
bert之transformer(attention is all you need)
Attention Is All You Need
自從Attention機制在提出之後,加入Attention的Seq2Seq模型在各個任務上都有了提升,所以現在的seq2seq模型指的都是結合rnn和attention的模型。傳統的基於RNN的Seq2Seq模型難以處理長序列的句子,無法實現並行,並且面臨對齊的問題。
所以之後這類模型的發展大多數從三個方面入手:
-
input的方向性:單向 -> 雙向
-
深度:單層 -> 多層
-
型別:RNN -> LSTM GRU
但是依舊收到一些潛在問題的制約,神經網路需要能夠將源語句的所有必要資訊壓縮成固定長度的向量。這可能使得神經網路難以應付長時間的句子,特別是那些比訓練語料庫中的句子更長的句子;每個時間步的輸出需要依賴於前面時間步的輸出,這使得模型沒有辦法並行,效率低;仍然面臨對齊問題。
再然後CNN由計算機視覺也被引入到deep NLP中,CNN不能直接用於處理變長的序列樣本但可以實現平行計算。完全基於CNN的Seq2Seq模型雖然可以並行實現,但非常佔記憶體,很多的trick,大資料量上引數調整並不容易。
本篇文章創新點在於拋棄了之前傳統的encoder-decoder模型必須結合cnn或者rnn的固有模式,只用Attention。文章的主要目的在於減少計算量和提高並行效率的同時不損害最終的實驗結果。
Model
1 整體框架
整體框架很容易理解,但看上圖又很複雜,簡化一下:
其實這就是一個Seq2Seq模型,左邊一個encoder把輸入讀進去,右邊一個decoder得到輸出:
第一眼看到論文中的框圖,隨之產生問題就是左邊encoder的輸出是怎麼和右邊decoder結合的。因為decoder裡面是有N層的。再畫張圖直觀的看就是這樣:
也就是說,Encoder的輸出,會和每一層的Decoder進行結合。我們取其中一層進行詳細的展示:
2 Attention Mechanism
2.1 Attention定義
