
大數據-實時推薦系統最主流推薦系統itemCF和userCF
阿新 • • 發佈:2018-09-09
我們 ase 混合推薦 相似度 .net div == 其他 moto 
推薦系統的分類:
基於應用領域分類:電子商務推薦,社交好友推薦,搜索引擎推薦,信息內容推薦
基於設計思想:基於協同過濾的推薦,基於內容的推薦,基於知識的推薦,混合推薦
基於使用何種數據:基於用戶行為數據的推薦,基於用戶標簽的推薦,基於社交網絡數據,基於上下文信息(時間上下文,地點上下文等等)
協同過濾:
協同過濾的基本思想(基於用戶):
協同過濾一般是在海量的用戶中發掘出一小部分和你品味比較類似的,在協同過濾中,這些用戶成為鄰居,然後根據他們喜歡的其他東西組織成為一個排序的目錄作為推薦給你
核心問題:
如何確定一個用戶是不是和你有相似的品味?
如何將鄰居們的喜好組織成一個排序的目錄?
實現協同過濾的步驟:
收集用戶偏好
找到相似的用戶或物品
計算推薦(基於用戶,基於物品)
收集用戶偏好的方法:
通過收集用戶把用戶的特征變成向量(一般變成向量前需要降噪(拋去或者修改),歸一化)
相似度:
當已經對用戶行為迚行分析得到用戶喜好後,我們可以根據用戶喜好計算相似用戶和物品,然後基於相似用戶戒者物品迚行推薦,這就是最典型的CF 的兩個分支:基於用戶的CF 和基於物品的CF。這兩種方法都需要計算相似度
把數據看成空間中的向量(降噪,歸一化)
距離的計算:
歐幾裏得距離
其它距離
基於距離計算相似度:

基於相關系數計算相似度:
皮爾遜相關系數:

基於夾角余弦計算相似度:

基於Tanimoto系數計算相似度:

同現相似度:

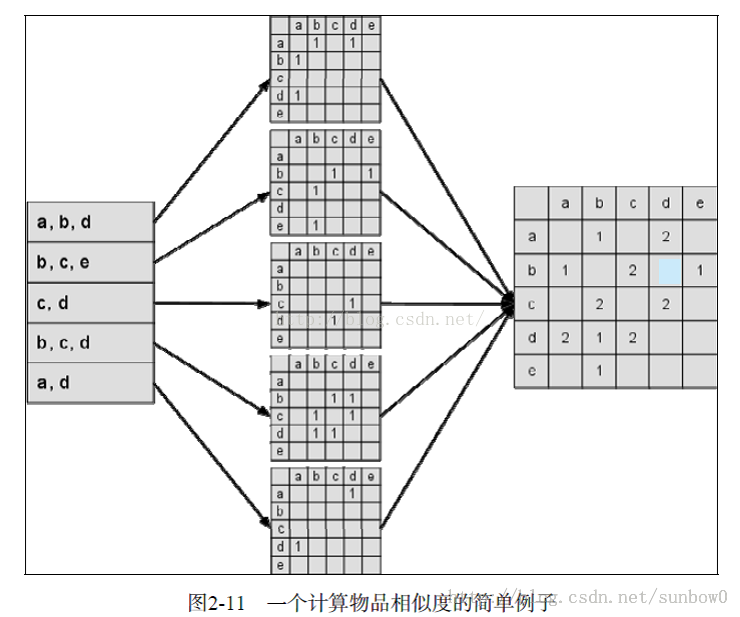
同現相似度模型:根據用戶評分數據表,生成物品的相似矩陣;
鄰居(用戶,物品)的圈定:
固定數量的鄰居:K-neighborhoods
基於相似度門檻的鄰居:Threshold-based neighborhoods
大數據-實時推薦系統最主流推薦系統itemCF和userCF