
Attention is all you need閱讀筆記
xinxinzhang
每個單元的介紹:
一、add&norm
(1).norm(層正則化):
原文:http://blog.csdn.net/zhangjunhit/article/details/53169308
本文主要是針對 batch normalization 存在的問題 提出了 Layer Normalization 進行改進的。
這裡首先來回顧一下 batch normalization :
對於前饋神經網路第 l 隱層,神經元的輸入為 a, 啟用函式為 f, 啟用函式輸出為 h。權值 w 通過 SGD學習得到。 如下面的公式所示:
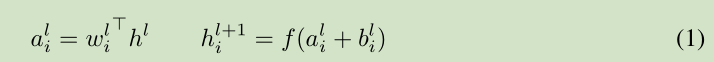
深度學習中的一個挑戰就是對於上面公式中 一層的權值 w 的梯度 高度依賴於前一層神經元的輸出,特別是當這些輸出的改變高度相關的時候。(梯度容易受樣本資料的影響,導致權值難以快速的收斂,一會向東,一會向西,走來走去,走了半天也沒走多少路啊,這樣走到全域性最優值要走到哪天。這個問題有個名字,叫 covariate shift)。 針對此問題 [Ioffe and Szegedy, 2015] 提出了 Batch normalization 來降低這個 covariate shift 的影響。對於每個隱層的神經元,我們在所有的訓練樣本上歸一化該神經元的輸入。
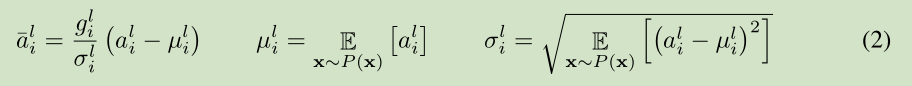
在整個訓練樣本上計算均值方差,然後對神經元的輸入進行歸一化。由於對整個訓練樣本計算均值方差不太有效率(對於訓練來說),所以提出了 在最小訓練批次上估計 均值方差。 current mini-batch 。 這個約束導致Batch normalization 難以應用於 recurrent neural networks。
3 Layer normalization
針對前面提到的 Batch normalization 的問題,我們提出了 Layer normalization。
注意到一層輸出的改變會產生下一層輸入的高相關性改變,特別是當使用 ReLU,其輸出改變很大。那麼我們可以通過固定一層神經元的輸入均值和方差來降低 covariate shift 的影響。
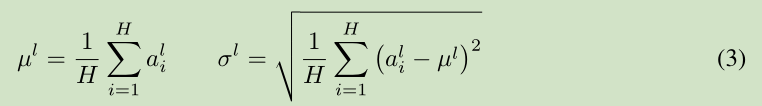
上面公式中 H 是 一層神經元的個數。這裡一層網路 共享一個均值和方差,不同訓練樣本對應不同的均值和方差,這是和 Batch normalization 的最大區別。
Layer normalization 對於recurrent neural networks 的幫助最大。
Layer normalization 對於 Convolutional Networks 作用不是很大,後續研究可以提高其作用。
訓練速度快。LayerNorm是Batch Normalization的一個變體,簡要對比下BN與LN:LN是本次輸入模型的一組樣本做進行Normalization,BN是對一個batch
(2):殘差連線;
原文:http://www.jianshu.com/p/e58437f39f65
網路的深度為什麼重要?
因為CNN能夠提取low/mid/high-level的特徵,網路的層數越多,意味著能夠提取到不同level的特徵越豐富。並且,越深的網路提取的特徵越抽象,越具有語義資訊。
為什麼不能簡單地增加網路層數?
