
spark的介紹和pyspark的使用
從這個名字pyspark就可以看出來,它是由python和spark組合使用的.
相信你此時已經電腦上已經裝載了hadoop,spark,python3.
那麼我們現在開始對pyspark進行了解一番(當然如果你不想了解直接往下翻找pyspark的使用):
1. 背景:
產生與加州大學伯克利分校AMP實驗室,2013年6月稱為Apache成為孵化專案,使用Scala語言進行實現的,而Scala建立在JAVA之上,
為什麼要設計這麼一個東西?
為了改善Hadoop的MAP REDUCE的弱點:
1. 互動式和迭代式
2. 在叢集多點記憶體中執行的分散式計算
3. 容錯資料集合
為什麼要用SPARK?
1. 先進的大資料分散式程式設計和計算框架
2. 檢視替代Hadoop(Spark可以獨立與Hadoop,但是他不能替代Hadoop,因為Hadoop現在依然很重要)
3. 記憶體分散式計算:執行數度快
4. 可以使用不同的語言程式設計(java,scala,r 和python)
5. 可以從不同的資料來源獲取資料
可以從HDFS,Cassandea,HBase等等
同時可以支援很多的檔案格式:text Seq AVRO Parquet
6. 實現不同的大資料功能:Spark Core,Sparc SQL等等
2. 主要部件
1.spark core :包含spark的主要基本功能,所有和Rdd有關的API都出自於spark core
2.spark sql :spark中用於結構話處理的軟體包,使用者可以在soark環境下使用sql語言處理資料
等等(其他先不介紹)
3. 介紹一下spark core
1.它是spark生態圈的核心:
負責讀取資料
完成分散式計算
2.包含倆個重要部件
有向無環圖(DAG)的分散式平行計算框架
容錯分散式資料RDD(Resilient Distributed Dataset)
3.總體來說就是spark功能排程管理中心,用來定義和管理RDD,RDD代表了一系列資料集合分佈在基質的記憶體中,spark core 的任務就是對這些資料進行分散式計算
4.RDD(重點):
彈性分散式資料集分佈在不同的叢集節點的記憶體中,可以理解為一大陣列,陣列的每一個元素就是RDD的一個分割槽,一個RDD可以分佈並被運算在多型計算機節點的記憶體以及硬碟中,
RDD資料塊可以放在磁碟上也可以放在記憶體中(取決於你的設定),如果出現緩衝失效或丟失,RDD分割槽可以重新計算重新整理,RDD是不能被修改的但是可以通過API被變換生成新的RDD.
有倆類對RDD的操作(也成運算元):
1.變換(懶執行): 有 map flatMap groupByKey reduceByKey 等
他們只是將一些指令集而不會馬上執行,需要有操作的時候才會真正計算出結果
2.操作(立即執行): 有 count take collect 等
他們會返回結果,或者把RDD資料輸出
這些操作實現了MapReduce的基本函式map,reduce及計算模型,還提供了filter,join,groupBYKey等,另外spark sql 可以用來操作有資料結構的RDD即SPARK DATA FRAME
它的執行原理和mapreduce是一樣的,只是他們的執行方式不同,mr的運算是記憶體磁碟互動讀寫,不能在記憶體中共享資料,而RDD可以被共享和持久化.因為大資料運算經常是互動式和迭代式的,所以資料的重用性很重要,而mr的磁碟互動讀寫帶來的I/O開銷導致數度減慢
廢話這麼多了開始表演了!!
首先我們需要啟動hadoop和spark
接下來在命令列輸入:
jupyter-notebook --ip 192.168.50.129--ip 後面跟的是你此時的ip,這樣我們就會得到一個網址:
接下來我們複製它在瀏覽器上開啟,就會進入jupyter的頁面,我們通過點選new,python3來建立一個檔案

