
【論文閱讀】Sequence to Sequence Learning with Neural Networks
看論文時查的知識點
前饋神經網路就是一層的節點只有前面一層作為輸入,並輸出到後面一層,自身之間、與其它層之間都沒有聯絡,由於資料是一層層向前傳播的,因此稱為前饋網路。
BP網路是最常見的一種前饋網路,BP體現在運作機制上,資料輸入後,一層層向前傳播,然後計算損失函式,得到損失函式的殘差,然後把殘差向後一層層傳播。
卷積神經網路是根據人的視覺特性,認為視覺都是從區域性到全域性認知的,因此不全部採用全連線(一般只有1-2個全連線層,甚至最近的研究建議取消CNN的全連線層),而是採用一個滑動視窗只處理一個區域性,這種操作像一個濾波器,這個操作稱為卷積操作(不是訊號處理那個卷積操作,當然卷積也可以),這種網路就稱為卷積神經網路。
目前流行的大部分網路就是前饋網路和遞迴網路,這兩種網路一般都是BP網路;深度網路一般採用卷積操作,因此也屬於卷積神經網路。在出現深度學習之前的那些網路,基本都是全連線的,則不屬於卷積網路的範圍,但大部分是前饋網路和BP網路。
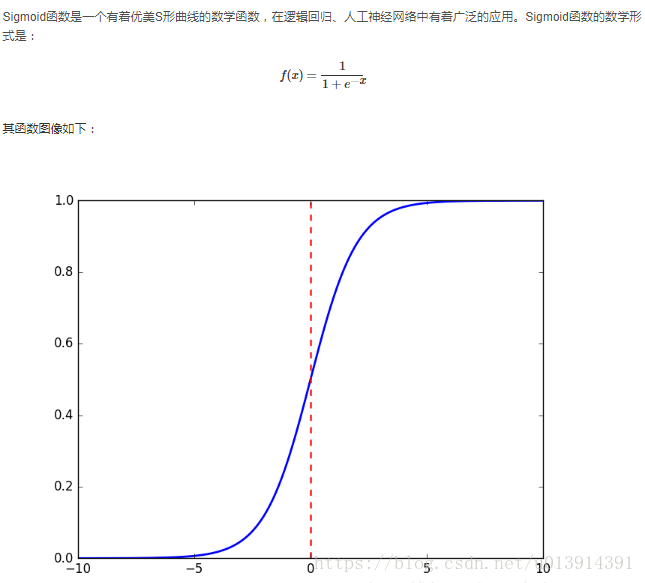
sigmoid函式
softmax函式
原文連結:https://www.cnblogs.com/liuyu124/p/7332476.html

論文
摘要abstract
DNNs很強大,在許多學習任務都表現卓越。DNNs在很多有大量訓練標籤的資料集上表現良好,但是無法完成將序列對映到序列的任務。在這篇論文中,作者提出了一種通用的端到端序列學習方法,它對序列結構的假設最小。
論文亮點
- 使用多層(原文說是4層)的LSTM將input sequence(不定長度的輸入) 對映到一個固定維度的向量。然後使用另外1個LSTM將這個向量解碼輸出。
- 使用本文模型將WMT-14資料集用於翻譯英語到法語的任務中,BLEU(BLEU是一種用於評估從一種自然語言到另一種自然語言的機器翻譯的質量的演算法)得分34.8分。
- 對詞序敏感。同一個句子的主被動語態包容性很好。
- 發現顛倒輸入的句子順序可以顯著提高模型的效能。ex:一個句子是abc,在傳入模型的順序是cba 。據作者講會引入一些短期依賴,從而使模型效能更好。
1引言introduction
- DNNs很靈活也很強大,但是它的輸入和輸出輸出長度必須固定。
- 使用LSTM來解決DNNs對輸入長度必須固定的問題(可變長度的輸入語句對映到一個固定維向量表示)思想是:使用兩個LSTM。一個LSTM用於讀取輸入序列,每次讀取一個時間步長,獲得大的固定維度向量,然後使用另一個LSTM從該向量中提取輸入序列。第2個LSTM本質上就是迴圈神經網路,只不過受輸入序列的限制(依靠第一個LSTM)。
- LSTM在長時間依賴性的資料上的成功,舉例。
2 模型 The model

1. rnn也可以使用兩個rnn來將變長的input sequence轉換到固定維度的向量,但是由於長期依賴關係,訓練RNN很困難。所以不選用RNN。
2. 文章所使用的模型:a.兩個LSTM(一個用於輸入序列,另一個用於輸出序列)。b.4層LSTM(深的LSTMs明顯優於淺的LSTMs)。 c. 交換了input sentences的詞序(這樣使a與α,更近,b與β更近,當然使c與 γ更遠,但是據作者將c與 γ更遠,對模型沒有影響)交換詞序後,令模型效能更好。d.使用EOS(end-of-sentences)作為句子結束的標誌。
3實驗 experiments
資料集 Dataset details
- 使用了固定的詞彙表。160000個最常用的源語言單詞(被翻譯的語言,在本文中為英文)。80000個常用的目標語言單詞(翻譯後的語言,在本文為法語)。
- 不在單詞表的單詞用UNK標記替換。
解碼和重新排序 Decoding and Rescoring
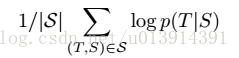
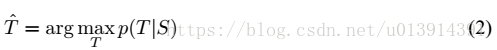
解碼:
- T correct translation
- S source sentence
S 訓練集
最大化對數概率。當訓練完成後,根據公式2尋找最可能的翻譯。一些細節部分暫時還看不大懂==
轉換輸入句子的順序 Reversing the Source Sentences
ex: input sentence:abc,傳入模型的順序是cba。作者認為建立了更多的短期依賴。
訓練詳情Training details
4層LSTM,每層1000個單元
詞向量維度是1000維
輸入詞典大小是160,000,輸出詞典大小是80,000
LSTM的初始引數服從[-0.08,0.08]的均勻分佈
用隨機梯度下降演算法,沒有momentum,開始學習率為0.7,5 epochs之後,每個epoch之後學習率降低一半。
batch是128
每次training batch 之後,計算s=||g||2, g 是梯度除以128,如果s > 5, 令 g = 5g/s。
不同的句子長度不同,為了降低計算量,一個batch中的句子的長度差不多相同。
用8個GPU同時進行處理
模型分析
- 在長句的翻譯中表現良好。
- 主動語態和被動語態包容性好。
- 將input sentences對映到一個固定維度的向量上。