
吳恩達Coursera深度學習課程 deeplearning.ai (5-2) 自然語言處理與詞嵌入--程式設計作業(二):Emojify表情包
Part 2: Emojify
歡迎來到本週的第二個作業,你將利用詞向量構建一個表情包。
你有沒有想過讓你的簡訊更具表現力? emojifier APP將幫助你做到這一點。 所以不是寫下”Congratulations on the promotion! Lets get coffee and talk. Love you!” emojifier可以自動轉換為 “Congratulations on the promotion! ? Lets get coffee and talk. ☕️ Love you! ❤️”
另外,如果你對emojis不感興趣,但有朋友向你傳送了使用太多表情符號的瘋狂簡訊,你還可以使用emojifier來回復他們。
你將實現一個模型,輸入一個句子(“Let’s go see the baseball game tonight!”),並找到最適合這個句子的表情符號(⚾️)。 在許多表情符號介面中,您需要記住❤️是”heart”符號而不是”love”符號。 但是使用單詞向量,你會發現即使你的訓練集只將幾個單詞明確地與特定的表情符號相關聯,你的演算法也能夠將測試集中相關的單詞概括並關聯到相同的表情符號上,即使這些詞沒有出現在訓練集中。這使得即使使用小型訓練集,你也可以建立從句子到表情符號的精確分類器對映。
在本練習中,您將從使用詞嵌入的基本模型(Emojifier-V1)開始,然後構建進一步整合LSTM的更復雜的模型(Emojifier-V2)。
導包
import numpy as np
from emo_utils import *
import emoji
import matplotlib.pyplot as plt
%matplotlib inlineemo_utils 中有用的函式
import csv
import numpy as np
import emoji
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
def read_glove_vecs(glove_file) 1 基本模型:Emojifier-V1
1.1 emoji 資料集
我們先來建立一個簡單的分類器。
我們有一個小型資料集(X, Y):
- X 包含127個句子
- Y 包含標號為0-4的對應於每個句子的表情
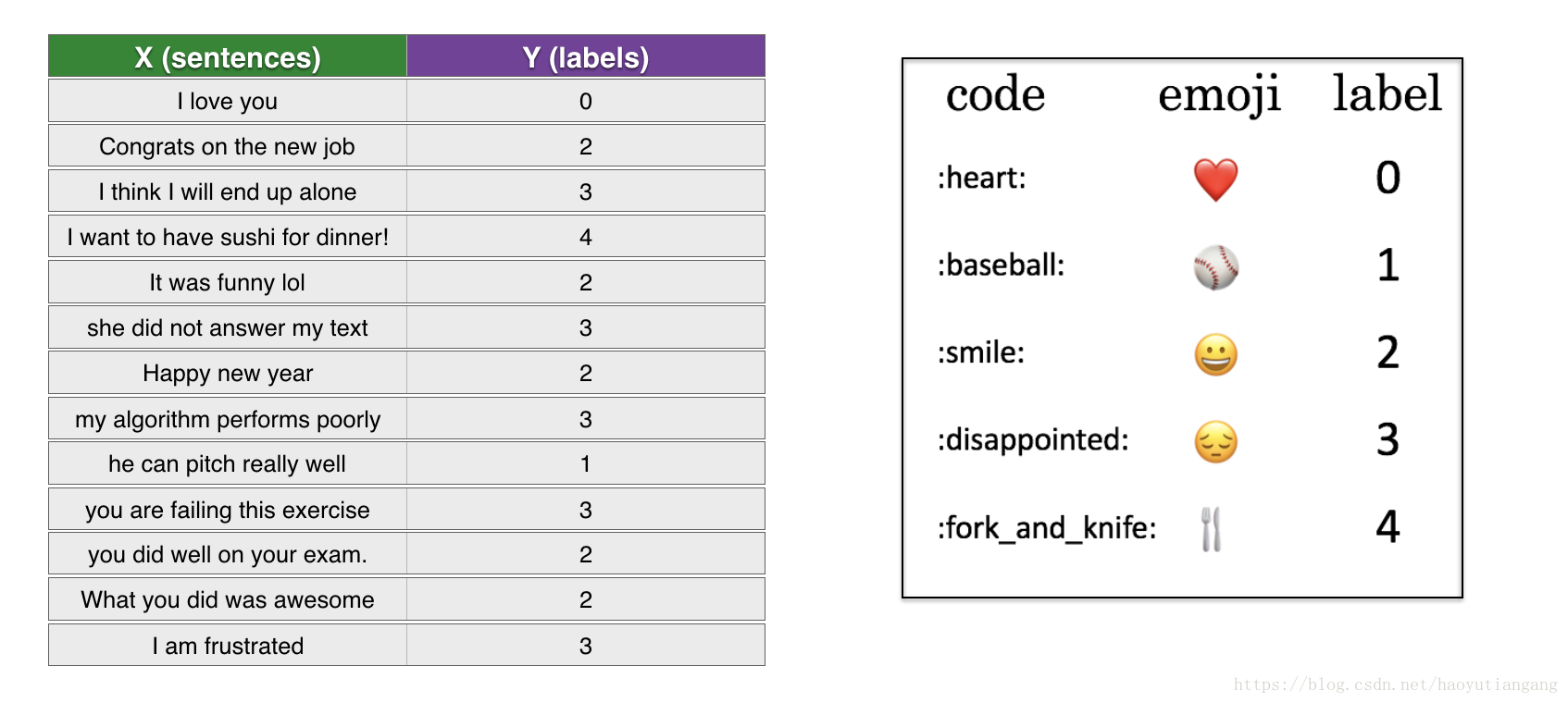
下面匯入資料集,訓練集127個例子,測試集56個例子
X_train, Y_train = read_csv('data/train_emoji.csv')
X_test, Y_test = read_csv('data/tesss.csv')
maxLen = len(max(X_train, key=len).split())檢視訓練集資料
index = 1
print(X_train[index], label_to_emoji(Y_train[index]))1.2 Emojifier-V1 概述
在這一部分,我們要實現一個名為”Emojifier-v1” 的模型
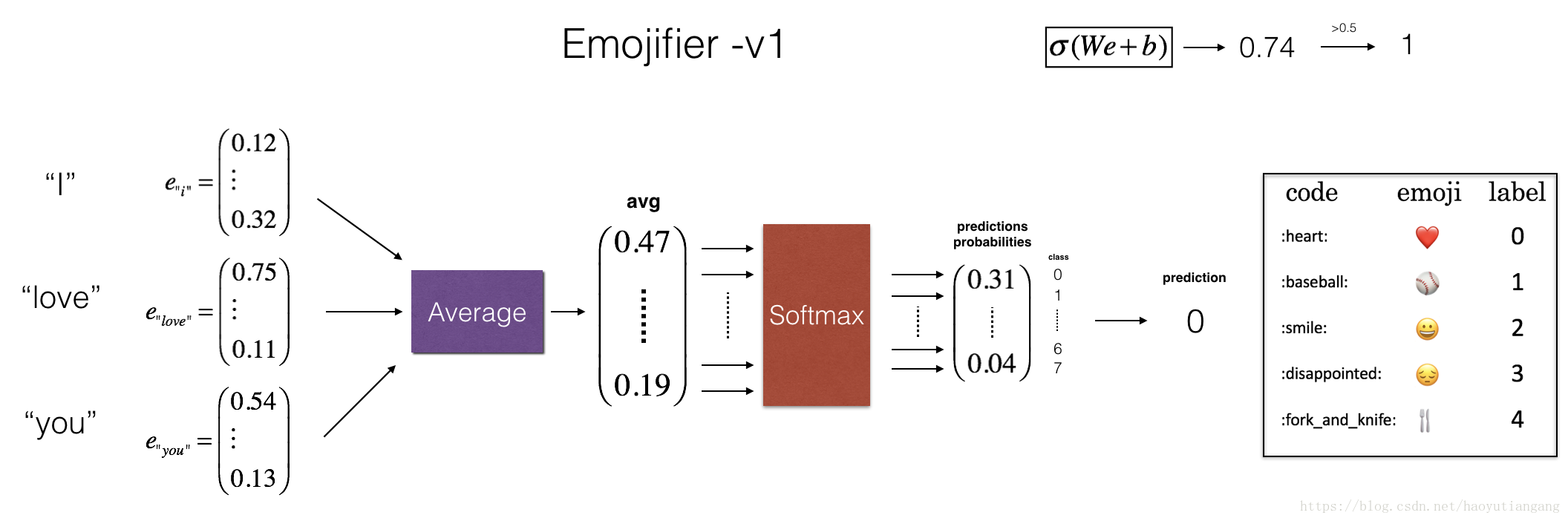
模型的輸入是一個句子,輸出是(1,5)的概率向量,然後通過argmax層得出最適合的預測表情。
為了將我們的標籤轉換為適合訓練softmax分類器的格式,我們將Y從(m,1)轉換為”one-hot” 的(m,5)。如下轉換中 Y_oh 表示”Y-one-hot”。
Y_oh_train = convert_to_one_hot(Y_train, C = 5)
Y_oh_test = convert_to_one_hot(Y_test, C = 5)