首先我們需要匯入py4j:
其實就是在python3裡面匯入了spark和sc模組
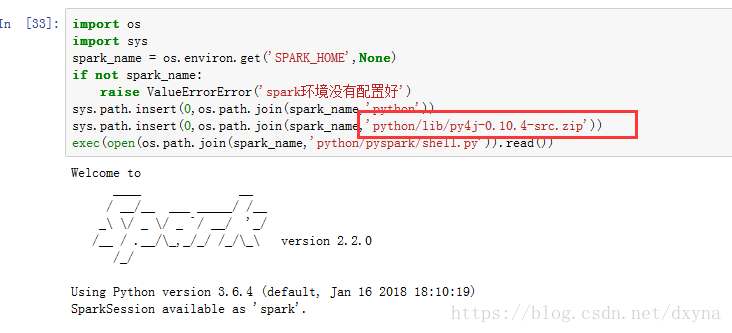
要注意了:下圖紅框裡面的要對應你spark/python/lib裡面的檔案
import os
import sys
spark_name = os.environ.get('SPARK_HOME',None)
if not spark_name:
raise ValueErrorError('spark環境沒有配置好')
sys.path.insert(0,os.path.join(spark_name,'python'))
sys.path.insert(0,os.path.join(spark_name,'python/lib/py4j-0.10.4-src.zip'))
exec(open(os.path.join(spark_name,'python/pyspark/shell.py')).read())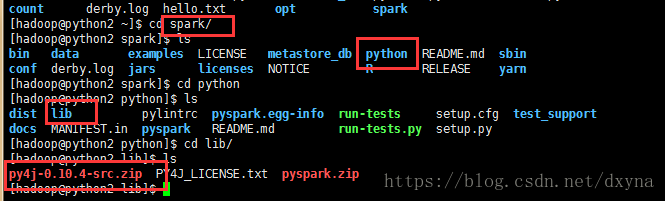
現在我們就可以使用pyspark了:
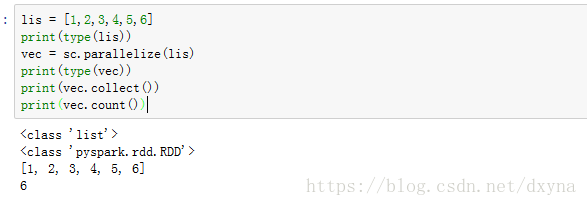
請注意,spark在互動式shell下執行時候,這裡的sc即SparkContext 的一個例項已經自動生成了,這是因為pyspark shell本身就是spark應用的driver程式,而driver程式包含應用的main函式定義RDD並在計算機叢集上進行各種操作,所以一旦獲得SparkContext object 即sc ,driver就可以訪問spark了,因此sc可以看成是driver對計算機叢集的連線.
spark裡面的core裡面的RDD有倆個組織,一個為driver另一個為worker,有點像hadoop裡面的namenode和datanode,所以driver只能有一個而worker可以為多個.driver負責獲取資料,管理worker,所以worker就負責工作.
有倆種類型的RDD:
1. 並行集合:來自與分散式化的資料物件,比如我們上面的程式碼,python裡面的list物件,再比如使用者自己鍵入的資料
並行化RDD就是通過呼叫sc的parallelize方法,在一個已經存在的資料集合上建立的(一個Seq物件),集合的物件將會被拷貝,創建出一個可以被並行操作的分散式資料集,比如上面的程式碼,演示瞭如何python中的list建立一個並行集合,並進行分行
2. 檔案系統資料集讀取資料
spark可以將任何hadoop所支援的儲存資源轉換稱RDD,如本地檔案(語言網路檔案系統),索引的節點都必須能訪問到,HDFS,mongodb,HBase,等
下面我們開始使用檔案系統集讀取資料,首先在hello裡面上傳一個檔案,比如:

開始寫程式碼:
lines = sc.textFile("hdfs://python2:9000/hello/data.csv")
既然我們已經獲取了資料那就開始操作:
1.map()
他的引數是一個函式(支援lambda函式),函式應用於RDD的每一個元素,函式的引數只能有一個,返回值是一個新的RDD

引數是一個函式,函式應用為RDD的每一個元素,引數只有1個,將資料進行拆分,變成迭代器,返回值是一個新的RDD

如上圖,可以進一步的將資料拆分出來,也可以進行新增一些別的操作,比如:

3.filter()
引數是一個函式,與python裡面的filter一樣,函式會過濾掉不符號和條件的元素,返回值是一個新的RDD

4.reduce()
並行彙總所有RDD元素,引數是一個函式,函式的引數有2個



5.countByValue()
各RDD元素在RDD中出現的次數

也可以像reduceByKey()變換每一組內彙總

6.reduceByKey()
在每一鍵組內彙總變換,檢視每一個數據在檔案裡面出現的次數

7.sortByKey()
未完待續...
附連結: