
【論文閱讀】Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
【論文閱讀】Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
這是一篇2017CVPR的論文,我感覺這篇論文最大的貢獻就是提出了kinetics資料集,這個資料集與之前的行為識別資料集相比有質的飛躍。同時文章也提出一種將2D卷積網路擴張成3D卷積網路的思想,使3D卷積網路可以收益於2D卷積網路的發展。感覺以後行為識別越來越玩不起了,面對這麼大的資料,想起我那一張破顯示卡,不禁流下了貧窮的淚水。
簡介
- 我們知道在ImageNet上預訓練的2DCNN對於其他的視覺任務(比如目標檢測)是很有幫助的,那麼在大的行為識別資料集上預訓練的網路在其他視訊任務中也可能很有幫助,但是現在沒有大的行為識別資料集,怎麼辦?於是文章首先發布了一個超大的trimmed行為識別資料集kinetics。
- 提出了大資料集kinetics,文章又把之前的經典方法都在這個資料集上做了實驗,並且實驗了在kinetics上預訓練的模型對於小資料集的結果是否會有提升,實驗結果表明使用kinetics預訓練的模型能得到更高的準確率。
- 最後文章提出了一種I3D(Two-Stream Inflated 3D ConvNets)模型,該3DCNN模型是由2DCNN Inception-V1擴張而來,並且可以使用在ImageNet上預訓練的引數,實驗結果表明這個模型在各個標準資料集上都取得了當時最好的結果。
正文
kinetics資料集
Kinetics資料集包含了400類人體行為,每一類至少有400個視訊,這些視訊全都來源於YouTube,每個視訊時長大約為10s,一共有30多萬個視訊。視訊中的行為可以被分為三類:單一的人體動作、人與人的互動、人與物的互動。這些行為都被分的非常細,有些需要通過時間推理來區分(例如不同型別的游泳),還有一些動作需要通過物體的視覺特徵來區分(例如彈奏不同的樂器)。
在kinetics資料集上實驗的經典模型
文章復現了經典的模型,如CNN+LSTM的網路、3D卷積網路、基礎雙流網路,雙流卷積融合網路。各種經典網路模型的結構如下圖所示:
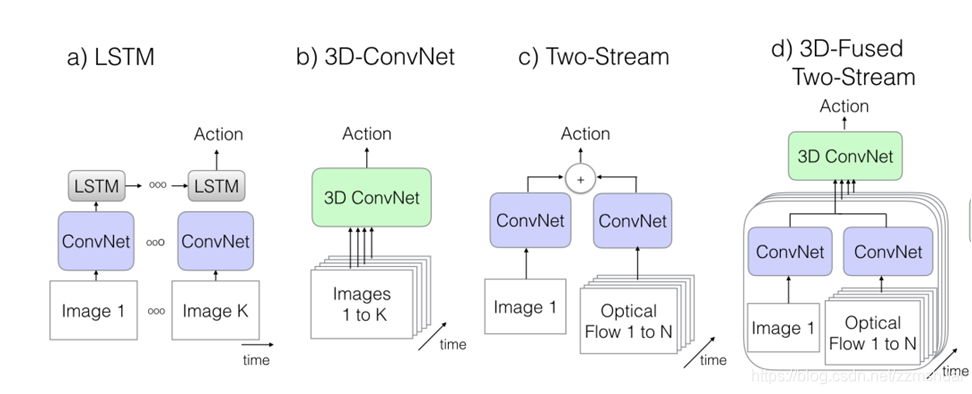
- 上圖(a)中為CNN+LSTM的模型結構,其中的2DCNN模型為Inception-V1,CNN最後一層的全域性平均池化結果作為LSTM網路的輸入,該LSTM網路中包含有batch normalization[1],最後LSTM的輸出連線一個全連線層用來分類,該模型在訓練的時候使用交叉熵損失函式,損失為所有時刻損失的加和,但是測試的時候只看最後一個時刻的輸出的結果。該網路的輸入從25FPS的視訊中採集的視訊段,每隔5幀採集一幀作為輸入。訓練的時候輸入的視訊時長為25幀,測試的時候一個視訊擷取2個視訊段,預測結果取平均。
- 上圖(b)中為C3D的模型結構,之前的博文中有詳細地介紹連結地址。本文使用的C3D在原來的基礎上做了一些改進,在每一個卷積層與全連線層後面加入了batch normalization,同時第一個池化層的時間步長也改為了2。訓練時輸入的視訊段長度為16,測試的時候一個視訊分為25段,預測結果為所有視訊段的平均。
- 上圖(c)中為基礎雙流網路[1],本文中的雙流網路每一個流中的CNN使用的是Inception-V1。訓練的時候appearance流的輸入為隨機取樣的一幀,motion流為10幀堆疊的光流。測試的時候一個視訊分為25段,預測結果為所有視訊段結果的平均。
- 上圖(d)中為融合雙流網路[2],該網路原理上相當於對一個視訊分成多段,在每一段上都使用基礎雙流網路計算結果,最後對所有視訊段上雙流網路的結果進行卷積融合。雙流網路中的CNN也是Inception-V1,卷積融合層的結構為:(3DCNN(3x3x3)-3D池化層(3x3x3)-全連線層),卷積融合層的所有引數使用高斯噪聲初始化。訓練階段,網路的輸入為5幀RGB視訊幀,50幀光流幀,測試階段,一個視訊被分成5段,預測結果為所有視訊段結果的平均。
下表中給出了各種經典模型在訓練和測試時的輸入時間長度。