Attention用於計算"相關程度",例如在翻譯過程中,不同的英文對中文的依賴程度不同,Attention通常可以進行如下描述,表示為將query(Q)和key-value pairs對映到輸出上,其中query、每個key、每個value都是向量,輸出是V中所有values的加權,其中權重是由Query和每個key計算出來的,計算方法分為三步:

在論文中,將Attention落實到具體,分別叫做 Scaled Dot-Product Attention 和 Multi-Head Attention。
2.2 Scaled Dot-Product Attention
它的結構圖如下:
-
First Step
首先從輸入開始理解,Scaled Dot-Product Attention裡的Q, K, V從哪裡來:按照我的理解就是給我一個輸入X, 通過3個線性轉換把X轉換為Q,K,V。
兩個單詞,Thinking, Machines. 通過嵌入變換會X1,X2兩個向量[1 x 4]。分別與Wq,Wk,Wv三個矩陣[4x3]想做點乘得到,{q1,q2},{k1,k2},{v1,v2} 6個向量[1x3]。
-
Second Step
向量{q1,k1}做點乘得到得分(Score) 112, {q1,k2}做點乘得到得分96。
-
Third and Forth Steps
對該得分進行規範,除以8。這個在論文中的解釋是為了使得梯度更穩定。之後對得分[14,12]做softmax得到比例 [0.88,0.12]。
-
Fifth Step
用得分比例[0.88,0.12] 乘以[v1,v2]值(Values)得到一個加權後的值。將這些值加起來得到z1。這就是這一層的輸出。仔細感受一下,用Q,K去計算一個thinking對與thinking, machine的權重,用權重乘以thinking,machine的V得到加權後的thinking,machine的V,最後求和得到針對各單詞的輸出Z。
-
矩陣表示
之前的例子是單個向量的運算例子。這張圖展示的是矩陣運算的例子。輸入是一個[2x4]的矩陣(單詞嵌入),每個運算是[4x3]的矩陣,求得Q,K,V。
Q對K轉製做點乘,除以dk的平方根。做一個softmax得到合為1的比例,對V做點乘得到輸出Z。那麼這個Z就是一個考慮過thinking周圍單詞(machine)的輸出。
