
Deep Residual Network學習(二)
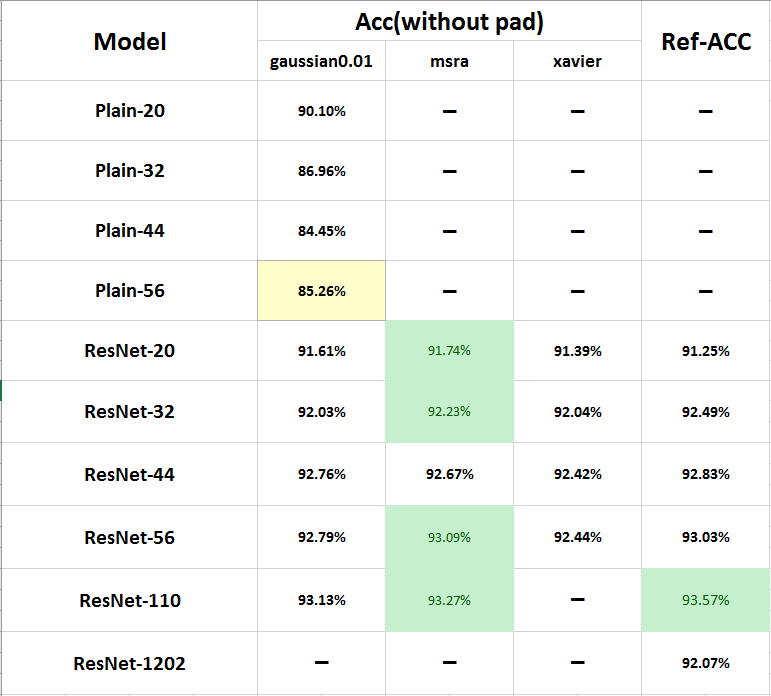
通過上次在Cifar10上覆現ResNet的結果,我們得到了上表,最後一欄是論文中的結果,可以看到已經最好的初始化方法(MSRA)已經和論文中的結果非常接近了!今天我們完全按照論文中的實驗環境,復現一下ResNet論文中的結果。
上次的論文復現主要和原文中有兩點不同:
1.Data Augmentation
Cifar10中的影象都是32X32的,論文中對測試集中的每張圖在每邊都擴充套件了4個畫素,得到40X40的影象,在訓練時隨機crop出32X32的影象進行訓練,而對測試集不做任何操作
import lmdb
import cv2
import caffe
from caffe.proto import caffe_pb2
env1=lmdb.open('cifar10_train_lmdb')
txn1=env1.begin()
cursor=txn1.cursor()
datum=caffe_pb2.Datum()
env2=lmdb.open('cifar10_pad4_train_lmdb',map_size=50000*1000*10)
txn2=env2.begin(write=True)
count=0
for key,value in cursor:
datum.ParseFromString(value)
label=datum.label
data=caffe.io.datum_to_array(datum)
img=data.transpose(1,2,0)
pad=cv2.copyMakeBorder(img,4,4,4,4,cv2.BORDER_REFLECT)
array=pad.transpose(2,0,1)
datum1=caffe.io.array_to_datum(array,label)
str_id='{:08}'.format(count)
txn2.put(str_id,datum1.SerializeToString())
count+=1
if count%1000 ==0:
print('already handled with {} pictures'.format(count))
txn2.commit()
txn2=env2.begin(write=True)
txn2.commit()
env2.close()
env1.close()
程式很容易理解,最關鍵的是這句:
pad=cv2.copyMakeBorder(img,4,4,4,4,cv2.BORDER_REFLECT)
使用cv2的makeBorder函式擴充套件4個畫素,執行後本地就會得到cifar10_pad4_train_lmdb了,注意,均值檔案也需要重新生成,用於訓練集資料
2.Different Shortcut Structure
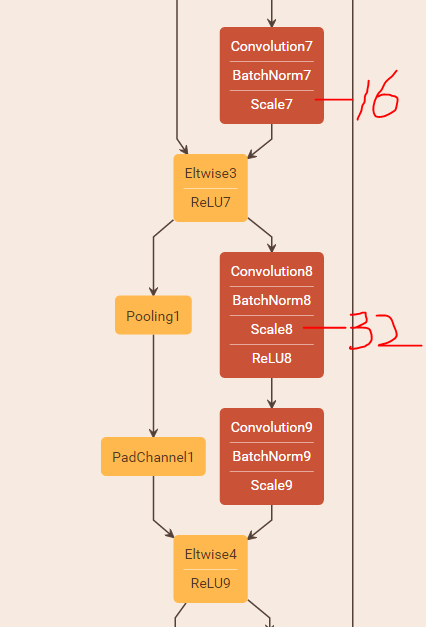
這是將網路結構藉助ethereon繪製出來的部分截圖,上面的紅字代表這一層的卷積過濾器的數量,可以看到在filter數量加倍之後,shortcut結構沒法直接相加了,所以原文中採用了PadChannel的結構,將多餘的Channel全部補零,主要結構就是上圖所示,先用一個average pooling層將feature map的size減半,再使用PadChannel增加16層的零filter層,我們將這種方法稱為zero-padding法

看一下官方關於新增新層的說明,主要是以下四個檔案:
1.pad_channel_layer.hpp新增到include/caffe/layers:
#ifndef CAFFE_PAD_CHANNEL_LAYER_HPP_ #define CAFFE_PAD_CHANNEL_LAYER_HPP_ #include "caffe/blob.hpp" #include "caffe/layer.hpp" #include "caffe/proto/caffe.pb.h" namespace caffe { /* * @brief zero-padding channel to extend number of channels * * Note: Back-propagate just drop the pad derivatives */ template <typename Dtype> class PadChannelLayer : public Layer<Dtype> { public: explicit PadChannelLayer(const LayerParameter& param) : Layer<Dtype>(param) {} virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top); virtual void Reshape(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top); virtual inline const char* type() const { return "PadChannel"; } virtual inline int ExactNumBottomBlobs() const { return 1; } virtual inline int ExactNumTopBlobs() const { return 1; } protected: virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top); virtual void Backward_cpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom); virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top); virtual void Backward_gpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom); int num_channels_to_pad_; }; } // namespace caffe #endif // CAFFE_PAD_CHANNEL_LAYER_HPP_
2.pad_channel_layer.cpp新增到src/caffe/layers
#include "caffe/layers/pad_channel_layer.hpp"
namespace caffe {
template <typename Dtype>
void PadChannelLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
CHECK_NE(top[0], bottom[0]) << this->type() << " Layer does not "
"allow in-place computation.";
num_channels_to_pad_ = this->layer_param_.pad_channel_param().num_channels_to_pad();
CHECK_GT(num_channels_to_pad_, 0) << "num channels to pad must greater than 0!";
}
template <typename Dtype>
void PadChannelLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
vector<int> top_shape = bottom[0]->shape();
top_shape[1] += num_channels_to_pad_;
top[0]->Reshape(top_shape);
}
template <typename Dtype>
void PadChannelLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
int num = bottom[0]->num();
int channels = bottom[0]->channels();
int dim = bottom[0]->height() * bottom[0]->width();
int channel_by_dim = channels * dim;
for (int n = 0; n < num; n++){
caffe_copy(channel_by_dim, bottom_data, top_data);
bottom_data += channel_by_dim;
top_data += channel_by_dim;
caffe_set(num_channels_to_pad_ * dim, Dtype(0), top_data);
top_data += num_channels_to_pad_ * dim;
}
}
template <typename Dtype>
void PadChannelLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& top) {
const Dtype* top_diff = top[0]->cpu_diff();
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
int num = bottom[0]->num();
int channels = bottom[0]->channels();
int dim = bottom[0]->height() * bottom[0]->width();
int channel_by_dim = channels * dim;
for (int n = 0; n < num; n++){ // just drop the padding derivatives part.
caffe_copy(channel_by_dim, top_diff, bottom_diff);
top_diff += (channels + num_channels_to_pad_) * dim;
bottom_diff += channel_by_dim;
}
}
INSTANTIATE_CLASS(PadChannelLayer);
REGISTER_LAYER_CLASS(PadChannel);
} // namespace caffe
3.pad_channel_layer.cu新增到src/caffe/layers:
#include "caffe/layers/pad_channel_layer.hpp"
namespace caffe {
// Copy (one line per thread) from one array to another, with arbitrary
// strides in the last two dimensions.
