MR執行流程詳解
一、在我們提交完MR程式之後,MR程式會先後經歷map,reduce階段,下面我們詳細的來解析一下各個階段
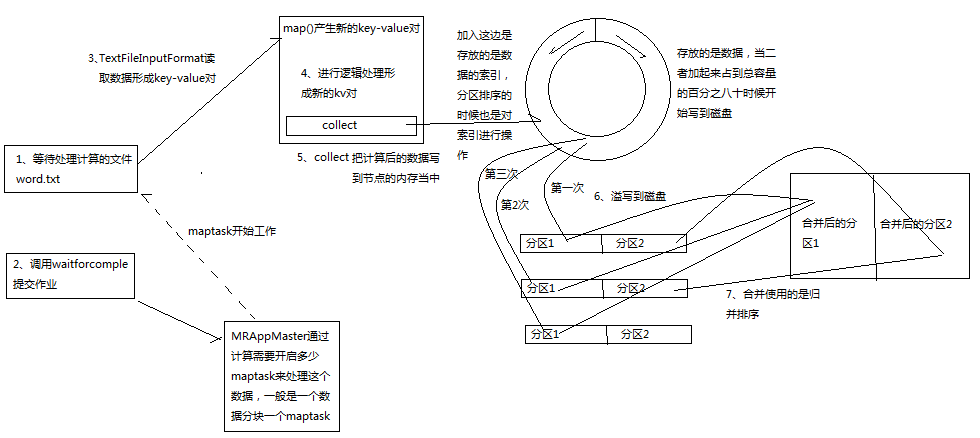
1、map階段,在這個階段主要分如下的幾個步驟read,map,collect,溢寫,combine階段
(1)、在read階段,maptask會呼叫使用者自定義的RecordReader方法,在splitInput中解析出一個個的key-value對
(2)、在map階段,maptask會接受由前面讀取來的資料,然後按照所需的邏輯對資料進行加工處理,形成新的key-value對
(3)、在collect階段,map在資料處理完成之後會呼叫OutputCollector.collect()方法把資料寫入環形緩衝區中,這個環形緩衝區被分為了兩部分,一半是用來儲存資料的索引,一半是用來儲存資料,在分割槽中首先是按照分割槽號進行排序,在分割槽裡面在按照key進行排序,在環形緩衝區中預設的採用的是雜湊分割槽,如果想自定義分割槽可以重寫一個類繼承partition在重新分割槽方法即可。
(4)、溢寫階段,當環形緩衝區中的資料到達整個緩衝區的百分之八十的時候(環形緩衝區預設大小是100M),就會把資料寫入本地的臨時檔案,但是為了提高效能在這兒可以呼叫combiner首先把資料合併之後再把資料寫入零時檔案,在環形緩衝區上的資料讀寫方法時索引儲存資料和儲存索引佔到總大小的百分之八十多的時候,雙方在結束的位置同時向開始的位置讀取資料,這樣迴圈往復。
(5)、合併階段,在前面產生的所有的臨時檔案,maptask採用輪轉的方式進行合併,並且在合併之後的分割槽中進行排序,這樣這個map就會產生一個數據的輸出檔案。
(6)如下圖所示
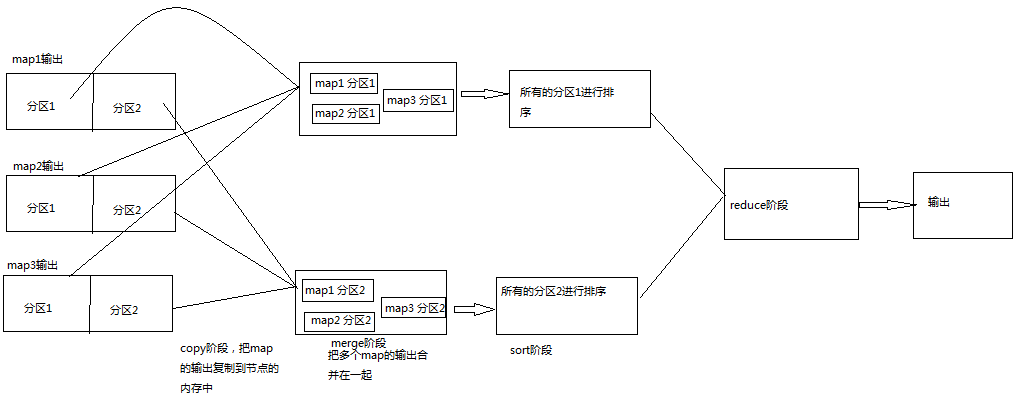
2、reduce階段主要包括如下的階段,cpoy階段,merge階段,sort階段,reduce階段
(1)、copy階段主要是reducer階段從遠端的map的輸出去拷貝資料到本地的記憶體中,同一個reducer的節點會把不同的map的輸出的同一個分割槽拷貝到本地。
(2)、merge階段,在開始拷貝資料的時候。reduceTask會啟動兩個後臺執行緒,合併記憶體中的資料和磁碟中的資料,防止使用過多的記憶體和磁碟。
(3)、sort階段,由於在reduce的資料是按照key進行聚合排序的,但是在map的輸出的時候就已經進行排序,所以在這兒只需要簡單的歸併排序即可
(4)、reduce階段 ,把已經按照key聚合的資料輸出給reducer按照我們的義務邏輯進行處理。
(5)、具體如下圖所示