
BloomFilter——大規模資料處理利器
Bloom Filter是由Bloom在1970年提出的一種多雜湊函式對映的快速查詢演算法。通常應用在一些需要快速判斷某個元素是否屬於集合,但是並不嚴格要求100%正確的場合。
例項
為了說明Bloom Filter存在的重要意義,舉一個例項:
假設要你寫一個網路蜘蛛(web crawler)。由於網路間的連結錯綜複雜,蜘蛛在網路間爬行很可能會形成“環”。為了避免形成“環”,就需要知道蜘蛛已經訪問過哪些URL。給一個URL,怎樣知道蜘蛛是否已經訪問過呢?稍微想想,就會有如下幾種方案:
1. 將訪問過的URL儲存到資料庫。
2. 用HashSet將訪問過的URL儲存起來,那隻需接近O(1)的代價就可以查到一個URL是否被訪問過了。
3. URL經過MD5或SHA-1等單向雜湊後再儲存到HashSet或資料庫。
4. Bit-Map方法。建立一個BitSet,將每個URL經過一個雜湊函式對映到某一位。
方法1~3都是將訪問過的URL完整儲存,方法4則只標記URL的一個對映位。以上方法在資料量較小的情況下都能完美解決問題,但是當資料量變得非常龐大時問題就來了。
方法1的缺點:資料量變得非常龐大後關係型資料庫查詢的效率會變得很低。而且每來一個URL就啟動一次資料庫查詢是不是太小題大做了?
方法2的缺點:太消耗記憶體。隨著URL的增多,佔用的記憶體會越來越多。就算只有1億個URL,每個URL只算50個字元,就需要5GB記憶體。
方法3:由於字串經過MD5處理後的資訊摘要長度只有128Bit,SHA-1處理後也只有160Bit,因此方法3比方法2節省了好幾倍的記憶體。
方法4消耗記憶體是相對較少的,但缺點是單一雜湊函式發生衝突的概率太高。還記得資料結構課上學過的Hash表衝突的各種解決方法麼?若要降低衝突發生的概率到1%,就要將BitSet的長度設定為URL個數的100倍。
實質上上面的演算法都忽略了一個重要的隱含條件:允許小概率的出錯,不一定要100%準確!也就是說少量url實際上沒有被網路蜘蛛訪問,而將它們錯判為已訪問的代價是很小的——大不了少抓幾個網頁唄。
Bloom Filter的演算法
廢話說到這裡,下面引入本篇的主角——Bloom Filter。其實上面方法4的思想已經很接近Bloom Filter了。方法四的致命缺點是衝突概率高,為了降低衝突的概念,Bloom Filter使用了多個雜湊函式,而不是一個。
Bloom Filter演算法如下:
建立一個m位BitSet,先將所有位初始化為0,然後選擇k個不同的雜湊函式。第i個雜湊函式對字串str雜湊的結果記為h(i, str),且h(i, str)的範圍是0到m-1 。
- 加入字串過程
下面是每個字串處理的過程,首先是將字串str“記錄”到BitSet中的過程:
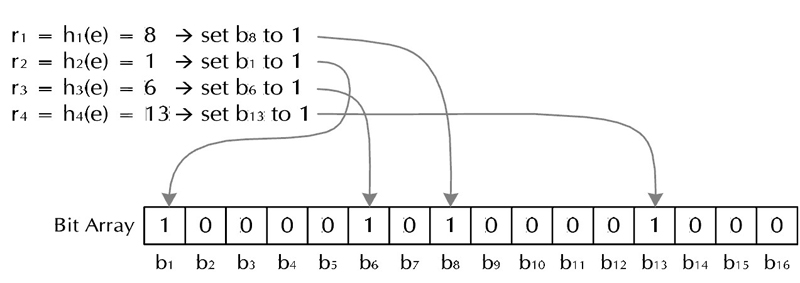
對於字串str,分別計算h(1, str),h(2, str)……h(k, str)。然後將BitSet的第h(1, str),h(2, str)……h(k, str)位設為1,如下圖所示:
很簡單吧?這樣就將字串str對映到BitSet中的k個二進位制位了。 - 檢查字串是否存在的過程
下面是檢查字串str是否被BitSet記錄過的過程:
對於字串str,分別計算h(1, str),h(2, str)……h(k, str)。然後檢查BitSet的第h(1, str),h(2, str)……h(k, str)位是否為1,若其中任何一位不為1則可以判定str一定沒有被記錄過。若全部位都是1,則“認為”字串str存在。
若一個字串對應的Bit不全為1,則可以肯定該字串一定沒有被Bloom Filter記錄過。(這是顯然的,因為字串被記錄過,其對應的二進位制位肯定全部被設為1了)。
但是若一個字串對應的Bit全為1,實際上是不能100%的肯定該字串被Bloom Filter記錄過的。(因為有可能該字串的所有位都剛好是被其他字串所對應)這種將該字串劃分錯的情況,稱為false positive 。 - 刪除字串過程
字串加入了就被不能刪除了,因為刪除會影響到其他字串。實在需要刪除字串的可以使用Counting bloomfilter(CBF),這是一種基本Bloom Filter的變體,CBF將基本Bloom Filter每一個Bit改為一個計數器,這樣就可以實現刪除字串的功能了。
