
推薦系統1—好的推薦系統的效能
儘管不同的網站使用不同的推薦系統技術,但總地來說,幾乎所有的推薦系統應用都是由前臺的展示頁面、後臺的日誌系統以及推薦算法系統3部分構成的。
評測推薦系統有3種方法——離線實驗、使用者調查和線上實驗。
下面介紹各種推薦系統的評測指標。這些評測指標可用於評價推薦系統各方面的效能。
使用者滿意度
預測準確度
預測準確度度量一個推薦系統或者推薦演算法預測使用者行為的能力。由於離線的推薦演算法有不同的研究方向,因此下面將針對不同的研究方向介紹它們的預測準確度指標。
評分預測
評分預測的預測準確度一般通過均方根誤差(RMSE)和平均絕對誤差(MAE)計算。對於測試集中的一個使用者u和物品i,令rui是使用者u對物品i的實際評分,而rui(hat)是推薦演算法給出的預測評分,那麼RMSE的定義為:
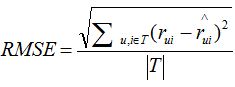
MAE採用絕對值計算預測誤差,它的定義為:
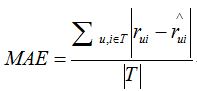
其中,T表示評分資料的長度。
TopN推薦
網站在提供推薦服務時,一般是給使用者一個個性化的推薦列表,這種推薦叫做TopN推薦。TopN推薦的預測準確率一般通過準確率(precision)/召回率(recall)度量。令R(u)是根據使用者在訓練集上的行為給使用者作出的推薦列表,而T(u)是使用者在測試集上的行為列表。那麼,推薦結果的召回率定義為:
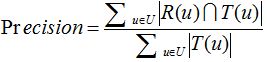
推薦結果的準確率定義為:
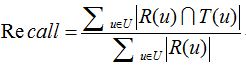
有的時候,為了全面評測TopN推薦的準確率和召回率,一般會選取不同的推薦列表長度N,計算出一組準確率/召回率,然後畫出準確率/召回率曲線(precision/recall curve)。
覆蓋率
覆蓋率(coverage)描述一個推薦系統對物品長尾的發掘能力。覆蓋率有不同的定義方法,最簡單的定義為推薦系統能夠推薦出來的物品佔總物品集合的比例。但是上面的定義過於粗略。覆蓋率為100%的系統可以有無數的物品流行度分佈。為了更細緻地描述推薦系統發掘長尾的能力,需要統計推薦列表中不同物品出現次數的分佈。如果所有的物品都出現在推薦列表中,且出現的次數差不多,那麼推薦系統發掘長尾的能力就很好。因此,可以通過研究物品在推薦列表中出現次數的分佈描述推薦系統挖掘長尾的能力。如果這個分佈比較平,那麼說明推薦系統的覆蓋率較高,而如果這個分佈較陡峭,說明推薦系統的覆蓋率較低。在資訊理論和經濟學中有兩個著名的指標可以用來定義覆蓋率。第一個是資訊熵,第二個是基尼係數。
多樣性
新穎性
驚喜度