
Hadoop1.X mapreduce原理和缺陷
MapReduce的簡介:
MapReduce是一個軟體框架,客房部件的編寫應用程式,一併行的方式在數千商用硬體組成的叢集節點中處理TB級的資料,並且提供了可靠性和容錯的能力。
MapReduce的正規化:
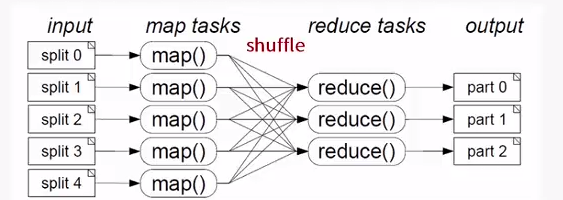
MapReduce處理模型包括兩個獨立的步驟:
A. 第一步是並行Map階段,輸入資料被分割成離散塊以便可以單獨處理
B. Shuffle階段
C. 第二步是Reduce階段,彙總Map階段的輸出生成預期的結果。
MapReduce的缺陷:
A. 可擴充套件性:
a) JobTracker記憶體中儲存使用者作業的資訊
b) JobTracker使用的是粗粒度的鎖
B. 可靠性和可用性:
a) JobTracker失效會多事叢集中所有的執行作業,使用者需手動重新提交和恢復工作流
C. 對不同程式設計模型的支援
a) HadoopV1以MapReduce為中心的設計雖然能支援廣泛的用例,但是並不適合所有大型計算
相關推薦
Hadoop1.X mapreduce原理和缺陷
MapReduce的簡介: MapReduce是一個軟體框架,客房部件的編寫應用程式,一併行的方式在數千商用硬體組成的叢集節點中處理TB級的資料,並且提供了可靠性和容錯的能力。 MapReduce
Glusterfs解析之分散式(dht)原理和缺陷
目錄 GlusterFS之分散式(Distribute )分析 1 GlusterFS分散式概念(應用場景) 1.1 誰發現了哪些問題,導致需要GlusterFS分散式?(who) 1.2什麼地方發現了問題,導致需要GlusterFS分散式?(who) 1.3什麼時
圖解mapreduce原理和執行過程
說明: 下面的圖來自南京大學計算機系黃宜華老師開設的mapreduce課程的課件,這裡稍作整理和 總結。 本文旨在對接觸了mapreduce之後,但是對mapreduce的工作流程仍不是很清楚的人員,當然包括博主自己,希望與大家一起學習。 mapreduce的原理
hadoop1.x與hadoop2.x在HDFS和MapReduce上的區別
HDFS改進 ·hadoop1.x的HDFS體系架構 在Hadoop1.x中的NameNode只可能有一個,雖然可以通過SecondaryNameNode與NameNode進行資料同步備份,但是總會存在一定的延時,如果NameNode掛掉,但是如果有部份
Hadoop1.x版本和Hadoop2.x版本架構原理
MapReduce 1.x 架構 MapReduce 1.x 採用 Master/Slave 架構,由全域性唯一的 Jobtracker 和多個 TaskTacker 組成,並且在Client中提供一系列的api供程式設計和管理使用。 1.client 提供a
【原創】MapReduce運行原理和過程
文件合並 pil file 運行流程 dfs lec 線程 操作 合並 一.Map的原理和運行流程 Map的輸入數據源是多種多樣的,我們使用hdfs作為數據源。文件在hdfs上是以block(塊,Hdfs上的存儲單元)為單位進行存儲的。 1.分片 我們將
spark原理和spark與mapreduce的最大區別
參考文件:https://files.cnblogs.com/files/han-guang-xue/spark1.pdf 參考網址:https://www.cnblogs.com/wangrd/p/6232826.html 對於spark個人理解: spark與mapreduce最
【圖文詳細 】HDFS面試題:hadoop1.x和2.x架構上的區別
(1)Hadoop 1.0 Hadoop 1.0即第一代Hadoop,由分散式儲存系統HDFS和分散式計算框架MapReduce組成,其中,HDFS由一個NameNode和多個DataNode組成,MapReduce由一個JobTracker和多個TaskTracker組成,對應Hadoop
Hadoop1.x: 詳解Shuffle過程---map和reduce資料互動的關鍵
文章來源: Shuffle描述著資料從map task輸出到reduce task輸入的這段過程。 個人理解: map執行的結果會儲存為本地的一個檔案中: 只要map執行 完成,記憶體中的map資料就一定會儲存到本地檔案,儲存這個檔案有個過程 叫做spi