- 對於原來的網路,如果簡單地增加深度,會導致梯度彌散或梯度爆炸。
對於該問題的解決方法是正則化初始化和中間的正則化層(Batch Normalization),這樣的話可以訓練幾十層的網路。
- 雖然通過上述方法能夠訓練了,但是又會出現另一個問題,就是退化問題,網路層數增加,但是在訓練集上的準確率卻飽和甚至下降了。這個不能解釋為overfitting,因為overfit應該表現為在訓練集上表現更好才對。 退化問題說明了深度網路不能很簡單地被很好地優化。 作者通過實驗:通過淺層網路+ y=x 等同對映構造深層模型,結果深層模型並沒有比淺層網路有等同或更低的錯誤率,推斷退化問題可能是因為深層的網路並不是那麼好訓練,也就是求解器很難去利用多層網路擬合同等函式。
怎麼解決退化問題?
深度殘差網路。如果深層網路的後面那些層是恆等對映,那麼模型就退化為一個淺層網路。那現在要解決的就是學習恆等對映函數了。 但是直接讓一些層去擬合一個潛在的恆等對映函式H(x) = x,比較困難,這可能就是深層網路難以訓練的原因。但是,如果把網路設計為H(x) = F(x) + x,如下圖。我們可以轉換為學習一個殘差函式F(x) = H(x) - x. 只要F(x)=0,就構成了一個恆等對映H(x) = x. 而且,擬合殘差肯定更加容易。

其他的參考解釋
作者:AlanMa 連結:http://www.jianshu.com/p/e58437f39f65 來源:簡書 著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。
- F是求和前網路對映,H是從輸入到求和後的網路對映。比如把5對映到5.1,那麼引入殘差前是F'(5)=5.1,引入殘差後是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。這裡的F'和F都表示網路引數對映,引入殘差後的對映對輸出的變化更敏感。比如s輸出從5.1變到5.2,對映F'的輸出增加了1/51=2%,而對於殘差結構輸出從5.1到5.2,對映F是從0.1到0.2,增加了100%。明顯後者輸出變化對權重的調整作用更大,所以效果更好。殘差的思想都是去掉相同的主體部分,從而突出微小的變化,看到殘差網路我第一反應就是差分放大器...地址
- 至於為何shortcut的輸入時X,而不是X/2或是其他形式。kaiming大神的另一篇文章[2]中探討了這個問題,對以下6種結構的殘差結構進行實驗比較,shortcut是X/2的就是第二種,結果發現還是第一種效果好啊(攤手)。
引入了殘差,儘可能保留原始輸入x的資訊。
(3)結構中逐項的feed-forward網路作用
Attention的sublayer之間嵌入一個FFN層,兩個線性變換組成:FFN(x)=max(0,x*W1 + b1)W2 + b2。同層擁有相同的引數,不同層之間擁有不同的引數。目的應該是提高模型特徵抽取的能力,考慮到效率,選擇兩個線性變換。
(4)Position Encoding(位置編碼)
網模型的輸入embedding中新增position embedding,使網路可以獲得輸入序列的位置(positions)之間的一個相對或者絕對位置資訊。Position embedding有很多種方式獲得,比如採用像word2vec方式訓練。本文采用較簡單的方式,基於正弦和餘弦函式,根據位置pos和維度i來計算:
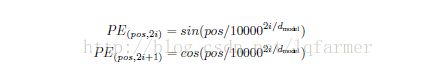
這樣做的目的是因為正弦和餘弦函式具有周期性,對於固定長度偏差k(類似於週期),post +k位置的PE可以表示成關於pos位置PE的一個線性變化(存線上性關係),這樣可以方便模型學習詞與詞之間的一個相對位置關係。
(5).核心:多頭注意力機制:
原文:https://zhuanlan.zhihu.com/p/27469958?refer=xitucheng10
http://blog.csdn.net/mijiaoxiaosan/article/details/73251443
在這篇文章當中有一個對Attention很好的描述,即attention機制實際上來講是一個由諸多Query和Key-value pair組成的對映函式,即
<img src="https://pic3.zhimg.com/v2-dbadd19b49b92c5770330d9ab3a77342_b.png" data-rawwidth="514" data-rawheight="102" class="origin_image zh-lightbox-thumb" width="514" data-original="https://pic3.zhimg.com/v2-dbadd19b49b92c5770330d9ab3a77342_r.png">