Two-Stream Inflated 3D ConvNets 網路結構
首先顧名思義,”Inflated“就說明這是一種將2DCNN擴充為3DCNN的網路,2DCNN網路使用的也是InceptionV1網路,其擴充為3D後的結果如下圖所示:

在將2DCNN擴張成3DCNN時,有以下幾點需要考慮:
怎麼inflate?
文章中使用的方法是直接將尺寸為 的2D卷積核擴充為尺寸為 的3D卷積核。
如何使用ImageNet預訓練的引數?
因為該3D網路是由2D網路擴充而來,所以如何才能將2D網路ImageNet預訓練的引數應用於3D網路呢?文章認為如果將一張圖片沿著時間複製,可以得到一段”boring video“,即”boring video“每個時刻的視訊幀都是這張圖片。所以3D卷積核在這段”boring video“上的響應應該和2D卷積核在這張圖片上的響應是數值相同的。所以3D卷積核使用ImageNet預訓練引數的方法是對2D卷積核的引數沿著時間複製,最後除以3D卷積核的時間維度的大小即可。
擴充全部3D卷積核的時間維度等於空間維度合適嗎?
將所有的 2D核擴充為 3D核可能並不合適,因為時間維度的最優值可能受到幀率等的影響,所以文章通過實驗確定了最優的3D核時間維度的尺寸。
如何進一步提升I3D的效能?
為了進一步提升網路的效能,文章在網路中加入了光流的輸入,RGB視訊和堆疊的光流分別輸入到3D卷積網路中得到輸出結果,最終的結果為這兩個流的結果的融合。
所以最終的I3D網路的結構如下圖所示:
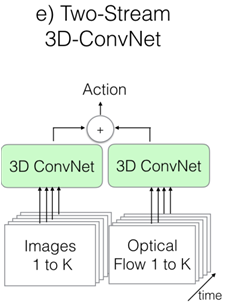
其輸入輸出的視訊時間長度如下圖:

實驗細節
訓練階段:除了C3D網路,所有的網路都使用了Imagenet預訓練的Inception-v1,Inception-v1網路也做了一些改進,在每一個卷積層後邊都添加了batch normalization 和relu。優化方法為動量SGD,動量設為0.9,3D網路使用64個GPU而其他網路使用32個GPU並行訓練(土豪!!),模型在ucf101,hmdb51,minikinetics和kinetics資料集上大約分別訓練了35k,110k,5k,5k步。同時使用了空間隨機裁剪,水平翻轉等資料增強的方法。如果視訊的時長比要求的輸入長度還要短,則對視訊進行迴圈。
測試階段:輸入的視訊幀直接裁剪成224x224,整個視訊的結果是各個視訊段的平均,同時也使用了水平翻轉的資料增強的方法,增強的資料的結果與原始結果的平均作為最終的結果。
實驗結果
模型在各資料集上的結果
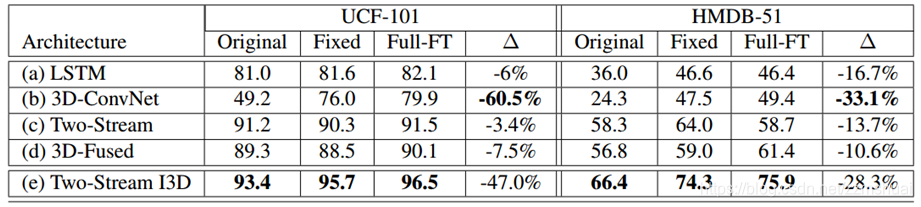
所有模型在ucf101,hmdb51,mini-kinetics資料集上的實驗結果如下表所示:

從表中可以看出
- 在非常小的資料集(如hmdb-51)上I3D也是取得了非常好的效果,文章認為這是因為I3D使用了Imagenet預訓練的結果。
- 不考慮hmdb51,所有的模型在mini-kinetics資料集上的結果都很低,說明該資料集還是有一定的挑戰性的。
- 有意思的是在所有的資料集上模型的表現效能順序大致相同,看來除了資料,好的模型也是關鍵。
- C3D在大資料集上表現更好,看來3DCNN是真的”data hungry“。
- 其他資料集光流的準確率都高於RGB,但是mini-kinetics不是,因為該資料集中包含有大量的相機運動,所以光流的質量不行。
kinetics預訓練的引數是否更優?
為了驗證使用kinetics預訓練的引數是否更優,文章設計了3種實驗:
- 直接在資料集上訓練,不使用預訓練引數
- 使用mini-kinetics預訓練的引數,僅訓練最後的全連線層
- 使用mini-kinetics預訓練的引數,微調網路的全部引數
其實驗結果如下表所示:
可以看到所有的方法基本都會受益於mini-kinetics的預訓練,只是不同的方法提升的效果不同。
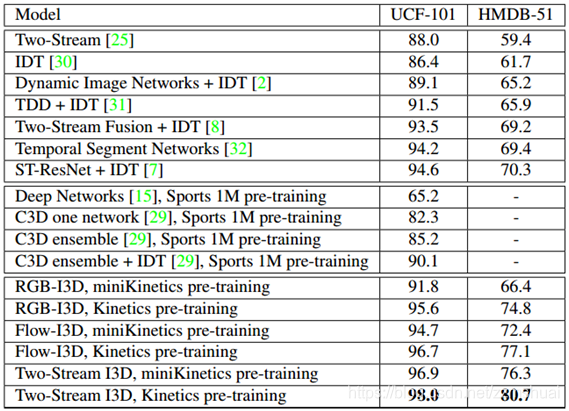
I3D的實驗結果
I3D最終的實驗結果如下表所示,可以看到有了kinetics的預訓練,其結果是相當的nice。
探索性實驗
文章對I3D的第一層卷積核進行了視覺化,如下圖所示:

上圖中,列表示時間,第一行為光流輸入的卷積核,第二行為RGB輸入的卷積核,第三行是ImageNet預訓練的Inception-V1的卷積核,可以看到光流核和原始2D核相似,所以從光流提取運動資訊就是直接提取光流的空間資訊。RGB核與原始2D核相差很大,因為其要同時提取時間運動資訊。
[1] Simonyan, Karen, and Andrew Zisserman. “Two-stream convolutional networks for action recognition in videos.” In Advances in neural information processing systems, pp. 568-576. 2014.
[2] Feichtenhofer, Christoph, Axel Pinz, and Andrew Zisserman. “Convolutional two-stream network fusion for video action recognition.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1933-1941. 2016.