注意看這個公式, 其實就會組成一個word2word的attention map!(加了softmax之後就是一個合為1的權重了)。比如說你的輸入是一句話 "i have a dream" 總共4個單詞,這裡就會形成一張4x4的注意力機制的圖:
這樣一來,每一個單詞就對應每一個單詞有一個權重
注意encoder裡面是叫self-attention,decoder裡面是叫masked self-attention。
這裡的masked就是要在做language modelling(或者像翻譯)的時候,不給模型看到未來的資訊。
mask就是沿著對角線把灰色的區域用0覆蓋掉,不給模型看到未來的資訊。
詳細來說,i作為第一個單詞,只能有和i自己的attention。have作為第二個單詞,有和i, have 兩個attention。 a 作為第三個單詞,有和i,have,a 前面三個單詞的attention。到了最後一個單詞dream的時候,才有對整個句子4個單詞的attention。
做完softmax後就像這樣,橫軸合為1
2.3 Multi-Head Attention
Multi-Head Attention就是把Scaled Dot-Product Attention的過程做H次,然後把輸出Z合起來。論文中,它的結構圖如下:
我們還是以上面的形式來解釋:
我們重複記性8次相似的操作,得到8個Zi矩陣
為了使得輸出與輸入結構對標 乘以一個線性W0 得到最終的Z。
3 Transformer Architecture
絕大部分的序列處理模型都採用encoder-decoder結構,其中encoder將輸入序列對映到連續表示(z1,z2,.....,zn) ,然後decoder生成一個輸出序列
,每個時刻輸出一個結果。從框架圖中,我們可以知道Transformer模型延續了這個模型。
3.1 Position Embedding
因為模型不包括Recurrence/Convolution,因此是無法捕捉到序列順序資訊的,例如將K、V按行進行打亂,那麼Attention之後的結果是一樣的。但是序列資訊非常重要,代表著全域性的結構,因此必須將序列的分詞相對或者絕對position資訊利用起來。