index = 50
print(Y_train[index], "is converted into one hot", Y_oh_train[index])
# 0 is converted into one hot [ 1. 0. 0. 0. 0.]資料準備就緒,下面可以實現模型了。
1.3 實現 Emojifier-V1
首先需要將輸入的句子轉換為詞向量再求平均值,我們仍然使用50維的 Glove 詞嵌入。
匯入word_to_vec_map,其中包含了所有的向量表示。
word_to_index, index_to_word, word_to_vec_map = read_glove_vecs('data/glove.6B.50d.txt')匯入的內容有
- word_to_index:詞典中單詞到索引的對映(400,001個單詞,索引從0到400,000)
- index_to_word:詞典中索引到單詞的對映
- word_to_vec_map:詞典中單詞到 Glove 向量的對映
看看資料
word = "cucumber"
index = 289846
print("the index of", word, "in the vocabulary is", word_to_index[word])
print("the", str(index) + "th word in the vocabulary is", index_to_word[index])
# the index of cucumber in the vocabulary is 113317
# the 289846th word in the vocabulary is potatos練習:實現 sentence_to_avg()
- 將每個句子轉換為小寫,然後拆分句子為單詞列表(可以使用X.lower() 和 X.split())
- 取出句子中每個單詞的 Glove 向量,然後求平均值
# GRADED FUNCTION: sentence_to_avg
def sentence_to_avg(sentence, word_to_vec_map):
"""
Converts a sentence (string) into a list of words (strings). Extracts the GloVe representation of each word
and averages its value into a single vector encoding the meaning of the sentence.
Arguments:
sentence -- string, one training example from X
word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation
Returns:
avg -- average vector encoding information about the sentence, numpy-array of shape (50,)
"""
### START CODE HERE ###
# Step 1: Split sentence into list of lower case words (鈮?1 line)
words = sentence.lower().split()
# Initialize the average word vector, should have the same shape as your word vectors.
avg = np.zeros((50,))
# Step 2: average the word vectors. You can loop over the words in the list "words".
for w in words:
avg += word_to_vec_map[w]
avg = avg/len(words)
### END CODE HERE ###
return avg
avg = sentence_to_avg("Morrocan couscous is my favorite dish", word_to_vec_map)
print("avg = ", avg)
# avg = [-0.008005 0.56370833 -0.50427333 0.258865 0.55131103 0.03104983
# -0.21013718 0.16893933 -0.09590267 0.141784 -0.15708967 0.18525867
# 0.6495785 0.38371117 0.21102167 0.11301667 0.02613967 0.26037767
# 0.05820667 -0.01578167 -0.12078833 -0.02471267 0.4128455 0.5152061
# 0.38756167 -0.898661 -0.535145 0.33501167 0.68806933 -0.2156265
# 1.797155 0.10476933 -0.36775333 0.750785 0.10282583 0.348925
# -0.27262833 0.66768 -0.10706167 -0.283635 0.59580117 0.28747333
# -0.3366635 0.23393817 0.34349183 0.178405 0.1166155 -0.076433
# 0.1445417 0.09808667]期待的輸出
| key | value |
|---|---|
| avg | [-0.008005 0.56370833 -0.50427333 0.258865 0.55131103 0.03104983 -0.21013718 0.16893933 -0.09590267 0.141784 -0.15708967 0.18525867 0.6495785 0.38371117 0.21102167 0.11301667 0.02613967 0.26037767 0.05820667 -0.01578167 -0.12078833 -0.02471267 0.4128455 0.5152061 0.38756167 -0.898661 -0.535145 0.33501167 0.68806933 -0.2156265 1.797155 0.10476933 -0.36775333 0.750785 0.10282583 0.348925 -0.27262833 0.66768 -0.10706167 -0.283635 0.59580117 0.28747333 -0.3366635 0.23393817 0.34349183 0.178405 0.1166155 -0.076433 0.1445417 0.09808667] |
模型
你已經實現了 model 的各個部分。在sentence_to_avg()之後需要將平均值進行前向傳播、計算損失、後向傳播以及更新引數。
練習:實現 model()
假設這裡的 Yoh(“Y one hot”)為輸出標籤的”one-hot”表示,下面公式用於前向傳播和計算交叉熵。
程式碼
# GRADED FUNCTION: model
def model(X, Y, word_to_vec_map, learning_rate = 0.01, num_iterations = 400):
"""
Model to train word vector representations in numpy.
Arguments:
X -- input data, numpy array of sentences as strings, of shape (m, 1)
Y -- labels, numpy array of integers between 0 and 7, numpy-array of shape (m, 1)
word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation
learning_rate -- learning_rate for the stochastic gradient descent algorithm
num_iterations -- number of iterations
Returns:
pred -- vector of predictions, numpy-array of shape (m, 1)
W -- weight matrix of the softmax layer, of shape (n_y, n_h)
b -- bias of the softmax layer, of shape (n_y,)
"""
np.random.seed(1)
# Define number of training examples
m = Y.shape[0] # number of training examples
n_y = 5 # number of classes
n_h = 50 # dimensions of the GloVe vectors
# Initialize parameters using Xavier initialization
W = np.random.randn(n_y, n_h) / np.sqrt(n_h)
b = np.zeros((n_y,))
# Convert Y to Y_onehot with n_y classes
Y_oh = convert_to_one_hot(Y, C = n_y)
# Optimization loop
for t in range(num_iterations): # Loop over the number of iterations
for i in range(m): # Loop over the training examples
### START CODE HERE ### (鈮?4 lines of code)
# Average the word vectors of the words from the j'th training example
avg = sentence_to_avg(X[i], word_to_vec_map)
# Forward propagate the avg through the softmax layer
z = np.dot(W, avg) + b
a = softmax(z)
# Compute cost using the j'th training label's one hot representation and "A" (the output of the softmax)
cost = -np.sum(Y_oh[i] * np.log(a))
### END CODE HERE ###
# Compute gradients
dz = a - Y_oh[i]
dW = np.dot(dz.reshape(n_y,1), avg.reshape(1, n_h))
db = dz
# Update parameters with Stochastic Gradient Descent
W = W - learning_rate * dW
b = b - learning_rate * db
if t % 100 == 0:
print("Epoch: " + str(t) + " --- cost = " + str(cost))
pred = predict(X, Y, W, b, word_to_vec_map)
return pred, W, b
###################################################
print(X_train.shape)
print(Y_train.shape)
print(np.eye(5)[Y_train.reshape(-1)].shape)
print(X_train[0])
print(type(X_train))
Y = np.asarray([5,0,0,5, 4, 4, 4, 6, 6, 4, 1, 1, 5, 6, 6, 3, 6, 3, 4, 4])
print(Y.shape)
X = np.asarray(['I am going to the bar tonight', 'I love you', 'miss you my dear',
'Lets go party and drinks','Congrats on the new job','Congratulations',
'I am so happy for you', 'Why are you feeling bad', 'What is wrong with you',
'You totally deserve this prize', 'Let us go play football',
'Are you down for football this afternoon', 'Work hard play harder',
'It is suprising how people can be dumb sometimes',
'I am very disappointed','It is the best day in my life',
'I think I will end up alone','My life is so boring','Good job',
'Great so awesome'])
# (132,)
# (132,)
# (132, 5)
# never talk to me again
# <class 'numpy.ndarray'>
# (20,)執行以下程式碼訓練模型,學習 softmax 的引數
pred, W, b = model(X_train, Y_train, word_to_vec_map)
print(pred)
# Epoch: 0 --- cost = 1.95204988128
# Accuracy: 0.348484848485
# Epoch: 100 --- cost = 0.0797181872601
# Accuracy: 0.931818181818
# Epoch: 200 --- cost = 0.0445636924368
# Accuracy: 0.954545454545
# Epoch: 300 --- cost = 0.0343226737879
# Accuracy: 0.969696969697期待的輸出
| epoch | cost | Accuracy |
|---|---|---|
| Epoch: 0 | cost = 1.95204988128 | Accuracy: 0.348484848485 |
| Epoch: 100 | cost = 0.0797181872601 | Accuracy: 0.931818181818 |
| Epoch: 200 | cost = 0.0445636924368 | Accuracy: 0.954545454545 |
| Epoch: 300 | cost = 0.0343226737879 | Accuracy: 0.969696969697 |
模型在訓練集上表現的很好,下面看看在測試集上的表現。
1.4 檢驗模型在測試集上的表現
print("Training set:")
pred_train = predict(X_train, Y_train, W, b, word_to_vec_map)
print('Test set:')
pred_test = predict(X_test, Y_test, W, b, word_to_vec_map)
# Training set:
# Accuracy: 0.977272727273
# Test set:
# Accuracy: 0.857142857143期待的輸出
| key | value |
|---|---|
| Train set accuracy | 97.7 |
| Test set accuracy | 85.7 |
如果隨機猜測的話有20%的準確率,這裡表現還不錯,畢竟訓練集只有127個例子。
在測試集中,”I love you” 輸出了❤️,然我們試試”I adore you”,”adore”這個單詞並沒有在訓練集中。
X_my_sentences = np.array(["i adore you", "i love you", "funny lol", "lets play with a ball", "food is ready", "you are not happy"])
Y_my_labels = np.array([[0], [0], [2], [1], [4],[3]])
pred = predict(X_my_sentences, Y_my_labels , W, b, word_to_vec_map)
print_predictions(X_my_sentences, pred)