template <typename Dtype>
__global__ void pad_forward_kernel(const int dst_count, const int src_channels, const int dst_channels,
const int dim, const Dtype* src, Dtype* dst){
CUDA_KERNEL_LOOP(index, dst_count)
{
int num = index / (dim * dst_channels);
int dst_c = index / dim % dst_channels;
int pixel_pos = index % dim;
if (dst_c < src_channels)
dst[index] = src[num * src_channels * dim + dst_c * dim + pixel_pos];
else
dst[index] = Dtype(0);
}
}
template <typename Dtype>
void PadChannelLayer<Dtype>::Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top){
const Dtype* bottom_data = bottom[0]->gpu_data();
Dtype* top_data = top[0]->mutable_gpu_data();
int src_channels = bottom[0]->channels();
int dim = bottom[0]->height() * bottom[0]->width();
int dst_channels = src_channels + num_channels_to_pad_;
const int dst_count = top[0]->count();
pad_forward_kernel<Dtype> << <CAFFE_GET_BLOCKS(dst_count), CAFFE_CUDA_NUM_THREADS >> >(
dst_count, src_channels, dst_channels, dim, bottom_data, top_data);
CUDA_POST_KERNEL_CHECK;
}
template <typename Dtype>
__global__ void pad_backward_kernel(const int bottom_count, const int bottom_channels, const int top_channels,
const int dim, const Dtype* top, Dtype* bottom)
{
CUDA_KERNEL_LOOP(index, bottom_count)
{
int num = index / (dim * bottom_channels);
int bottom_c = index / dim % bottom_channels;
int pixel_pos = index % dim;
bottom[index] = top[num * top_channels * dim + bottom_c * dim + pixel_pos];
}
}
template <typename Dtype>
void PadChannelLayer<Dtype>::Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
const Dtype* top_diff = top[0]->gpu_diff();
Dtype* bottom_diff = bottom[0]->mutable_gpu_diff();
int bottom_count = bottom[0]->count();
int bottom_channels = bottom[0]->channels();
int dim = bottom[0]->height() * bottom[0]->width();
int top_channels = bottom_channels + num_channels_to_pad_;
pad_backward_kernel<Dtype> << <CAFFE_GET_BLOCKS(bottom_count), CAFFE_CUDA_NUM_THREADS >> >(
bottom_count, bottom_channels, top_channels, dim, top_diff, bottom_diff);
CUDA_POST_KERNEL_CHECK;
}
INSTANTIATE_LAYER_GPU_FUNCS(PadChannelLayer);
} // namespace caffe
4.向caffe.proto中新增對應的message:
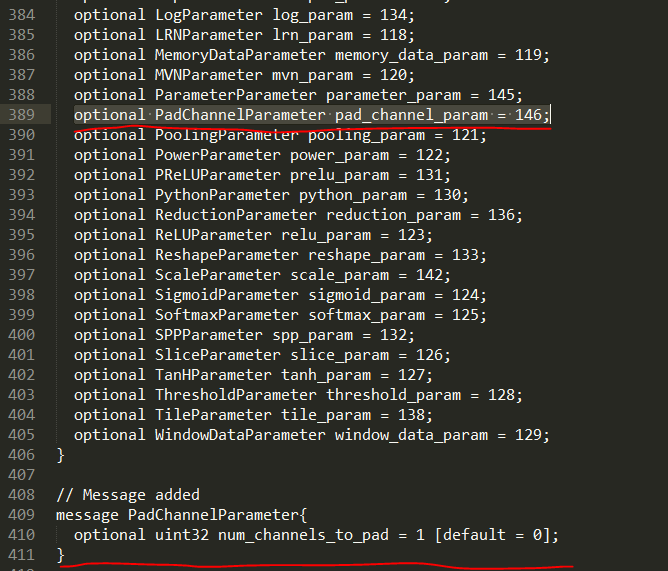
好的,重新編譯一次caffe之後,我們就可以使用PadChannel層了!
下面我們看一下另外一種shortcut結構:
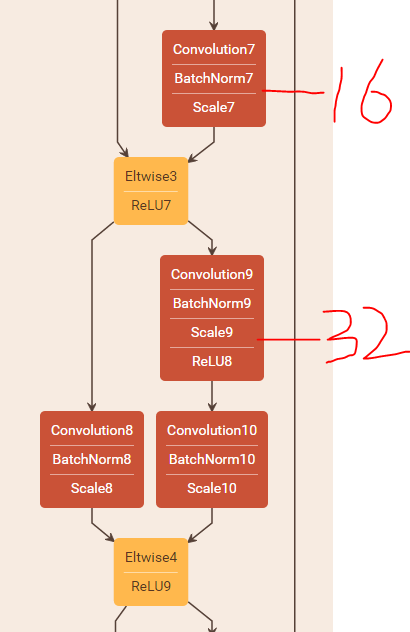
論文中將這種結構稱為projection(亦即option B),使用1x1的卷積核來增加維度,這種方法會引入額外的引數!
3.復現實驗
好的,現在一切準備就緒,我們開始完整復現ResNet在Cifar10上的實驗結果:
以下是一些引數設定:
weight_decay=0.0001 momentum=0.9
batch_size=128
learning_rate=0.1,0.01/32k,0.001/48k
max_iter=64k
當層數達到110層時,為加快收斂,我們先將learning_rate設定為0.01,迭代400次之後,再將learning_rate設定回0.1,正常進行訓練
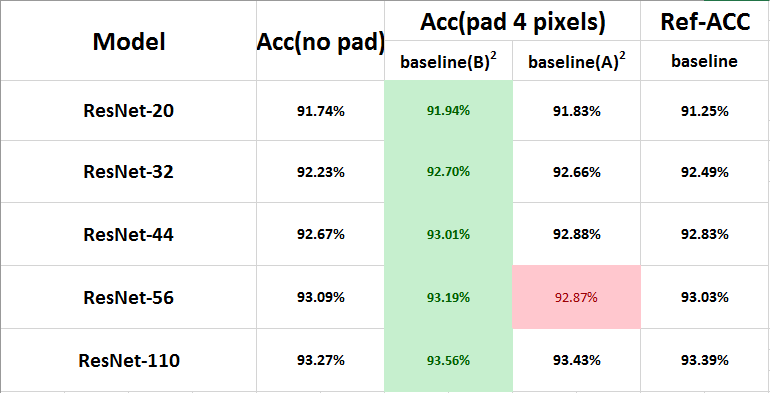
A代表zero-padding,B代表projection,可以看出,Option A得到的結果和論文中基本一致,因為論文中採用的就是這種方法,而Option B卻是所有結果中最好的,可以看出projection的方法是要優於zero_padding的方法的!
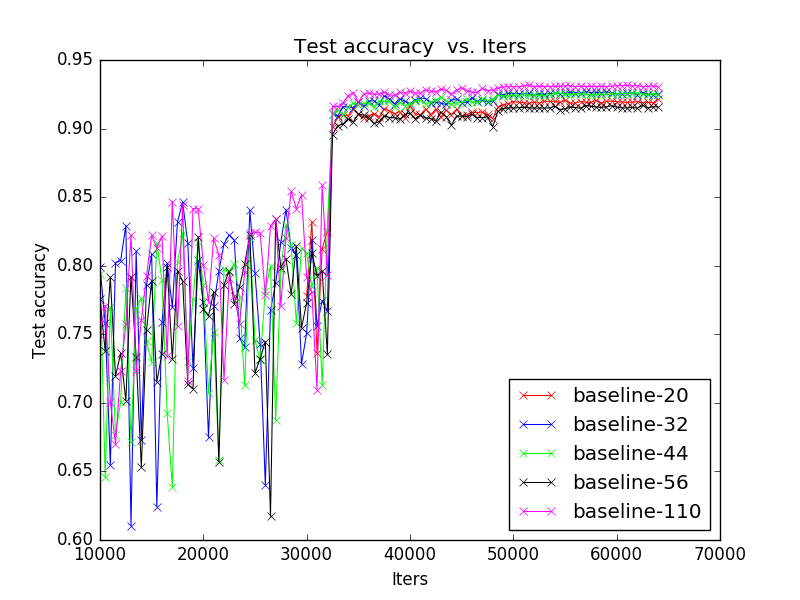
接下來放幾張訓練的結果圖:
首先是zero_padding:
接下來是projection:
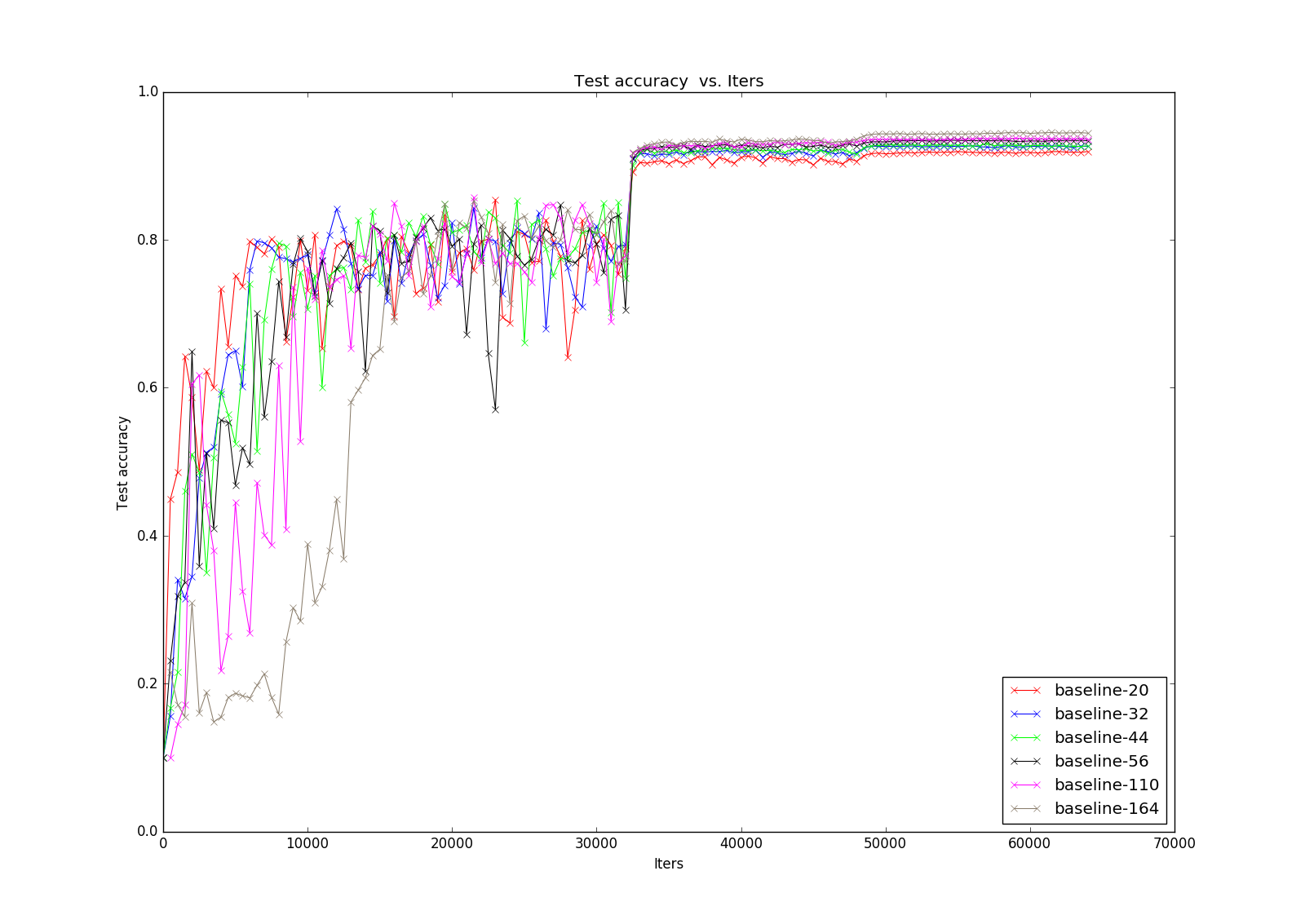
(這裡暫時先忽略164的結果)
4.總結
至此,ResNet在cifar10的復現實驗已經全部完成,我們完美復現了論文中的結果,甚至還得到了比論文中更好的結果!