這裡每個分詞的position embedding向量維度也是d_model, 然後將原本的input embedding和position embedding加起來組成最終的embedding作為encoder/decoder的輸入。其中position embedding計算公式如下:
其中 pos 表示位置index, i 表示dimension index。
Position Embedding本身是一個絕對位置的資訊,但在語言中,相對位置也很重要,Google選擇前述的位置向量公式的一個重要原因是,由於我們有:
這表明位置p+k的向量可以表示成位置p的向量的線性變換,這提供了表達相對位置資訊的可能性。
在其他NLP論文中,大家也都看過position embedding,通常是一個訓練的向量,但是position embedding只是extra features,有該資訊會更好,但是沒有效能也不會產生極大下降,因為RNN、CNN本身就能夠捕捉到位置資訊,但是在Transformer模型中,Position Embedding是位置資訊的唯一來源,因此是該模型的核心成分,並非是輔助性質的特徵。
3.2 Position-wise Feed-forward Networks
在進行了Attention操作之後,encoder和decoder中的每一層都包含了一個全連線前向網路,對每個position的向量分別進行相同的操作,包括兩個線性變換和一個ReLU啟用輸出:
其中每一層的引數都不同。
3.3 Encoder
Encoder有N=6層,每層包括兩個sub-layers:
-
第一個sub-layer是multi-head self-attention mechanism,用來計算輸入的self-attention
-
第二個sub-layer是簡單的全連線網路。
-
在每個sub-layer我們都模擬了殘差網路,每個sub-layer的輸出都是:
其中Sublayer(x) 表示Sub-layer對輸入 x 做的對映,為了確保連線,所有的sub-layers和embedding layer輸出的維數都相同d_model。
3.4 Decoder
Decoder也是N=6層,每層包括3個sub-layers:
-
第一個是Masked multi-head self-attention,也是計算輸入的self-attention,但是因為是生成過程,因此在時刻 i 的時候,大於 i 的時刻都沒有結果,只有小於 i 的時刻有結果,因此需要做Mask
-
第二個sub-layer是全連線網路,與Encoder相同
-
第三個sub-layer是對encoder的輸入進行attention計算。
同時Decoder中的self-attention層需要進行修改,因為只能獲取到當前時刻之前的輸入,因此只對時刻 t 之前的時刻輸入進行attention計算,這也稱為Mask操作。
3.5 The Final Linear and Softmax Layer
將Decoder的堆疊輸出作為輸入,從底部開始,最終進行word預測。
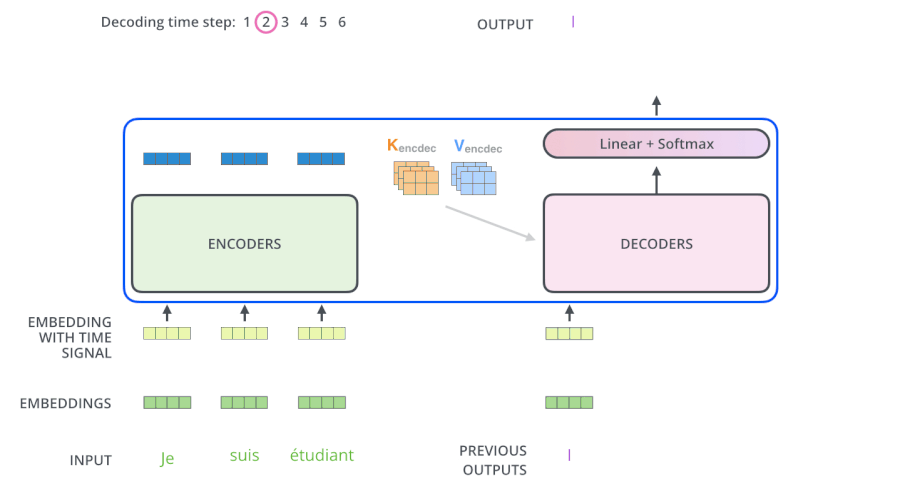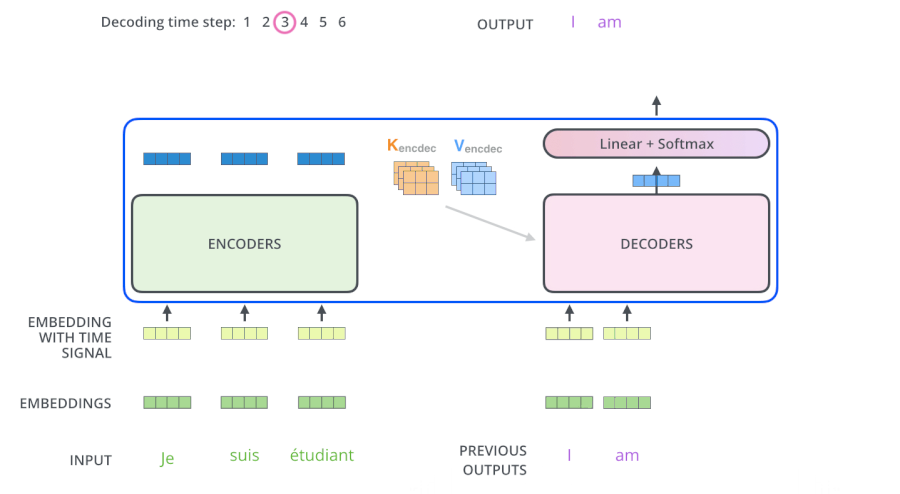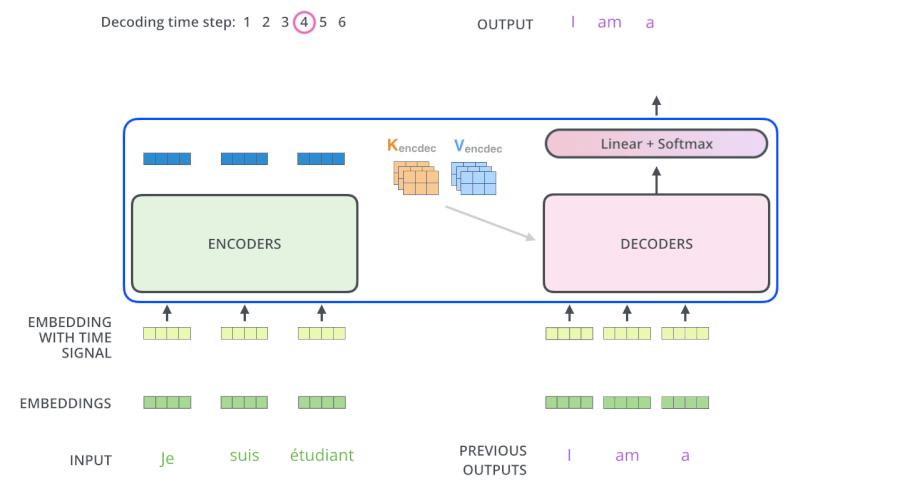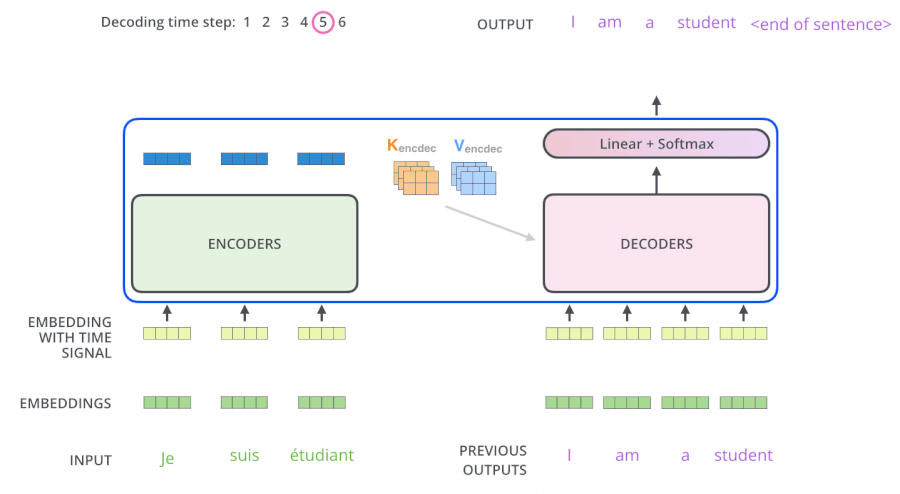
3.6 The Decoder Side
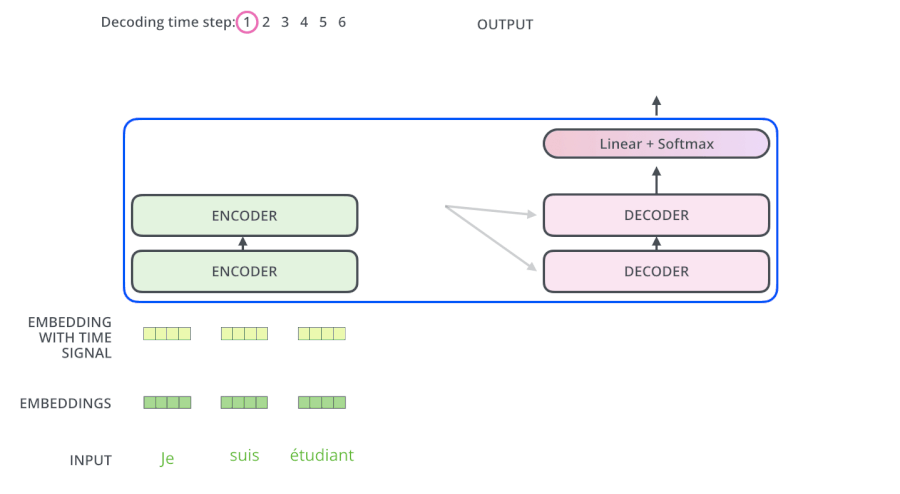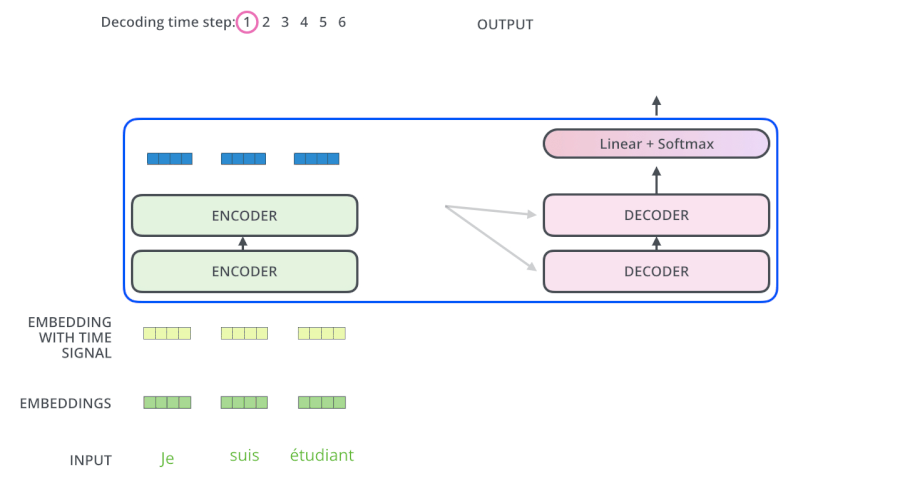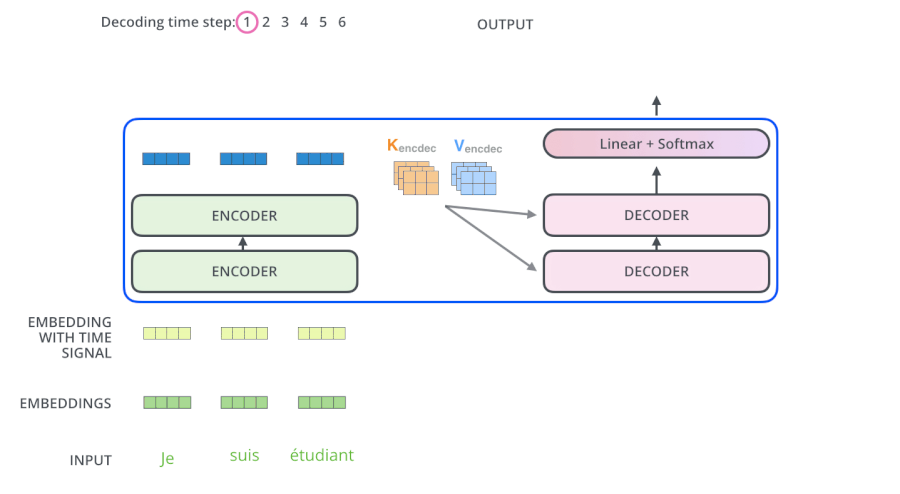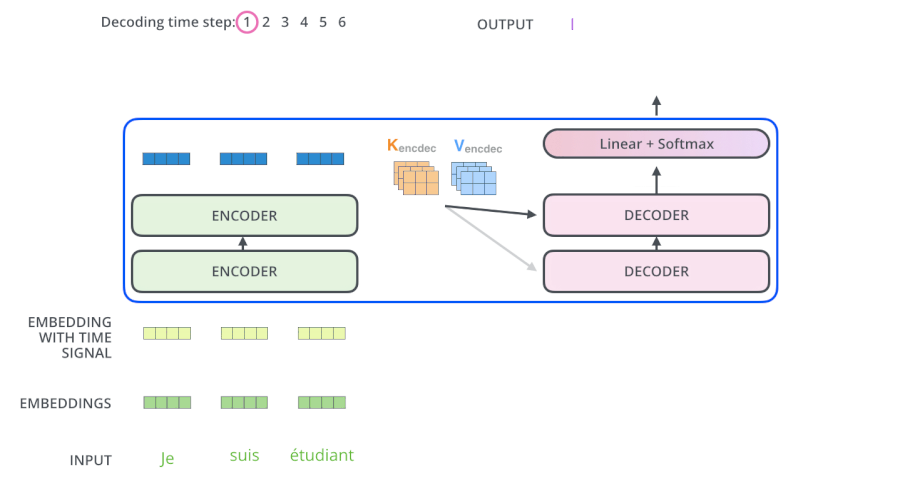
繼續進行:
4 Experiment
可以看出,transformer 用了最少的資源得到了state-of-art的輸出回報。
https://mp.weixin.qq.com/s/7RgCIFxPGnREiBk8PcxOBg
參考文獻
https://jalammar.github.io/illustrated-transformer/
https://kexue.fm/archives/4765
https://zhuanlan.zhihu.com/p/46990010