
基於深度學習的目標檢測學習總結
在計算機視覺領域,“目標檢測”主要解決兩個問題:影象上多個目標物在哪裡(位置),是什麼(類別)。
圍繞這個問題,人們一般把其發展歷程分為3個階段:
1. 傳統的目標檢測方法
2. 以R-CNN為代表的結合region proposal和CNN分類的目標檢測框架(R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN, R-FCN)
3. 以YOLO為代表的將目標檢測轉換為迴歸問題的端到端(End-to-End)的目標檢測框架(YOLO, SSD)
下面結合參考資料分別對其做一下總結和自己的理解。
傳統的目標檢測方法

傳統目標檢測的方法一般分為三個階段:首先在給定的影象上選擇一些候選的區域,然後對這些區域提取特徵,最後使用訓練的分類器進行分類。分別如下:
a)區域選擇:利用不同尺寸的滑動視窗框住圖中的某一部分作為候選區域。
b)特徵提取:提取候選區域相關的視覺特徵。比如人臉檢測常用的Harr特徵;行人檢測和普通目標檢測常用的HOG特徵等。由於目標的形態多樣性,光照變化多樣性,背景多樣性等因素使得設計一個魯棒的特徵並不是那麼容易,然而提取特徵的好壞直接影響到分類的準確性。
c)分類器:利用分類器進行識別,比如常用的SVM模型。
傳統的目標檢測中,多尺度形變部件模型DPM(Deformable Part Model)表現比較優秀,連續獲得VOC(Visual Object Class)2007到2009的檢測冠軍,。DPM把物體看成了多個組成的部件(比如人臉的鼻子、嘴巴等),用部件間的關係來描述物體,這個特性非常符合自然界很多物體的非剛體特徵。DPM可以看做是HOG+SVM的擴充套件,很好的繼承了兩者的優點,在人臉檢測、行人檢測等任務上取得了不錯的效果,但是DPM相對複雜,檢測速度也較慢,從而也出現了很多改進的方法。
總結:傳統目標檢測存在的兩個主要問題:一個是基於滑動視窗的區域選擇策略沒有針對性,時間複雜度高,視窗冗餘;二是手工設計的特徵對於多樣性的變化並沒有很好的魯棒性。
基於Region Proposal的深度學習目標檢測演算法
對於滑動視窗存在的問題,region proposal(候選區域)提供了很好的解決方案。region proposal利用了影象中的紋理、邊緣、顏色等資訊預先找出圖中目標可能出現的位置,可以保證在選取較少視窗(幾千個甚至幾百個)的情況下保持較高的召回率。這大大降低了後續操作的時間複雜度,並且獲取的候選視窗要比滑動視窗的質量更高。這裡貼兩張介紹region proposal的PPT:
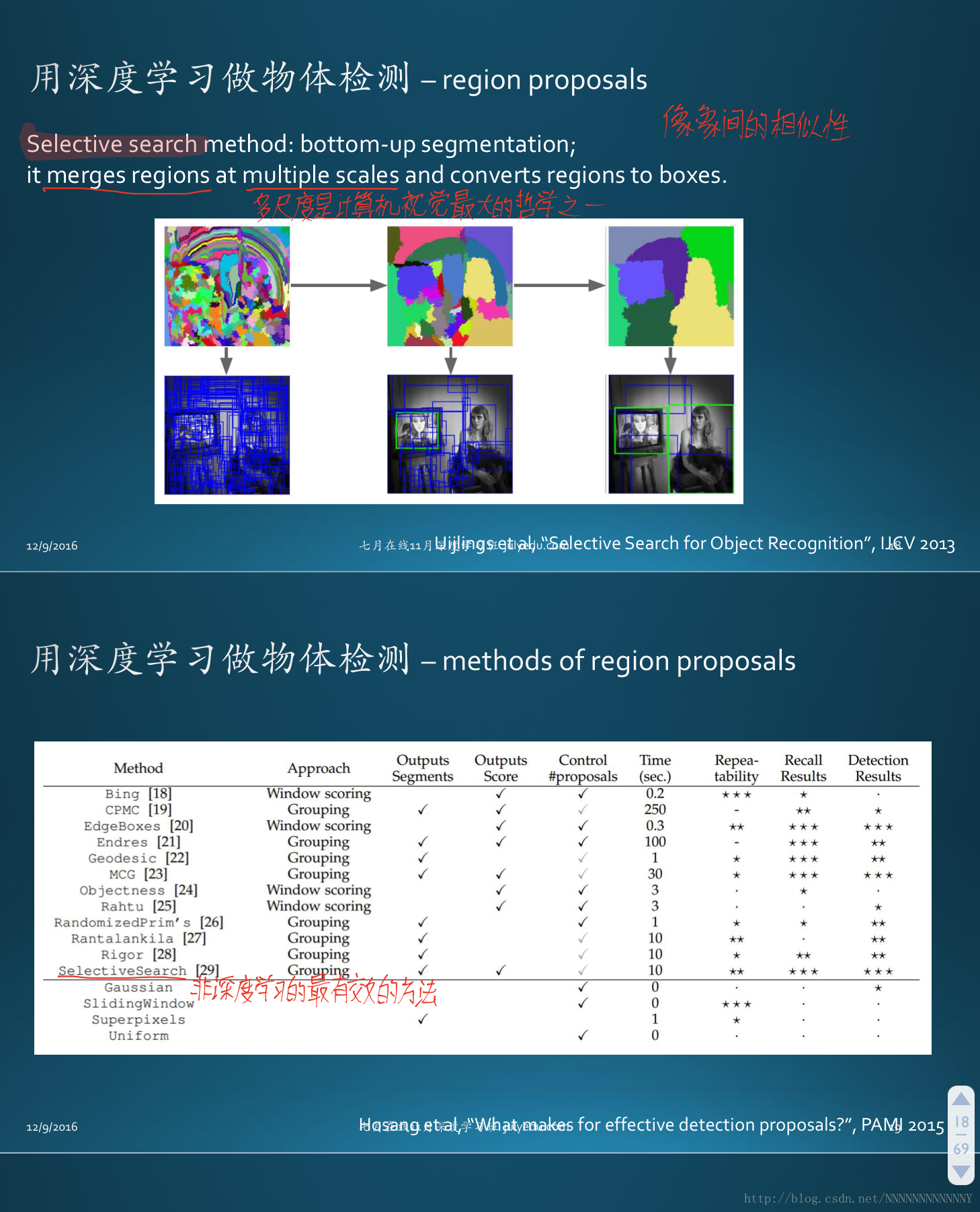
2014年,RBG(Ross B. Girshick)大神使用region proposal+CNN代替傳統目標檢測使用的滑動視窗+手工設計特徵,設計了R-CNN框架,使得目標檢測取得巨大突破,並開啟了基於深度學習目標檢測的熱潮。
R-CNN
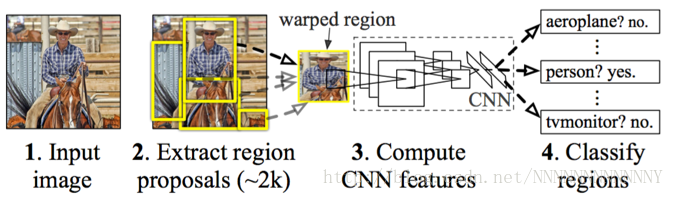
R-CNN的目標檢測流程:
a) 輸入影象,用selective search演算法在影象中提取2000個左右的region proposal(侯選框),並把所有region proposal warp(縮放)成固定大小(原文采用227×227)
b) 將歸一化後的region proposal輸入CNN網路,提取特徵
c) 對於每個region proposal提取到的CNN特徵,再用SVM分類來做識別,用線性迴歸來微調邊框位置與大小,其中每個類別單獨訓練一個邊框迴歸(bounding-box regression)器。
總結:R-CNN框架仍存在如下問題:
a) 重複計算:我們通過region proposal提取2000個左右的候選框,這些候選框都需要進行CNN操作,計算量依然很大,其中有不少其實是重複計算
b) multi-stage pipeline,訓練分為多個階段,步驟繁瑣:region proposal、CNN特徵提取、SVM分類、邊框迴歸,
c) 訓練耗時,佔用磁碟空間大:卷積出來的特徵資料還需要單獨儲存
SPP-net
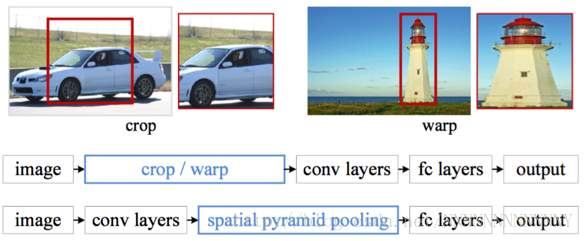
SPP-net的主要思想是去掉了原始影象上的crop/warp等操作,換成了在卷積特徵上的空間金字塔池化層(Spatial Pyramid Pooling,SPP)。
為何要引入SPP層 ?一部分原因是fast R-CNN裡對影象進行不同程度的crop/warp會導致一些問題,比如上圖中的crop會導致物體不全,warp導致物體被拉伸後形變嚴重。但更更更重要的原因是:fast R-CNN裡我們對每一個region proposal都要進行一次CNN提取特徵操作,這樣帶來了很多重複計算。試想假如我們只對整幅影象做一次CNN特徵提取,那麼原圖一個region proposal可以對應到feature map(特徵圖)一個window區域,只需要將這些不同大小window的特徵對映到同樣的維度,將其作為全連線的輸入,就能保證只對影象提取一次卷積層特徵。
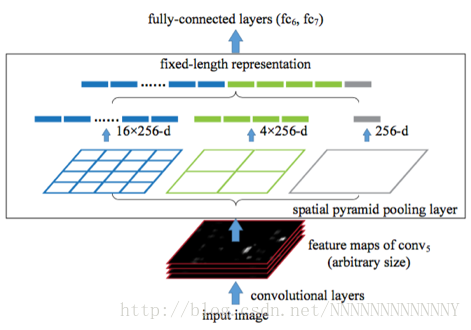
SPP就是為了解決這種問題的。SPP使用空間金字塔取樣(spatial pyramid pooling)將每個window劃分為4*4, 2*2, 1*1的塊,然後每個塊使用max-pooling下采樣,這樣對於每個window經過SPP層之後都得到了一個長度為(4*4+2*2+1)*256維度的特徵向量,將這個作為全連線層的輸入進行後續操作。
總結:使用SPP-NET大大加快了目標檢測的速度,但是依然存在著很多問題:
a) 訓練分為多個階段,依然步驟繁瑣
b) SPP-NET在微調網路時固定了卷積層,只對全連線層進行微調,而對於一個新的任務,有必要對卷積層也進行微調。(分類的模型提取的特徵更注重高層語義,而目標檢測任務除了語義資訊還需要目標的位置資訊)(這一點其實不是很懂啊)
Fast R-CNN
Fast R-CNN在R-CNN的基礎上又做了一些改進:
a) 與SPP類似,它只對整幅影象做一次CNN特徵提取,在後面加了一個類似於SPP的ROI pooling layer,其實就是下采樣。不過因為不是固定尺寸輸入,因此每次的pooling網格大小需要動態調整。比如某個ROI區域座標為
b) 整個的訓練過程是端到端的(除去region proposal提取階段),梯度能夠通過RoI Pooling層直接傳播,直接使用softmax替代SVM分類,同時利用Multi-task Loss(多工損失函式)將邊框迴歸和分類一起進行。這裡著重說一下Multi-task Loss函式:
