Kaldi系列--Ubuntu中TIMIT線上識別(三)
上一篇我們講解了TIMIT的訓練步驟,現在利用訓練好的模型,進行線上語音識別。
在kaldi 的工具集裡有好幾個程式可以用於線上識別。這些程式都位在src/onlinebin資料夾裡,他們是由src/online資料夾裡的檔案編譯而成(你現在可以用make ext 命令進行編譯).這些程式大多還需要tools資料夾中的portaudio 庫檔案支援,portaudio 庫檔案可以使用tools資料夾中的相應指令碼檔案下載安裝。注:online官方不再維護,新版本為online2,不過先從簡單的online開始。
這些程式羅列如下:
online-gmm-decode-faster: 從麥克風中讀取語音,並將識別結果輸出到控制檯
online-wav-gmm-decode-faster:讀取wav檔案列表中的語音,並將識別結果以指定格式輸出。
online-server-gmm-decode-faster:從UDP連線資料中獲取語音MFCC向量,並將識別結果列印到控制檯。
online-net-client :從麥克風錄音,並將它轉換成特徵向量,並通過UDP連線傳送給online-server-gmm-decode-faster
online-audio-server-decode-faster :從tcp連線中讀取原始語音資料,並且將識別結果返回給客戶端
online-audio-client :讀出wav檔案列表,並將他們通過tcp 傳送到online-audio-server-decode-fater,得到返回的識別結果後,將他存成指定的檔案格式
程式碼中還有一個java版的online-audio-client ,他包含更多的功能,並且有一個介面。另外,還有一個與GStreamer 1.0相容的外掛,他可以對輸入的語音進行識別,並輸出的文字結果。這個外掛基於onlinefasterDecoder,也可以做為線上識別程式
1、安裝portaudio
首先我們cd到tools下面,執行:sudo ./install_portaudio.sh,然後在cd到src下面,執行:sudo make ext
(我第一次線上live識別的時候portaudio報錯,解決方法是:先進入tools/portaudio,用./configure檢視依賴,通常情況alsa顯示no,通過sudo apt-get install libasound-dev可以解決。然後進入/tools,執行:./install_portaudio.sh。回到/src目錄,編譯擴充套件程式:make ext 。可以用arecord測試一下Ubuntu錄音機是否正常:arecord -f cd -r 16000 -d 5 test.wav
2、接下來跑tri1。去egs下,開啟voxforge,裡面有個online_demo,直接拷貝到timit下,和s5同級。在online_demo裡面建2個資料夾online-data work,在online-data下建兩個資料夾audio和models,audio下放你要回放的wav,models建個資料夾tri1,把s5下的exp下的tri1下的final.mdl和35.mdl拷貝過去。把s5下的exp下的tri1下的graph_word裡面的words.txt,和HCLG.fst,拷貝到models的tri1下。
3、修改修改tri1地址online_demo下的run.sh
1) 修改tri1位置
#ac_model_type=tri2b_mmi
ac_model_type=tri1
2)註釋掉如下程式碼(這段是voxforge例子中下載現網的測試語料和識別模型的。我們測試語料自己準備,模型就是tri1了)
#if [ ! -s ${data_file}.tar.bz2 ]; then
# echo "Downloading test models and data ..."
# wget -T 10 -t 3 $data_url;
#
# if [ ! -s ${data_file}.tar.bz2 ]; then
# echo "Download of $data_file has failed!"
# exit 1
# fi
#fi
3) 修改model為final.mdl
# online-wav-gmm-decode-faster --verbose=1 --rt-min=0.8 --rt-max=0.85\
# --max-active=4000 --beam=12.0 --acoustic-scale=0.0769 \
# scp:$decode_dir/input.scp $ac_model/model $ac_model/HCLG.fst \
# $ac_model/words.txt '1:2:3:4:5' ark,t:$decode_dir/trans.txt \
# ark,t:$decode_dir/ali.txt $trans_matrix;;
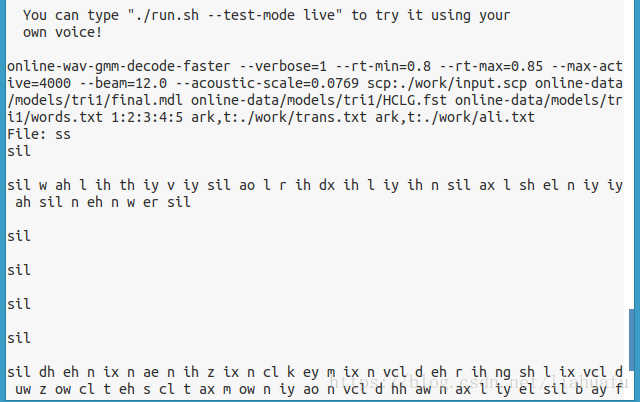
online-wav-gmm-decode-faster --verbose=1 --rt-min=0.8 --rt-max=0.85\
--max-active=4000 --beam=12.0 --acoustic-scale=0.0769 \
scp:$decode_dir/input.scp $ac_model/final.mdl $ac_model/HCLG.fst \
$ac_model/words.txt '1:2:3:4:5' ark,t:$decode_dir/trans.txt \
ark,t:$decode_dir/ali.txt $trans_matrix;;
4、./run.sh開始識別audio資料夾下的語音(這個語音引數需要16bit,16Khz,我用Audacity錄了幾段)。./run.sh --test-mode live 命令就是從麥克風識別(如果提示錯誤,可參考https://blog.csdn.net/u012236368/article/details/71628777)。