
[TensorFlow入門] 線性分類器
在編寫線性分類器之前,我們先來了解一下什麼是線性函式。
線性函式
x將是我們的畫素值列表,y將是對數,對應每一個數字。讓我們來看看y = Wx,其中權重W確定x在預測每個y時的影響。

y = Wx允許我們繪出一條直線將資料對應到各自的標籤。 然而,這條線必須通過原點,因為當x等於0,y也等於0。
我們希望能夠將線從原點移開以適應更復雜的資料。最簡單的解決方案是給函式新增一個數字,我們稱之為“bias”(偏差)。

我們的新函式變為Wx + b,允許我們對線性可分離資料建立預測。讓我們使用一個具體的例子並計算結果。
矩陣乘法

a和b分別等於多少呢?
轉置
我們一直使用y = Wx + b函式作為線性函式。 但是有另一個函式做同樣的事情,y = xW + b。 這些函式做同樣的事情,可以互換,除了涉及的矩陣的維度。
要從一個函式轉換到另一個函式,您只需要交換每個矩陣的行和列維度。這稱為轉置。 TensorFlow使用的是xW + b。


TensorFlow中的Weights(權重)和Bias(偏差)
訓練神經網路的目的是修改權重和偏差以最好地預測標籤。 為了使用權重和偏差,你需要一個可以修改的Tensor。也就是說不能使用tf.placeholder()和tf.constant(),因為那些Tensors不能被修改。所以這裡應該使用tf.Variable。
tf.Variable()
x = tf.Variable(5)
tf.Variable類建立了一個具有可以修改的初始值的張量,很像一個普通的Python變數。 該張量在會話中儲存其狀態,因此您必須手動初始化張量的狀態。
使用tf.global_variables_initializer()
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
使用tf.Variable類允許我們改變權重和偏差,但是需要選擇一個初始值。如上所示,使用session(會話)呼叫tf.global_variables_initializer()操作。tf.global_variables_initializer()會返回一個操作,從計算圖中初始化所有TensorFlow變數。
用正態分佈的隨機數初始化權重是一個好的做法。而使權重隨機化則有助於避免模型在每次訓練時都卡在相同的位置。
類似地,從正態分佈選擇權重可以防止任何一個權重壓倒其他權重。
TensorFlow提供了一個tf.truncated_normal()函式從正態分佈生成隨機數。
tf.truncated_normal()
n_features = 120
n_labels = 5
weights = tf.Variable(tf.truncated_normal((n_features, n_labels)))
tf.truncated_normal()函式返回具有來自正態分佈的隨機值的張量,該正態分佈的幅度與平均值相差不超過2個標準偏差。
由於權重已經幫助防止模型卡住,你不需要再隨機化偏差。 在這裡最簡單的解決方案,將偏差設定為0。
tf.zeros()
_labels = 5
bias = tf.Variable(tf.zeros(n_labels))
tf.zeros()函式返回具有全零的張量。
線性分類器
下面讓我們使用tenosrflow構建一個線性分類器。
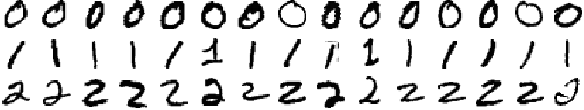
我們將使用TensorFlow的MNIST資料集對手寫數字0,1和2進行分類。 以上是您將接受培訓的資料的一個小樣本。 注意一些1是如何用頂部和不同角度的襯線寫的。 相似性和差異將在塑造模型的權重中起到作用。
上面的影象是數字0,1和2的訓練權重。權重顯示他們找到的每個數字的唯一屬性。
# quiz.py
# Note: You can't run code in this tab
import tensorflow as tf
def weights(n_features, n_labels):
"""
Return TensorFlow weights
:param n_features: Number of features
:param n_labels: Number of labels
:return: TensorFlow weights
"""
# TODO: Return weights
return tf.Variable(tf.truncated_normal((n_features, n_labels)))
def biases(n_labels):
"""
Return TensorFlow bias
:param n_labels: Number of labels
:return: TensorFlow bias
"""
# TODO: Return biases
return tf.Variable(tf.zeros(n_labels))
def linear(input, w, b):
"""
Return linear function in TensorFlow
:param input: TensorFlow input
:param w: TensorFlow weights
:param b: TensorFlow biases
:return: TensorFlow linear function
"""
# TODO: Linear Function (xW + b)
return tf.add(tf.matmul(input, w), b)
import tensorflow as tf
# Sandbox
# Note: You can't run code in this tab
from tensorflow.examples.tutorials.mnist import input_data
from quiz import weights, biases, linear
def mnist_features_labels(n_labels):
"""
Gets the first <n> labels from the MNIST dataset
:param n_labels: Number of labels to use
:return: Tuple of feature list and label list
"""
mnist_features = []
mnist_labels = []
mnist = input_data.read_data_sets('/datasets/ud730/mnist', one_hot=True)
# In order to make quizzes run faster, we're only looking at 10000 images
for mnist_feature, mnist_label in zip(*mnist.train.next_batch(10000)):
# Add features and labels if it's for the first <n>th labels
if mnist_label[:n_labels].any():
mnist_features.append(mnist_feature)
mnist_labels.append(mnist_label[:n_labels])
return mnist_features, mnist_labels
# Number of features (28*28 image is 784 features)
n_features = 784
# Number of labels
n_labels = 3
# Features and Labels
features = tf.placeholder(tf.float32)
labels = tf.placeholder(tf.float32)
# Weights and Biases
w = weights(n_features, n_labels)
b = biases(n_labels)
# Linear Function xW + b
logits = linear(features, w, b)
# Training data
train_features, train_labels = mnist_features_labels(n_labels)
with tf.Session() as session:
session.run(tf.global_variables_initializer())
# Softmax
prediction = tf.nn.softmax(logits)
# Cross entropy
# This quantifies how far off the predictions were.
# You'll learn more about this in future lessons.
cross_entropy = -tf.reduce_sum(labels * tf.log(prediction), reduction_indices=1)
# Training loss
# You'll learn more about this in future lessons.
loss = tf.reduce_mean(cross_entropy)
# Rate at which the weights are changed
# You'll learn more about this in future lessons.
learning_rate = 0.08
# Gradient Descent
# This is the method used to train the model
# You'll learn more about this in future lessons.
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
# Run optimizer and get loss
_, l = session.run(
[optimizer, loss],
feed_dict={features: train_features, labels: train_labels})
# Print loss
print('Loss: {}'.format(l))