Bloom Filter跟單雜湊函式Bit-Map不同之處在於:Bloom Filter使用了k個雜湊函式,每個字串跟k個bit對應。從而降低了衝突的概率。
Bloom Filter引數選擇
- 雜湊函式選擇
雜湊函式的選擇對效能的影響應該是很大的,一個好的雜湊函式要能近似等概率的將字串對映到各個Bit。選擇k個不同的雜湊函式比較麻煩,一種簡單的方法是選擇一個雜湊函式,然後送入k個不同的引數。 - Bit陣列大小選擇
雜湊函式個數k、位陣列大小m、加入的字串數量n的關係可以參考參考文獻1。該文獻證明了對於給定的m、n,當 k = ln(2)* m/n 時出錯的概率是最小的。
同時該文獻還給出特定的k,m,n的出錯概率。例如:根據參考文獻1,雜湊函式個數k取10,位陣列大小m設為字串個數n的20倍時,false positive發生的概率是0.0000889 ,這個概率基本能滿足網路爬蟲的需求了。
Bloom Filter實現程式碼
下面給出一個簡單的Bloom Filter的Java實現程式碼:
package binggou;
import java.util.BitSet;
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
public class BloomFilter {
/**
* BitSet初始分配2^13個bit
*/
private static final int DEFAULT_SIZE = 1 << 13;
/**
* 不同雜湊函式的種子,一般應取質數
*/
private static final int[] seeds = new int[]{5, 7, 11, 13, 31, 37, 61};
private BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* 雜湊函式物件
*/
private SimpleHash[] func = new SimpleHash[seeds.length];
public BloomFilter() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
// 將字串標記到bits中
public void add(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
// 判斷字串是否已經被bits標記
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
/**
* 雜湊函式類
*/
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
//hash函式,採用簡單的加權和hash
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
/**
* 測試
* @param args
*/
public static void main(String[] args) {
String string = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
Set<String> set = new HashSet<String>();
BloomFilter bloomFilter = new BloomFilter();
Random random = new Random();
int length = 10;
// 生成隨機字串
for (int i = 0; i < 1024; i++) {
String str = "";
for (int j = 0; j < length; j++) {
str = str + string.charAt(random.nextInt(62));
}
set.add(str);
bloomFilter.add(str);
}
// 測試BloomFilter
for (int i = 0; i < 1024; i++) {
String str = "";
for (int j = 0; j < length; j++) {
str = str + string.charAt(random.nextInt(62));
}
if (set.contains(str) != bloomFilter.contains(str)) {
System.out.println("str = " + str);
}
}
}
}