# Accuracy: 0.833333333333
#
# i adore you ❤️
# i love you ❤️
# funny lol ?
# lets play with a ball ⚾? food is ready ?
# you are not happy ❤️非常棒!因為”adore”和”love”的詞嵌入非常相似,演算法依然得出了正確的結果,雖然這個詞訓練時並沒有見過。你也可以試試單詞”heart, dear, beloved” 表現怎麼樣。
注意到演算法沒有準確識別”you are not happy”。因為演算法沒有考慮詞序。
列印混淆矩陣還可以幫助您瞭解模型對哪些分類更加困難。 混淆矩陣顯示標籤被誤標記的情況。
print(Y_test.shape)
print(' '+ label_to_emoji(0)+ ' ' + label_to_emoji(1) + ' ' + label_to_emoji(2)+ ' ' + label_to_emoji(3)+' ' + label_to_emoji(4))
print(pd.crosstab(Y_test, pred_test.reshape(56,), rownames=['Actual'], colnames=['Predicted'], margins=True))
plot_confusion_matrix(Y_test, pred_test)
# (56,)
#
# ❤️ ⚾️ ? ? ? ?
# Predicted 0.0 1.0 2.0 3.0 4.0 All
# Actual
# 0 6 0 0 1 0 7
# 1 0 8 0 0 0 8
# 2 2 0 16 0 0 18
# 3 1 1 2 12 0 16
# 4 0 0 1 0 6 7
# All 9 9 19 13 6 56謹記
- 即使只127個訓練樣本,也可以獲得一個良好的模型進行表情化。 這是因為詞向量泛化而獲得的。
- Emojify-V1 對於諸如”This movie is not good and not enjoyable” 這樣的句子表現不佳,因為它不理解單詞的組合(只是將所有單詞的嵌入向量進行平均,而沒有關注單詞的排序。) 你將在下一部分中構建一個更好的演算法。
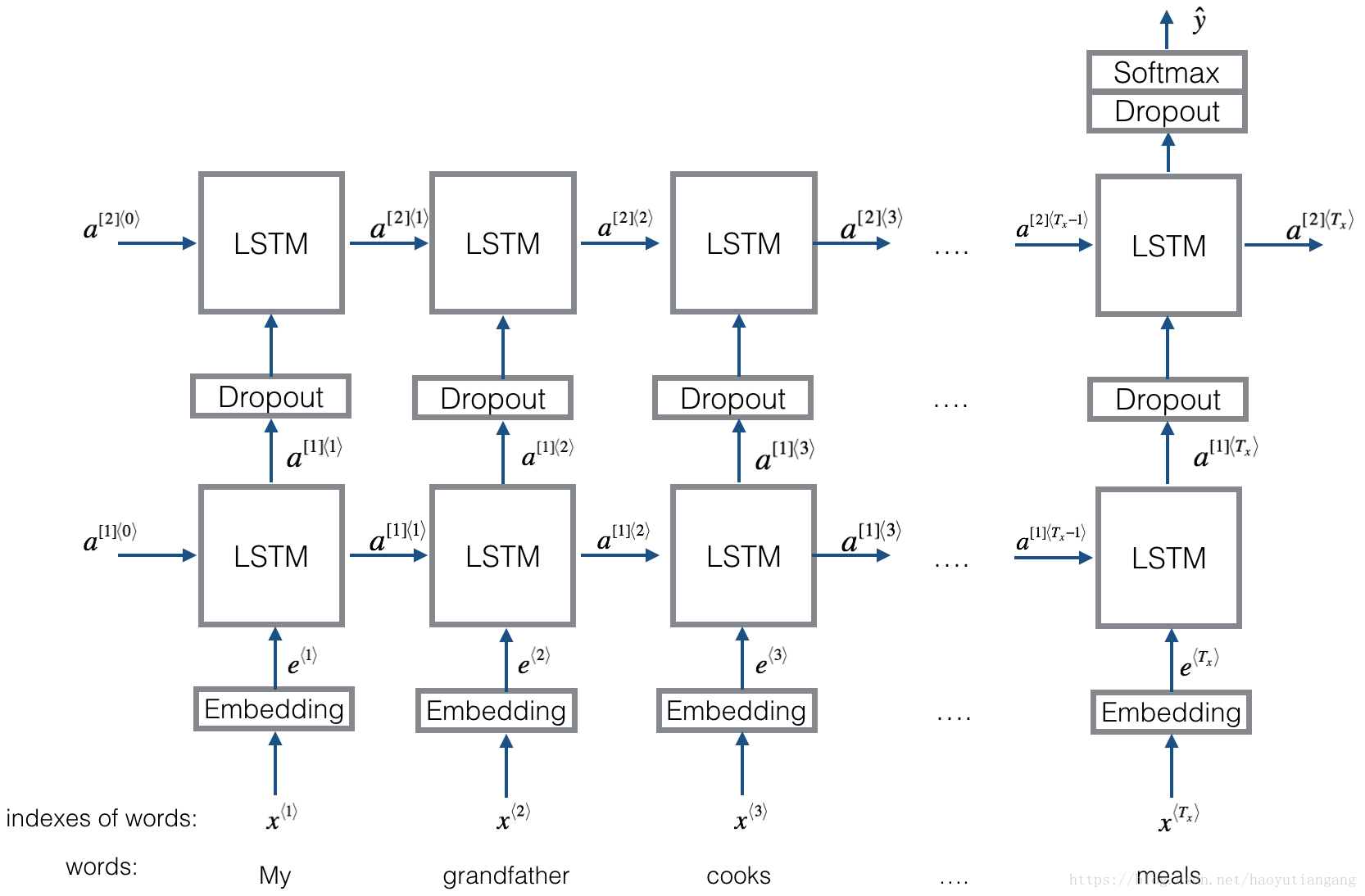
2 Emojifier-V2:使用 Keras 中的 LSTM
我們來建立一個LSTM模型,並將其作為輸入詞序列,這個模型將能夠考慮文字排序。 Emojifier-V2將繼續使用預訓練的詞嵌入來表示單詞,但會先給到LSTM中,預測最合適的表情符號。
導包
import numpy as np
np.random.seed(0)
from keras.models import Model
from keras.layers import Dense, Input, Dropout, LSTM, Activation
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
np.random.seed(1)
from keras.initializers import glorot_uniform2.1 模型概述
下面是你將要實現的Emojifier-v2模型。
2.2 Keras 和 mini-batch
在這個練習中,我們想要使用 mini-batch 訓練 Keras。然而,絕大部分深度學習框架要求同一個 mini-batch 中所有的輸入序列都要有相同的長度。也就是說如果有一個三個詞的句子,一個四個詞的句子,那麼他們不能再一個 mini-batch 中進行訓練。
通常的做法是選取訓練集最長的句子作為標準,其他不夠長的句子在後面加 padding,使之與最長句子一樣長,比如加 padding
2.3 嵌入層
在 Keras 中,嵌入矩陣作為一層來表示,將正數索引對映到固定大小的嵌入向量上。可以使用預訓練詞嵌入進行初始化或者訓練。在這個部分,我們將學習如何在 Keras 中建立 Embedding() 層,並利用上文的 Glove 50維資料作為輸入。由於我們的訓練集非常小,我們不會更新嵌入詞的大小,而是固定大小。在下面程式碼中,將展示如何在 Keras 中訓練和固定嵌入層。
Embedding() 層將一個整型矩陣作為輸入(batchSize, maxLength),將句子轉換為索引列表,輸出為(batchSize, maxLength, dimensionOfWordVectors)
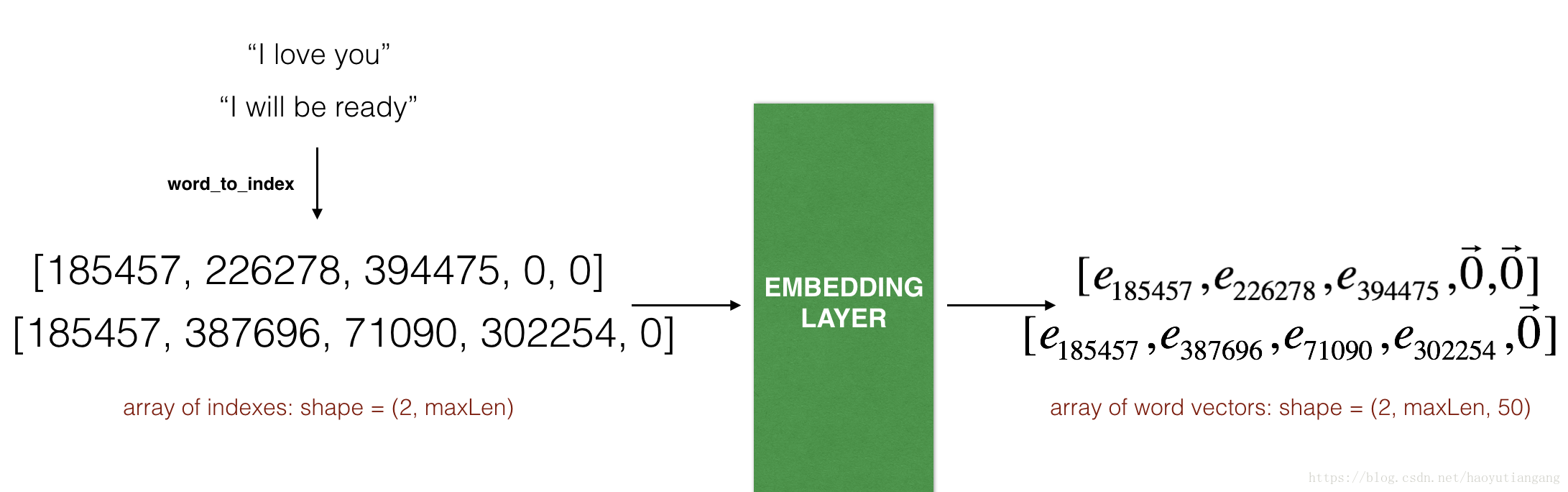
上圖展示了兩個樣本通過嵌入層的前向傳播。兩者都被填充到 的長度。 最終維度是(
Part 2: Emojify
歡迎來到本週的第二個作業,你將利用詞向量構建一個表情包。
你有沒有想過讓你的簡訊更具表現力? emojifier APP將幫助你做到這一點。 所以不是寫下”Congratulations on the promotion! L
Part 1: 詞向量運算
歡迎來到本週第一個作業。
由於詞嵌入的訓練計算量龐大切耗費時間長,絕大部分機器學習人員都會匯入一個預訓練的詞嵌入模型。
你將學到:
載入預訓練單詞向量,使用餘弦測量相似度
使用詞嵌入解決類別問題,比如 “Man is to
Part 1:Happy House 的人臉識別
本週的第一個作業我們將完成一個人臉識別系統。
人臉識別問題可以分為兩類:
人臉驗證: 輸入圖片,驗證是不是A
1:1 識別
舉例:人臉解鎖手機,人臉刷卡
人臉識別: 有一個庫,輸入圖片,驗證是不是庫裡的
Part 2: 觸發字檢測
關鍵詞語音喚醒
觸發字檢測
歡迎來到這個專業課程的最終程式設計任務!
在本週的視訊中,你瞭解瞭如何將深度學習應用於語音識別。在本作業中,您將構建一個語音資料集並實現觸發字檢測演算法(有時也稱為關鍵字檢測或喚醒檢測)。觸發字
Part 1: 構建神經網路
歡迎來到本週的第一個作業,這個作業我們將利用numpy實現你的第一個迴圈神經網路。
迴圈神經網路(Recurrent Neural Networks: RNN) 因為有”記憶”,所以在自然語言處理(Natural Languag
1.1 為什麼選擇序列模型
序列模型的應用
語音識別:將輸入的語音訊號直接輸出相應的語音文字資訊。無論是語音訊號還是文字資訊均是序列資料。
音樂生成:生成音樂樂譜。只有輸出的音樂樂譜是序列資料,輸入可以是空或者一個整數。
情感分類:將輸入的評論句子轉換
3.1 基礎模型
sequence to sequence
sequence to sequence:兩個序列模型組成,前半部分叫做編碼,後半部分叫做解碼。用於機器翻譯。
image to sequence
sequence to sequenc
本課主要講解了一些典型的卷積神經網路的思路,包括經典神經網路的leNet/AlexNet/VGG, 以及殘差網路ResNet和Google的Inception網路,順便講解了1x1卷積核的應用,便於我們進行學習和借鑑。
2.1 為什麼要進行例項探究
神經
Part 1:卷積神經網路
本週課程將利用numpy實現卷積層(CONV) 和 池化層(POOL), 包含前向傳播和可選的反向傳播。
變數說明
上標[l][l] 表示神經網路的第幾層
上標(i)(i) 表示第幾個樣本
上標[i][i] 表示第幾個mi
如果資料集沒有很大,同時在訓練集上又擬合得很好,但是在測試集的效果卻不是很好,這時候就要使用正則化來使得其擬合能力不會那麼強。
import numpy as np
import sklearn
import matplotlib.pyplot as plt
以下為在Coursera上吳恩達老師的DeepLearning.ai課程專案中,第一部分《神經網路和深度學習》第二週課程部分關鍵點的筆記。筆記並不包含全部小視訊課程的記錄,如需學習筆記中捨棄的內容請至Coursera 或者 網易雲課堂。同時在閱讀以下
本課主要講解了卷積神經網路的基礎知識,包括卷積層基礎(卷積核、Padding、Stride),卷積神經網路的基礎:卷積層、池化層、全連線層。
主要知識點
卷積核: 過濾器,各元素相乘再相加
nxn * fxf -> (n-f+1)x(n-f+1)
Part 1:人臉識別
4.1 什麼是人臉識別?
人臉驗證: 輸入圖片,驗證是不是 A
人臉識別: 有一個庫,輸入圖片,驗證是不是庫裡的一員
人臉識別難度更大,要求準確率更高,因為1%的人臉驗證錯誤在人臉識別中會被放大很多倍。
4.2 O
Ng最後一課釋出了,撒花!以下為吳恩達老師 DeepLearning.ai 課程專案中,第五部分《序列模型》第一週課程“迴圈神經網路”關鍵點的筆記。
同時我在知乎上開設了關於機器學習深度學習的專欄收錄下面的筆記,以方便大家在移動端的學習。歡迎關
完結撒花!以下為吳恩達老師 DeepLearning.ai 課程專案中,第五部分《序列模型》第三週課程“序列模型和注意力機制”關鍵點的筆記。
同時我在知乎上開設了關於機器學習深度學習的專欄收錄下面的筆記,以方便大家在移動端的學習。歡迎關注我的知
初始化
一個好的初始化可以做到:
梯度下降的快速收斂
收斂到的對訓練集只有較少錯誤的值
載入資料
import numpy as np
import matplotlib.pyplot as plt
import sklearn
impo
以下為在Coursera上吳恩達老師的DeepLearning.ai課程專案中,第一部分《神經網路和深度學習》第三週課程“淺層神經網路”部分關鍵點的筆記。筆記並不包含全部小視訊課程的記錄,如需學習筆記中捨棄的內容請至Coursera 或者 網易雲課堂
以下為在Coursera上吳恩達老師的DeepLearning.ai課程專案中,第一部分《神經網路和深度學習》第四周課程“深層神經網路”部分關鍵點的筆記。筆記並不包含全部小視訊課程的記錄,如需學習筆記中捨棄的內容請至 Coursera 或者 網易雲課
一.Convolutional Neural Networks: Step by Step
Welcome to Course 4’s first assignment! In this assignment, you will implement convol
Optimization Methods
Until now, you’ve always used Gradient Descent to update the parameters and minimize the cost. In this noteboo 相關推薦
吳恩達Coursera深度學習課程 deeplearning.ai (5-2) 自然語言處理與詞嵌入--程式設計作業(二):Emojify表情包
吳恩達Coursera深度學習課程 deeplearning.ai (5-2) 自然語言處理與詞嵌入--程式設計作業(一):詞向量運算
吳恩達Coursera深度學習課程 deeplearning.ai (4-4) 人臉識別和神經風格轉換--程式設計作業
吳恩達Coursera深度學習課程 deeplearning.ai (5-3) 序列模型和注意力機制--程式設計作業(二):觸發字檢測
吳恩達Coursera深度學習課程 deeplearning.ai (5-1) 迴圈序列模型--程式設計作業(一):構建迴圈神經網路
吳恩達Coursera深度學習課程 deeplearning.ai (5-1) 迴圈序列模型--課程筆記
吳恩達Coursera深度學習課程 deeplearning.ai (5-3) 序列模型和注意力機制--課程筆記
吳恩達Coursera深度學習課程 deeplearning.ai (4-2) 深度卷積網路:例項探究--課程筆記
吳恩達Coursera深度學習課程 deeplearning.ai (4-1) 卷積神經網路--程式設計作業
吳恩達Coursera深度學習課程 DeepLearning.ai 程式設計作業——Regularization(2-1.2)
吳恩達Coursera深度學習課程 DeepLearning.ai 提煉筆記(1-2)-- 神經網路基礎
吳恩達Coursera深度學習課程 deeplearning.ai (4-1) 卷積神經網路--課程筆記
吳恩達Coursera深度學習課程 deeplearning.ai (4-4) 人臉識別和神經風格轉換--課程筆記
吳恩達Coursera深度學習課程 DeepLearning.ai 提煉筆記(5-1)-- 迴圈神經網路
吳恩達Coursera深度學習課程 DeepLearning.ai 提煉筆記(5-3)-- 序列模型和注意力機制
吳恩達Coursera深度學習課程 deeplearning.ai (2-1) 深度學習實踐--程式設計作業
吳恩達Coursera深度學習課程 DeepLearning.ai 提煉筆記(1-3)-- 淺層神經網路
吳恩達Coursera深度學習課程 DeepLearning.ai 提煉筆記(1-4)-- 深層神經網路
吳恩達Coursera深度學習課程 DeepLearning.ai 程式設計作業——Convolution model:step by step and application (4.1)
吳恩達Coursera深度學習課程 DeepLearning.ai 程式設計作業——Optimization Methods(2-2)