上式被作者們稱為Scaled Dot-Product Attention. 在這裡面\sqrt{d_k} 是用來約束點積大小的。因為作者認為當query和key的維度很大時,點選傾向於變得比較大,因而上述因子做約束,但是這個因子是如何確定的文中並沒有做具體的交待。
本文中的self-attention的整體結構是以上圖中的multi-head attention實現的。所謂的multi-head(多抽頭?)在文中實際上就是對query和key進行多次線性對映,然後講結果串聯起來,從這一點上來看有一種濃濃的CNN既視感。
<img src="https://pic1.zhimg.com/v2-56b798bfca2b62e18e8985c57d706f8c_b.png" data-rawwidth="892" data-rawheight="478" class="origin_image zh-lightbox-thumb" width="892" data-original="https://pic1.zhimg.com/v2-56b798bfca2b62e18e8985c57d706f8c_r.png">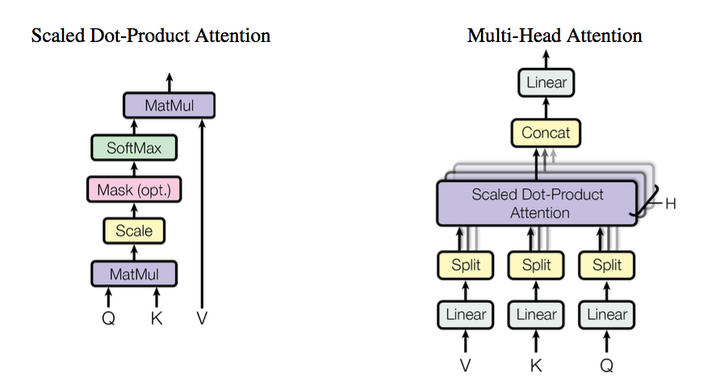
具體來講,在encoder-decoder中,query來自之前上一層decoder,而key和value則是上一層encoder的輸出。這種機制使得句子中的每一個Part都可以參與encoder-decoder的過程。而在self attention中,query,key和value都來自相同的上一步的輸出。
多頭的attention (Multi-Head Attention)
這個應該是本文最核心的部分。本文結構中的Attention並不是簡簡單單將一個點乘的attention應用進去。作者發現先對queries,keys以及values進行h
次不同的線性對映效果特別好。學習到的線性對映分別對映到dk
, dk
以及dv
維。分別對每一個對映之後的得到的queries,keys以及values進行attention函式的並行操作,生成dv
維的output值。具體操作細節如以下公式。
where:headi=Attention(QWiQ,KWiK,VWiV)
這裡對映的引數矩陣,WiQ∈Rdmodel∗dk ,WiK∈Rdmodel∗dk ,WiV∈Rdmodel∗dv。
本文中對並行的attention層(或者成為頭)使用了h=8 的設定。其中每層都設定為dk=dv=dmodel/h=64. 由於每個頭都減少了維度,所以總的計算代價和在所有維度下單頭的attention是差不多的。
把這些attention頭的output拼接起來作為最終值,就像下圖中multihead attention結構示意圖所描述的一樣。
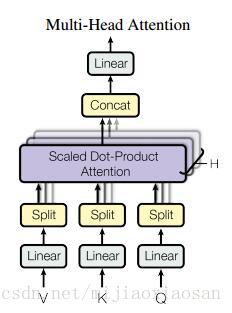
在本模型中如何使用attention
本文提出的模型Transformer以三種不同的方式使用了多頭attention。
1. 在encoder-decoder的attention層,queries來自於之前的decoder層,而keys和values都來自於encoder的輸出。這個類似於很多已經提出的seq-to-seq模型所使用的attention機制。
2. 在encoder含有self-attention層。在一個self-attention層中,所有的keys, values以及queries都來自於同一個地方,本例中即encoder之前一層的的輸出。
3. 類似的,decoder中的self-attention層也是一樣。不同的是在scaled點乘attention操作中加了一個mask的操作(設定為負無窮),這個操作是保證softmax操作之後不會將非法的values連到attention中(個人理解,比如你這一位置queryattention的values不能有這一位置之後的values的資訊,只能有該位置前面的values,本人菜鳥歡迎拍磚)。
之前說模型由堆疊在一起的六個層組成,每層由兩個支層,attention層就是其中一個,而attention之後的另一個支層就是一個前饋的網路。公式描述如下。
FFN(x)=max(0,xW1+b1)W2+b2該網路是兩個線性變換,中間加了一個ReLU啟用函式。每個位置(position)上的線性變換是一樣的,但是不同層與層的引數是不一樣的。該網路的輸入和輸出維度都是dmodel ,不過中間層的維度是2048.
模型的整體框架基本介紹完了,其最重要的創新應該就是Self-Attention的使用級聯的多頭attention架構。
作者在文中深入討論了為什麼選擇使用self attention這一結構。主要從三個方面來談。第一是每層的總計算複雜性,其次是能平行計算的數量,這點論文用所要求的序列操作的最小值來量化。第三點是針對網路長距離依賴的路徑長度。為了提升在長序列上的計算效能,self-attention應該改被限制(restrict)在一個size大小為r 的鄰域內,這樣可以將最大路徑長度增加到O(n/r) ,至於具體如何去做作者說在未來工作中會研究。
二:模型整體解析:
模型架構
大多數效能較好的神經序列轉導模型都使用了編碼器-解碼器的結構。Transformer 也借鑑了這一點,並且在編碼器-解碼器上使用了全連線層。
1.編碼器:由 6 個完全相同的層堆疊而成,每個層有 2 個子層。在每個子層後面會跟一個殘差連線和層正則化(layer normalization)。第一部分由一個多頭(multi-head)自注意力機制,第二部分則是一個位置敏感的全連線前饋網路。
2.解碼器:解碼器也由 6 個完全相同的層堆疊而成,不同的是這裡每層有 3 個子層,第 3 個子層負責處理編碼器輸出的多頭注意力機制。解碼器的子層後面也跟了殘差連線和層正則化。解碼器的自注意力子層也做了相應修改。
3.模型輸入。
編碼器和解碼器的輸入就是利用學習好的embeddings將tokens(一般應該是詞或者字元)轉化為dmodel
維向量。對解碼器來說,利用線性變換以及softmax函式將解碼的輸出轉化為一個預測下一個token的概率。
4.
Encoder端:輸入的Embedding,與Positional Embedding(後面會給出positional embedding的計算方法)相加,做為堆疊N(N=6)個完全相同的Layer層的輸入。每一個Layer層由Multi-Head attention部分和一個FeedFoward部分組成,兩個部分直接通過一個Add & Norm的方式連線。為了加速,模型中所有子層的輸出dimension = 512。
Decoder端:decoder也是由N(N=6)個完全相同的Layer組成,decoder中的Layer由encoder的Layer中插入一個Multi-Head Attention + Add&Norm組成。輸出的embedding與輸出的position embedding求和做為decoder的輸入,經過一個Multi-Head Attention + Add&Norm((MA-1)層,MA-1層的輸出做為下一Multi-Head Attention + Add&Norm(MA-2)的query(Q)輸入,MA-2層的Key和Value輸入(從圖中看,應該是encoder中第i(i = 1,2,3,4,5,6)層的輸出對於decoder中第i(i = 1,2,3,4,5,6)層的輸入)。MA-2層的輸出輸入到一個前饋層(FF),經過AN操作後,經過一個線性+softmax變換得到最後目標輸出的概率。
三.Attention機制作用分析
1)、插入decoder的中間層的MAAN結構輸入:query來源於output的decoder層輸出,memory的keys和values來源於對於的encoder的輸出,充當權重。這一操作使得decoder可以獲取輸入X整個序列的資訊,類似於傳統Seq2Seq中的decoder端的attention機制。
2)、encoder端包含self-attention layers。當前self-attention的輸入k、v,q來源於前一層的輸出,encoder中每一個position可以關聯前一層所有positions,可以全面獲取輸入序列X中positions之間依賴關係。對包含self-attention的decoder端也一樣。
3)、相比基於CNN和RNN的Seq2Seq模型,基於Self-Attention的Seq2Seq模型計算效率更高,單層計算複雜度更低,學習long-range dependencies的能力更強,三種類型的Seq2Seq模型對比如下表所示:

最重要的是,基於Self-Attention的Seq2Seq網路學習long-range dependencies能力很強。Seq2Seq中的一個關鍵問題是如何學習sequence中的詞與詞之間的long-range dependencies關係。在雙向LSTM(BLSTM),我們通常分正向和反向分別計算一次Sequence的資訊,其中,學習long-range dependencies關鍵的一點是訊號在網路正向和反向計算中傳遞的Path長度(計算次數),計算次數越多,較遠的依賴關係消失情況越嚴重。在Self-Attention結構中,每一層都直接與前一層的所有position直接連線,因此Path的長度為O(1),最大程度保留了sequence中詞與詞之間的依賴關係。針對長句子,為了提高計算效率,只考慮某一個詞前後r個詞時,Path的路徑最長長度任然只有O(n/r),其中,n為sequence長度。
參考:http://blog.csdn.net/lqfarmer/article/details/73521811
相關推薦
Attention is all you need閱讀筆記
xinxinzhang 每個單元的介紹: 一、add&norm (1).norm(層正則化): 原文:http://blog.csdn.net/zhangjunhit/article/details/53169308 本文主要是針對 batch normaliza
[閱讀筆記]Attention Is All You Need - Transformer結構
例如 position 頻率 product 結構圖 上一個 預測 獲得 line Transformer 本文介紹了Transformer結構, 是一種encoder-decoder, 用來處理序列問題, 常用在NLP相關問題中. 與傳統的專門處理序列問題的encoder
#論文閱讀#attention is all you need
ali 計算 str red read required ado 論文 uci Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in Neural Infor
論文閱讀-attention-is-all-you-need
都是 所有 for 表示 權重 all osi max forward 1結構介紹 是一個seq2seq的任務模型,將輸入的時間序列轉化為輸出的時間序列。 有encoder和decoder兩個模塊,分別用於編碼和解碼,結合時是將編碼的最後一個輸出 當做 解碼的第一個模塊的輸
Paper Reading - Attention Is All You Need ( NIPS 2017 )
int tput represent enc perf task desc compute .com Link of the Paper: https://arxiv.org/abs/1706.03762 Motivation: The inherently sequen
Attention is all you need及其在TTS中的應用Close to Human Quality TTS with Transformer和BERT
ips fas 缺點 不同的 stand 進入 簡單 code shang 論文地址:Attention is you need 序列編碼 深度學習做NLP的方法,基本都是先將句子分詞,然後每個詞轉化為對應的的詞向量序列,每個句子都對應的是一個矩陣\(X=(x_1,x_2,
Attention Is All You Need(Transformer)原理小結
1. 前言 谷歌在2017年發表了一篇論文名字教Attention Is All You Need,提出了一個只基於attention的結構來處理序列模型相關的問題,比如機器翻譯。傳統的神經機器翻譯大都是利用RNN或者CNN來作為encoder-decoder的模型基礎,而谷歌最新的只基於Attention
Attention is all you need 論文詳解(轉)
一、背景 自從Attention機制在提出之後,加入Attention的Seq2Seq模型在各個任務上都有了提升,所以現在的seq2seq模型指的都是結合rnn和attention的模型。傳統的基於RNN的Seq2Seq模型難以處理長序列的句子,無法實現並行,並且面臨對齊的問題。 所以之後這類模型的發展大
pytorch求索(4): 跟著論文《 Attention is All You Need》一步一步實現Attention和Transformer
寫在前面 此篇文章是前橋大學大神復現的Attention,本人邊學邊翻譯,借花獻佛。跟著論文一步一步復現Attention和Transformer,敲完以後收貨非常大,加深了理解。如有問題,請留言指出。 import numpy as np import torch import
《Attention Is All You Need》
本文是對Google2017年發表於NIPS上的論文"Attention is all you need"的閱讀筆記. 對於深度學習中NLP問題,通常是將句子分詞後,轉化詞向量序列,轉為seq2seq問題. RNN方案 採用RNN模型,通常是遞迴地進行
Attention is All You Need -- 淺析
由於最近bert比較火熱,並且bert的底層網路依舊使用的是transformer,因此再學習bert之前,有必要認真理解一下Transformer的基本原理以及self-attention的過程,本文參考Jay Alammar的一篇博文,翻譯+
Transformer【Attention is all you need】
nsf 打開 enc 一個 png 分別是 att 參考 for 前言 Transfomer是一種encoder-decoder模型,在機器翻譯領域主要就是通過encoder-decoder即seq2seq,將源語言(x1, x2 ... xn) 通過編碼,再解碼的方式映射
bert之transformer(attention is all you need)
Attention Is All You Need 自從Attention機制在提出之後,加入Attention的Seq2Seq模型在各個任務上都有了提升,所以現在的seq2seq模型指的都是結合rnn和attention的模型。傳統的基於RNN的Seq2Seq模型難以處理長序列的句子,無法實現
[NIPS2017]Attention is all you need
這篇文章是火遍全宇宙,關於網上的解讀也非常多,將自己看完後的一點小想法也總結一下。 看完一遍之後,有很多疑問,我是針對每個疑問都瞭解清楚後才算明白了這篇文章,可能寫的不到位,只是總結下,下次忘記了便於翻查。 一:Q,K, V 到底是什麼? 在傳統的seq2seq
一文讀懂「Attention is All You Need」| 附程式碼實現
前言 2017 年中,有兩篇類似同時也是筆者非常欣賞的論文,分別是 FaceBook 的Convolutional Sequence to Sequence Learning和 Google 的Attention is All You Need,它們都算是 Seq2Se
釋出一年了,做NLP的還有沒看過這篇論文的嗎?--“Attention is all you need”
筆記作者:王小草 日期:2018年10月30日 歡迎關注我的微信公眾號“AI躁動街” 1 Background 說起深度學習和神經網路,影象處理一呼百應的“卷積神經網路CNN“也好,還是自然語言處理得心應手的”迴圈神經網路RNN”,都簡直是膾炙人口、婦孺皆知
谷歌機器翻譯Attention is All You Need
通常來說,主流序列傳導模型大多基於 RNN 或 CNN。Google 此次推出的翻譯框架—Transformer 則完全捨棄了 RNN/CNN 結構,從自然語言本身的特性出發,實現了完全基於注意力機制的 Transformer 機器翻譯網路架構。 論文連結:
Day3_attention is all you need 論文閱讀
感覺自己看的一臉懵b; 但看懂了這篇文章要講啥: 以RRN為背景的神經機器翻譯是seq2seq,但這樣帶來的問題是不可以平行計算,拖長時間,除此之外會使得尋找距離遠的單詞之間的依賴關係變得困難。而本文講的Attention機制就很好的解決了這個問題,並且也解決了遠距離之間的依賴關係問題。 前饋神
All you need is attention(Tranformer) --學習筆記
1、回顧 傳統的序列到序列的機器翻譯大都利用RNN或CNN來作為encoder-decoder的模型基礎。實際上傳統機器翻譯基於RNN和CNN進行構建模型時,最關鍵一步就是如何編碼這些句子的序列。往往第一步是先將句子進行分詞,然後每個詞轉化為對應的詞向量,那麼每
Attention all you need
2018年11月05日 14:30:02 聶小閒 閱讀數:4 個人分類: 演算法