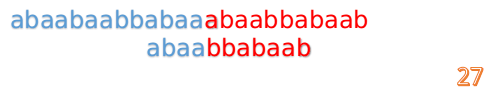
這時我們發現A串的第13位和B串的第4位依然不匹配
此時i=13,j=4,那麼我們看F[j-1]的值:
F[4-1]=1
這說明B串的第0位是與當前i-1位匹配的,所以我們直接從B串的第1位繼續匹配:
但此時B串的第1位與A串的第13位依然不匹配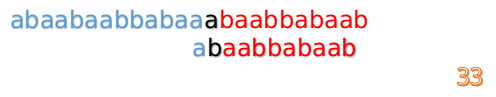
此時,i=13,j=1,所以我們看一看F[j-1]的值:
F[1-1]=0
好吧,這說明已經沒有相同的前後綴了,直接把B串向後移一位,直到發現B串的第0位與A串的第i位可以匹配(在這個例子中,i=13)
再重複上面的匹配過程,我們發現,匹配成功了!
這就是KMP演算法的過程。
另外強調一點,當我們將B串向後移的過程其實就是i++,而當我們不動B,而是匹配的時候,就是i++,j++,這在後面的程式碼中會出現,這裡先做一個說明。
最後來一個完整版的(話說做這些圖做了好久啊!!!!):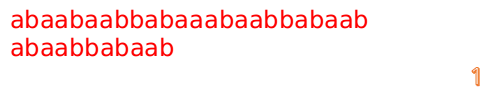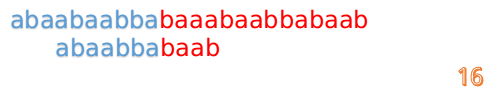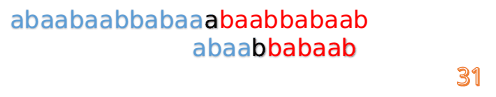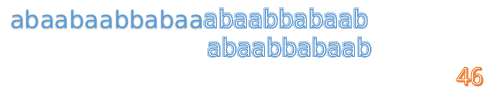
F陣列的求解
既然已經用這麼多篇幅具體闡述瞭如何利用F陣列求解,那麼如何計算出F陣列呢?總不能暴力求解吧。
KMP的另外一個巧妙的地方也就在這裡,它利用我們上面用B匹配A的方法來計算F陣列,簡單點來說,就是用B串匹配B串自己!
當然,因為B串==B串,所以如果直接按上面的匹配,那是毫無意義的(自己當然可以完全匹配自己啦),所以這裡要變一變。
因為上面已經講過一部分了,先給出計算F的程式碼:
for (int i=1;i<m;i++)
{
int j=F[i-1];
while ((B[j+1]!=B[i])&&(j>=0))
j=F[j];
if (B[j+1]==B[i])
F[i]=j+1;
else
F[i]=-1;
}首先可以確定的幾點是:
1.F[0]=-1 (雖說這裡應該是0,但為了方便判越界,同時為了方便判斷第0位與第i位,程式中這裡置為-1)
2.這是一個從前往後的線性推導,所以在計算F[i]時可以保證F[0]~F[i-1]都是已經計算出來的了
3.若以某一位結尾的子串不存在相同的字首和字尾,這個位的F置為-1(這裡置為-1的原因同第一條一樣)
重要!:另外,為了在程式中表示方便,在接下來的說明中,F[i]=0表示最長相同字首字尾長度為1,即真實的最長相同字首字尾=F[i]+1。(重要的內容要放大)
為什麼要這樣設定呢,因為這時F[i]代表的就不僅僅與前後綴長度有關了,它還代表著這個字首的最後一個字元在子串B中的位置。
所以,之前上面列出的F值要變一下(這裡用'_'輔助對齊):
B="a _b a a b _b a b a a b "
F= -1 -1 0 0 1 -1 0 1 2 3 4
那麼,我們同樣可以推出,求解F的思路是:看F[i-1]這個最長相同字首字尾的後面是否可以接i,若可以,則直接接上,若不可以,下面再說。
舉個例子:
還是以B="abaabbabaab"為例,我們看到第2個。
B="a b a a b b a b a a b"
F=-1 -1
此時這個a的前一個b的F值為-1,所以此時a不能接在b的後面(b的相同最長字首字尾是0啊),此時,j=-1,所以我們判斷B[j+1]與B[2],即B[0]與B[2]是否一樣。一樣,所以F[2]=j+1=0(代表前0~2字元的最長相同字首字尾的字首結束處是B[0],長度為0+1=1)。
再來看到第3個:
B="a b a a b b a b a a b"
F=-1 -1 0
開始時,j=F[3-1]=0,我們發現B[j+1=1]!=B[i=3],所以j=F[j]=-1,此時B[j+1=0]==B[i=3],所以F[3]=j+1=0。
最後舉個例子,看到第4個
B="a b a a b b a b a a b"
F=-1 -1 0 0
j首先為F[4-1]=0,我們看到B[j+1=1]==B[i],所以F[i]=j+1=1。
後面的就請讀者自己慢慢推導了。再強調一遍,我們這樣求出來的F值是該最長相同字首字尾中的字首的結束字元的陣列位置(從0開始編號),如果要求最長相同字首字尾的長度,要輸出F[i]+1。
程式碼
求解F陣列:
for (int i=1;i<m;i++)
{
int j=F[i-1];
while ((B[j+1]!=B[i])&&(j>=0))
j=F[j];
if (B[j+1]==B[i])
F[i]=j+1;
else
F[i]=-1;
}利用F陣列尋找匹配,這裡我們是每找到一個匹配就輸出其開始的位置:
while (i<n)
{
if (A[i]==B[j])
{
i++;
j++;
if (j==m)
{
printf("%d\n",i-m+1);//注意,這裡輸出的位置是從1開始標號的,如果你要輸出從0開始標號的位置,應該是是i-m.這份程式碼是我做一道題時寫的,那道題要求輸出的字串位置從1開始標號.感謝@Draymonder指出了這個疏漏,更多內容請看評論區
j=F[j-1]+1;
}
}
else
{
if (j==0)
i++;
else
j=F[j-1]+1;
}
}
例題請見下一篇文章。
詳情請訪問此文章來源地:http://www.cnblogs.com/SYCstudio/p/7194315.html
多謝大佬分享~