
【論文閱讀】韓鬆《Efficient Methods And Hardware For Deep Learning》節選《Learning both Weights and Connections 》
Pruning Deep Neural Networks
本節內容主要來自NIPS 2015論文《Learning both Weights and Connections for Efficient Neural Networks》。
這部分主要介紹如何剪枝網路,及如何迭代訓練已剪枝的網路以保證準確率。同時提供方法證明剪枝模型帶來的加速和能源效率提升。
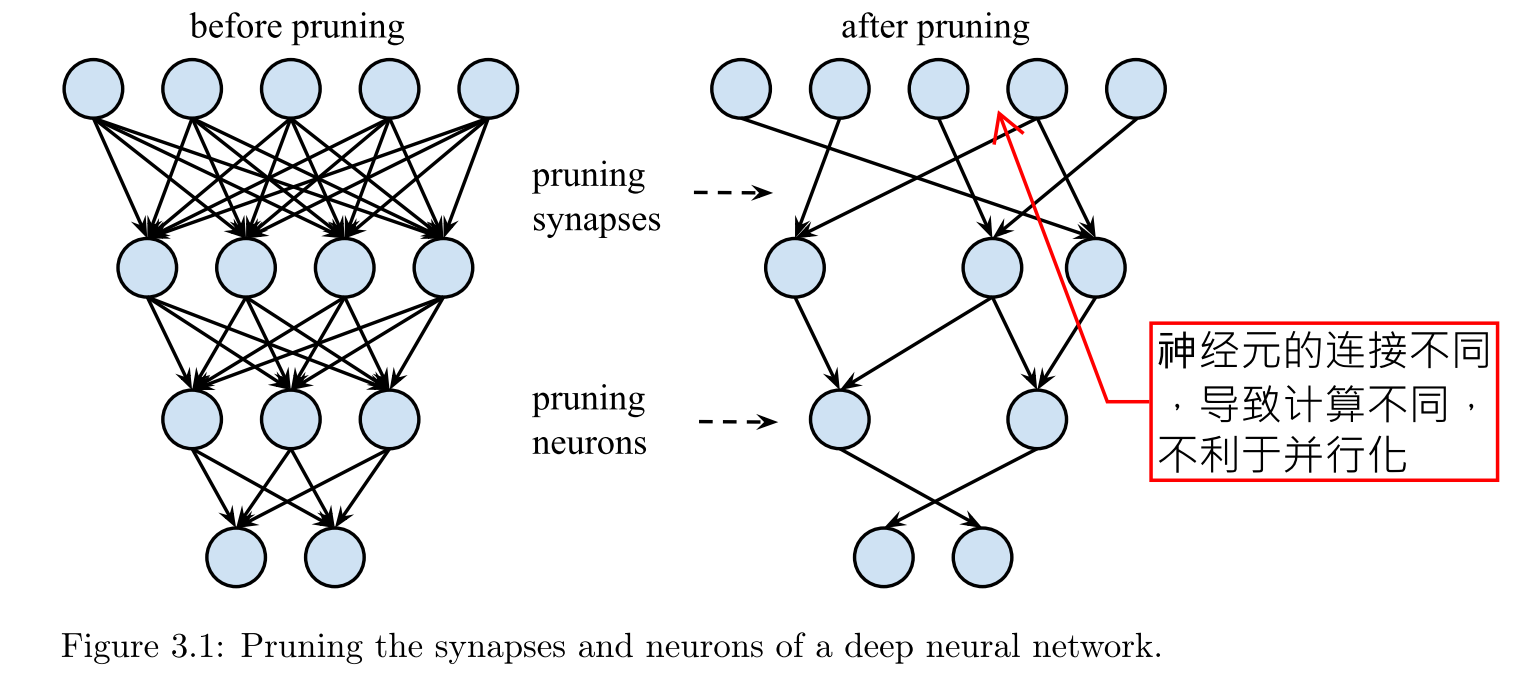
剪枝方法
- 訓練模型,training connectivity
- 剪枝連線,pruning connections
- 重訓練保留的權重(補償被剪枝的連線),retraining the remaining weights
後兩步可以迴圈進行。步驟及演算法如下
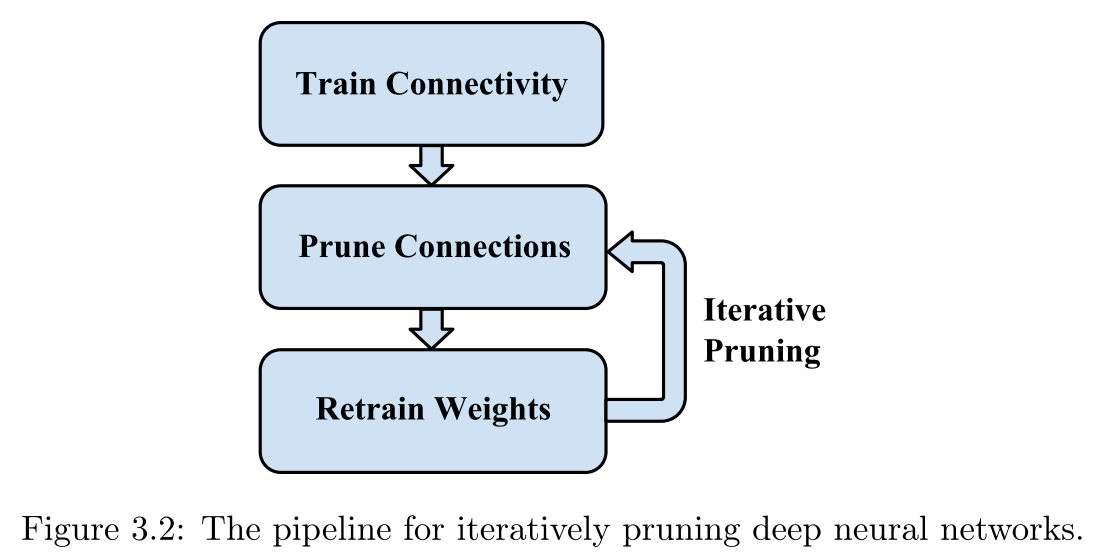
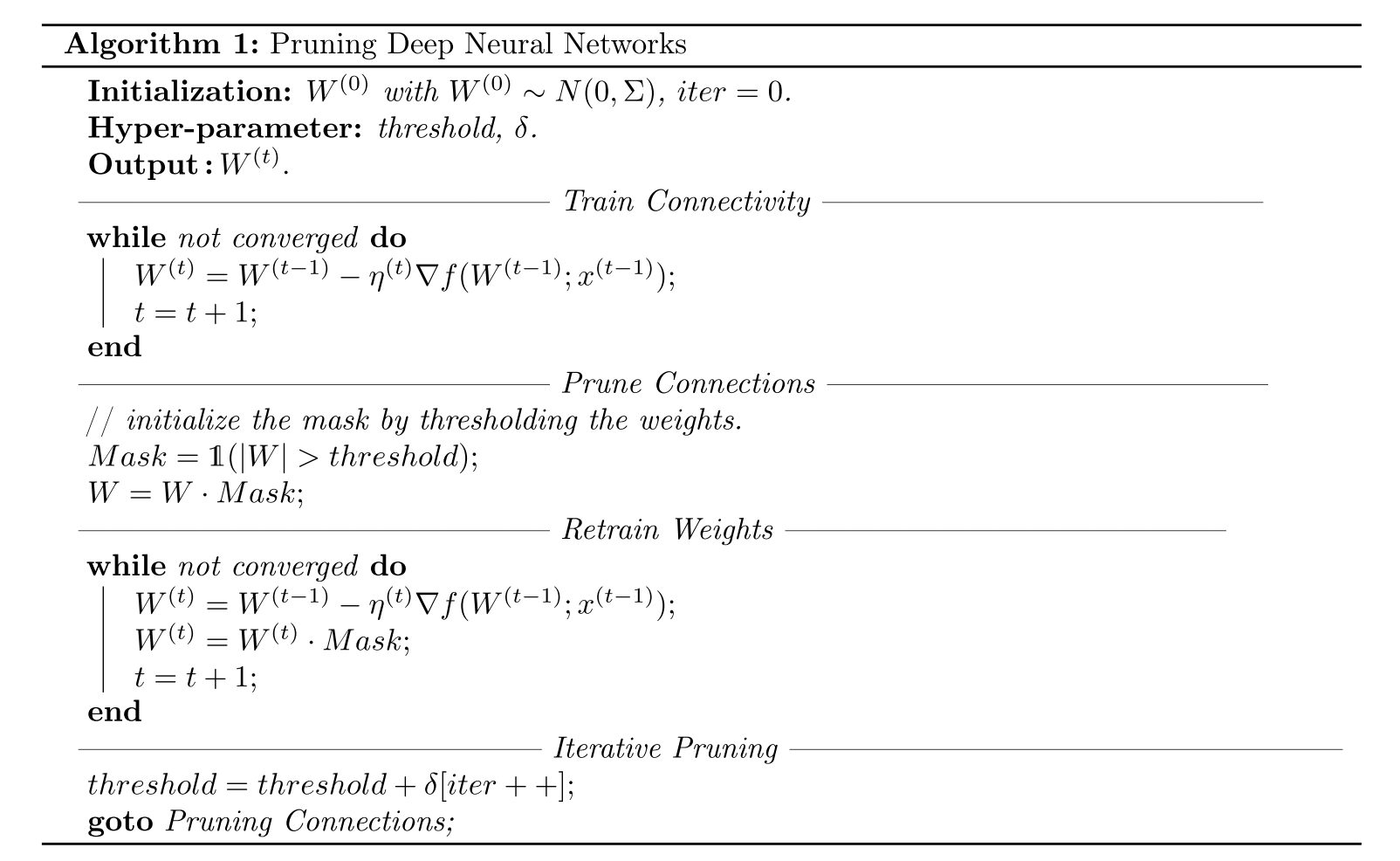
演算法步驟:
- Train Connectivity,正常的訓練網路,但這一步不是學習最終的權重值,而是學習到哪些連線是重要的,重要程度就是權值的絕對值來衡量。if the absolute value is small, then we consider this weight unimportant
- Prune Connections,剪枝權重絕對值小(設定一個閾值)的連線。這個閾值是一個關於壓縮率和準確率的平衡值。The threshold is a hyper-parameter that depends on where one wants to fall on the trade-off curve between compression ratio and prediction accuracy。模型剪枝具體實現採用一種掩碼的方式,小於閾值的權重的mask設為0,大於閾值的掩碼設為1,這樣權重張量和Mask tensor點乘就可以實現剪枝。
- Retrain Weights,重新訓練剪枝之後的稀疏連線網路。若不重新訓練,直接採用剪枝之後的稀疏網路,準確率會大幅降低。
- Iterative Pruning,迴圈迭代進行剪枝與重訓練。
- 學習率設定經驗:訓練連線開始LR1 > 重訓練開始LR > 訓練連線的最後階段的學習率LR2。Because pruning moved the weights away from the original local minimum, the learning rate should be larger than at the end of the Train Connectivity phase
- Dropout Rate設定經驗:,其中Dr 表示重訓練階段的dropout率,D0 表示開始訓練的dropout率
- 重訓練階段,權重值最好保持剪枝之後得到的權重值(Train Connectivity階段得到的權重),而不是0初始化或者隨機初始化,完全的從零開始學習。
以上介紹了剪枝的方法、學習率和失活率的設定。
剪枝對於硬體的效率提升
一方面,剪枝使得模型引數量和計算量更小,但同時它使得保留的計算規則性降低,這使得硬體的並行化更加困難。之後我們會討論一種規則化的剪枝,使得模型稀疏的同時解決並行化問題。
**Load-Balance-Aware Pruning。**載入平衡的剪枝。剪枝首先帶來的一個災難是,非零權重(保留下來的)分佈不均勻,計算的時候,硬體的處理單元(Processing Elements,PEs)執行的計算運算元目不同,那麼執行更少計算量的PE就需要等待多計算量的PE完成計算。所以PE上的負載不均衡會造成真實效能和峰值效能的gap。而負載平衡的剪枝就是解決這個問題的,可以得到一個對硬體友好的稀疏網路。方法:對裁剪新增一個約束,所有被分配到每個PE上的子引數矩陣滿足相同的稀疏度,這樣各PE的工作負載相同,減少了空閒等待。
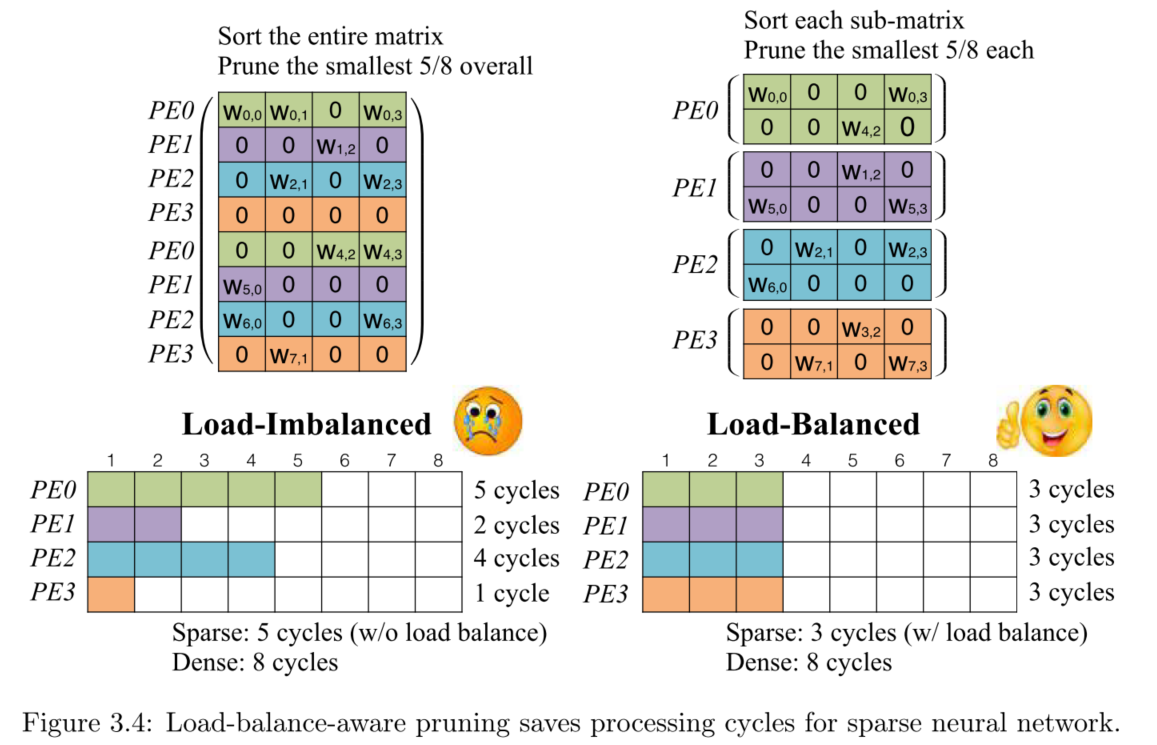
如上圖所示,有4個計算單元PE,所以引數矩陣被分為4個子矩陣以便可以平行計算。上述兩種方案雖然稀疏度相同,但是全域性稀疏會造成負載不均衡,而子矩陣服從總的稀疏度可以滿足在滿足稀疏要求的同時實現硬體的負載均衡。上圖中左圖的計算時間需要5個cycles,PE1、PE2和PE3需要等PE0完成計算,而右圖方案3個cycles就完成計算。
Pruning with Structure,結構化剪枝。剪枝的粒度是一個需要權衡的問題。上述的元素級的剪枝使得access/fetch操作不規則,相應就有按行剪枝、2D kernel剪枝、3D filter剪枝。
考慮剪枝之後的兩個問題,1)硬體訪問非零引數。2)記錄非零引數索引。
細粒度的剪枝(individual element)使得權重的訪問不規則(整體子矩陣間分佈一致,但內部分佈各異),同時對非零權重的索引需要按元素建立。而粗粒度的剪枝可以節約索引。但是粗粒度剪枝的問題是保持相同的準確率下需要犧牲壓縮率,粒度粗了,壓縮精度就下降了,但好處是粗粒度剪枝(如filter級)會使的剩下的模型保持dense,這樣計算就是規則的,便於並行化。
至於儲存大小問題是不定的,剪枝粒度細,則壓縮率高,同時索引開銷高,反之剪枝粒度粗,則壓縮率低,但是索引開銷小。
實驗
框架採用Caffe,修改Caffe,增加Mask,可以使網路操作忽略被剪枝的引數。
模型:
- Lenet-300-100 and Lenet-5 on MNIST
- AlexNet, VGG-16, Inception-V1, SqueezeNet, ResNet-18 and ResNet-50 on ImageNet
結果:
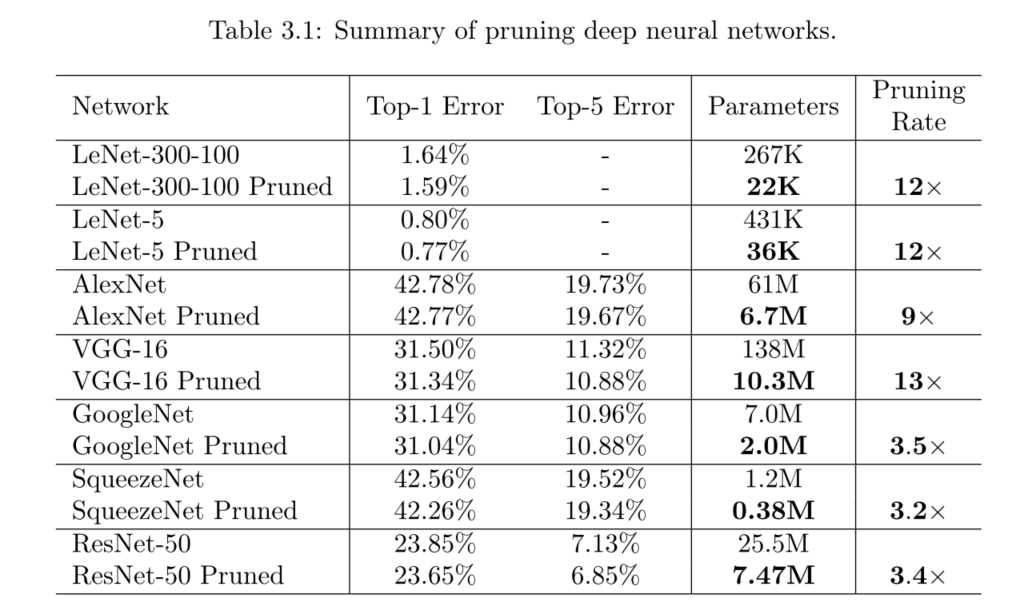