大資料入門基礎系列之Hadoop1.X、Hadoop2.X和Hadoop3.X的多維度區別詳解(博主推薦)
不多說,直接上乾貨! 在前面的博文裡,我已經介紹了 見下面我寫的微信公眾號博文 歡迎大家,加入我的微信公眾號:大資料躺過的坑 免費給分享 同時,大家可以關注我的個人部
MapReduce二次排序原理和實現
/** * 自己定義的key類應該實現WritableComparable介面 */ public class IntPair implements WritableComparable<IntPair>{ int first;//第一個成員變數 int second;//第二個成員變數 p
MapReduce多使用者任務排程器——容量排程器(Capacity Scheduler)原理和原始碼研究
前言:為了研究需要,將Capacity Scheduler和Fair Scheduler的原理和程式碼進行學習,用兩篇文章作為記錄。如有理解錯誤之處,歡迎批評指正。 容量排程器(Capacity Scheduler)是Yahoo公司開發的多使用者排程器。多使用者排程器的使用
Hadoop 1.x HDFS理論和底層原理
1、 NameNode:儲存元資料,存放檔案資訊,檔案密度越大,其佔有空間越大,記憶體硬碟各一份,執行時載入到記憶體中,包含了檔案資訊、 塊對映,DataNode對映等對映關係; 響應客戶請求,並轉移到對應的DataNode進行相應的操作。 2、 DataNode:儲存檔案內容的,儲存於硬碟中;
MapReduce運行原理和過程
設置 他在 輸入數據 pre .html spl 運行流程 key-value 不同顏色 原文 一.Map的原理和運行流程 Map的輸入數據源是多種多樣的,我們使用hdfs作為數據源。文件在hdfs上是以block(塊,Hdfs上的存儲單元)為單位進行存儲的
MapReduce Shuffle 和 Spark Shuffle 原理概述
Shuffle簡介 Shuffle的本意是洗牌、混洗的意思,把一組有規則的資料儘量打亂成無規則的資料。而在MapReduce中,Shuffle更像是洗牌的逆過程,指的是將map端的無規則輸出按指定的規則“打亂”成具有一定規則的資料,以便reduce端接收處理。其在MapReduce中所處的工作階段是map輸出
Hadoop框架:MapReduce基本原理和入門案例
本文原始碼:[GitHub·點這裡](https://github.com/cicadasmile/big-data-parent) || [GitEE·點這裡](https://gitee.com/cicadasmile/big-data-parent) # 一、MapReduce概述 ## 1、基本
貝葉斯算法的基本原理和算法實現
utf shape less 流程 我們 def .sh 詞向量 貝葉斯算法 一. 貝葉斯公式推導 樸素貝葉斯分類是一種十分簡單的分類算法,叫它樸素是因為其思想基礎的簡單性:就文本分類而言,它認為詞袋中的兩兩詞之間的關系是相互獨立的,即一個對象 的特征向量
base64加密和解碼原理和代碼
先來 自動 clas enter 緩沖區 urn rar col his Base64編碼,是我們程序開發中經常使用到的編碼方法。它是一種基於用64個可打印字符來表示二進制數據的表示方法。它通常用作存儲、傳輸一些二進制數據編碼方法!也是MIME(多用途互聯網郵件擴展,主要用
D. Powerful array 離線+莫隊算法 給定n個數,m次查詢;每次查詢[l,r]的權值; 權值計算方法:區間某個數x的個數cnt,那麽貢獻為cnt*cnt*x; 所有貢獻和即為該區間的值;
code ++ 計算方法 equal ati contains tdi ces sum D. Powerful array time limit per test 5 seconds memory limit per test 256 megabytes input st
動態替換Linux核心函數的原理和實現
c函數 路徑 pla ges sta images 語句 堆棧 mit 轉載:https://www.ibm.com/developerworks/cn/linux/l-knldebug/ 動態替換Linux核心函數的原理和實現 在調試Linux核心模塊時,有時需要