Purning For MNIST
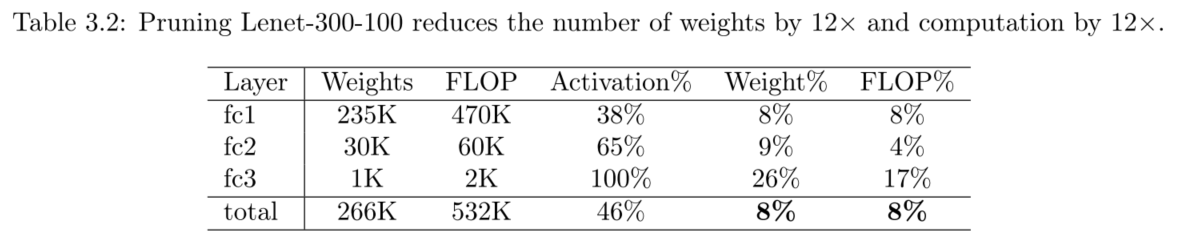
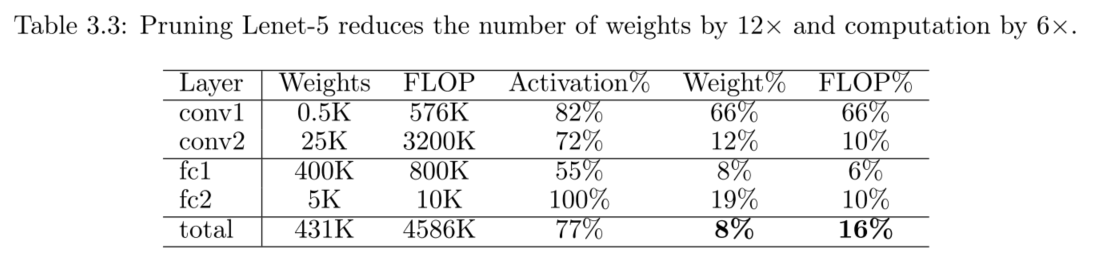
剪枝的同時會檢測到視覺的注意力區域(被剪枝的都是不受關注的區域,如無意義的邊角區域,保留的很多是影象的中央,MNIST資料集下)。

Pruning For ImageNet
用AlexNet和VGG-16網路在ImageNet ILSVRC-2012資料集上做了實驗,在不影響準確率的前提下剪枝效果如下。
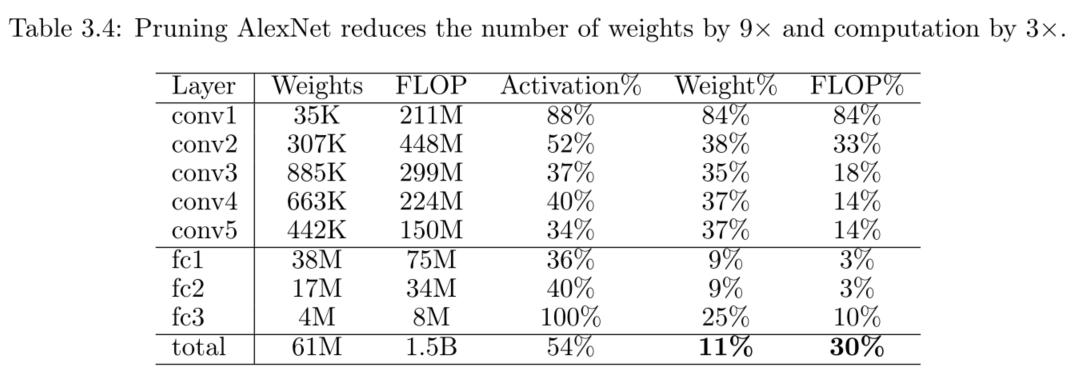
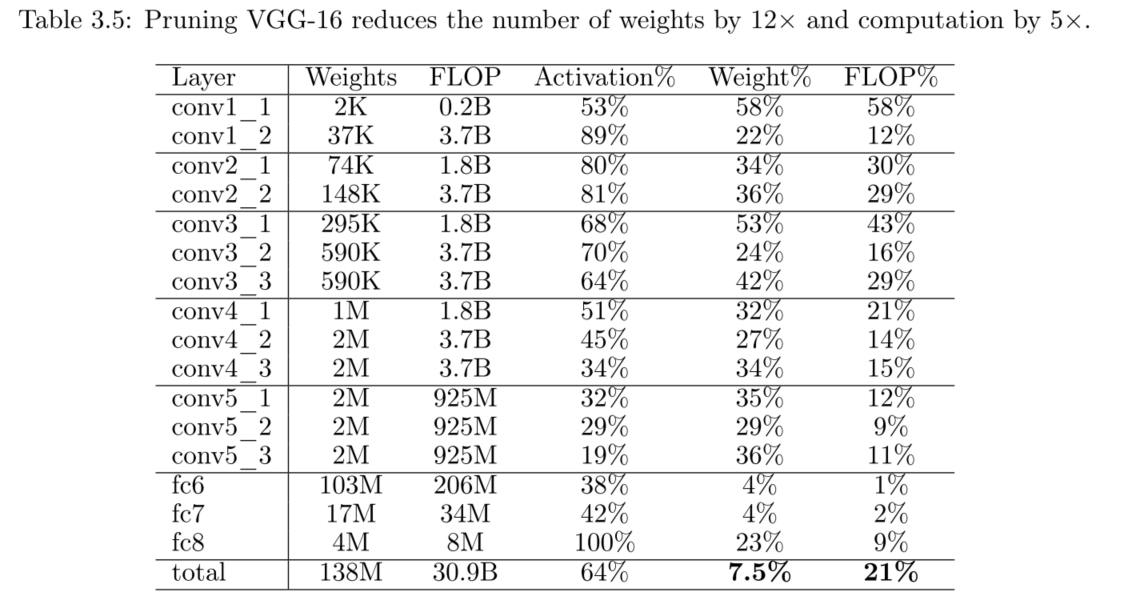
除了上述 卷積+全連線的網路,還在全卷積網路上進行了實驗。實驗證明全卷積網路依然可以在不損失準確率的情況很好的被剪枝,剪枝率都近似在70%(剩餘30%左右的非零引數)
除此之外,還在RNNs和LSTMs上進行實驗,結果依然有效,詳情見論文。
以上為該論文第一部分,主要介紹剪枝方法即效果,但目前為止,該工作還很難利用CPG/GPU的並行處理能力。