
[caffe]深度學習之MSRA影象分類模型Deep Residual Network(深度殘差網路)解讀
一、簡介
MSRA的深度殘差網路在2015年ImageNet和COCO如下共5個領域取得第一名:ImageNet recognition, ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation。
二、網路分析
該文章借鑑了highway networks的idea,在此idea基礎上,文章就簡單的加深網路會使得訓練誤差加大這個問題展開了分析,文章提出假設:加入的後續層如果都能夠做到將前一層的結果直接map到下一層的話,那麼該加深後的網路理論上是保持一樣的誤差而不是增大訓練誤差了。那麼也就說明現有的求解器solvers在我剛構造出來的更深網路上並不能找到比我好的解。那麼我是不是可以引入殘差(在很多領域應用到過)的概念,讓該求解器能夠穩定下來更容易收斂呢?答案是肯定的,文章在多個數據集上驗證了自己的想法。
網路中殘差的表示式可以統一寫成如下公式:y = F(X, {Wi}) + WsX,其中Ws 只有在feature map維度不同的時候才用到,可以是pad零,也可以是1x1卷積核(文中大部分採用這種projection)。當殘差用於兩層全連線層的時候,其F = W2σ(W1X),網路單元如下圖所示:
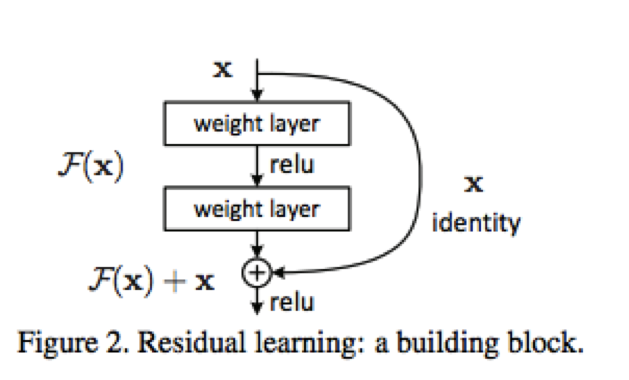
當然殘差也可以用於卷積層,應用於卷積層的時候,各個對應feature map相加,網路單元如下圖所示:
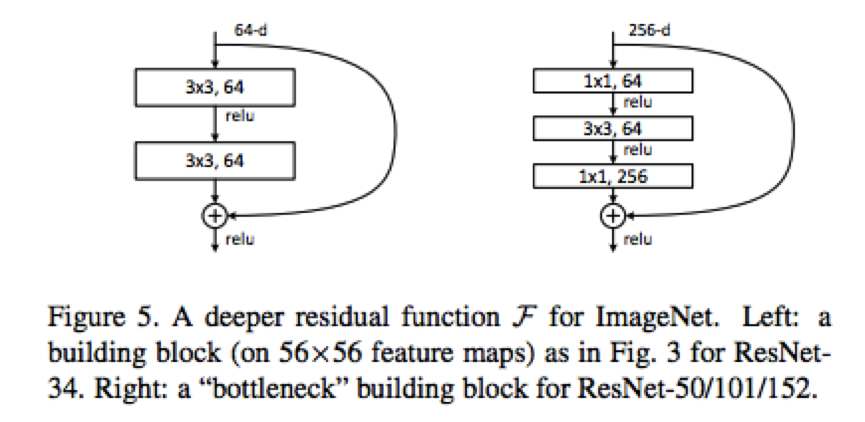
左邊用於34層殘差網路,考慮到計算複雜度當殘差超過50層及以上的時候採用右邊的結構。
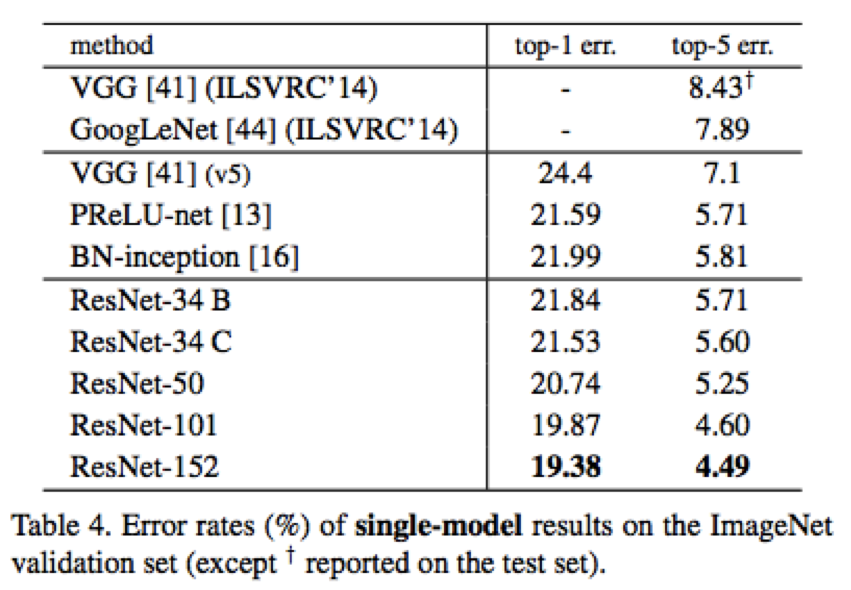
34層殘差網路的設計規則有如下幾點:1. 大部分使用3x3的卷積核 2. 如果輸出的feature map大小一樣,則設定相同個數的卷積核 3. 如果輸出的feature map大小減小了一半,則卷積核加倍以保持每一層執行時間相仿。該方法的單模型效果如下:
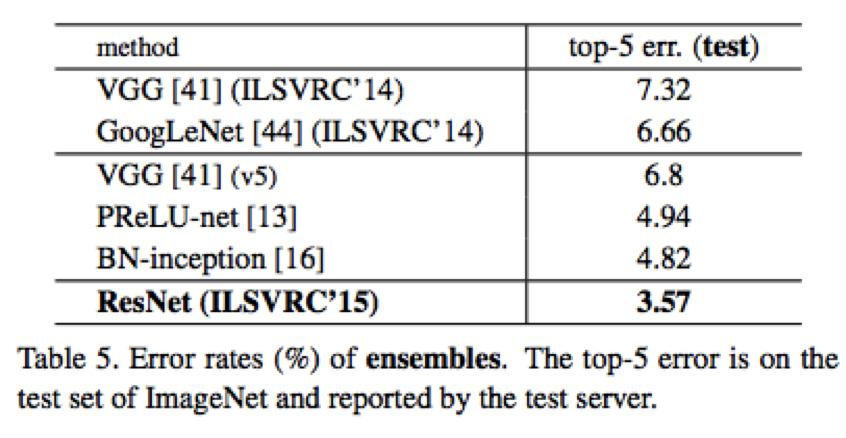
多模型融合結果如下:
相關推薦
[caffe]深度學習之MSRA影象分類模型Deep Residual Network(深度殘差網路)解讀
一、簡介 MSRA的深度殘差網路在2015年ImageNet和COCO如下共5個領域取得第一名:ImageNet recognition, ImageNet detection, ImageNet localization, COCO detection,
[深度學習] Image Classification影象分類之Bag of Tricks for Image Classification with Convolutional Neural Net
論文全稱:《Bag of Tricks for Image Classification with Convolutional Neural Networks》 論文地址:https://arxiv.org/pdf/1812.01187.pdf 這篇文章主要討論最近這些訓練神經網路的tric
基於深度學習的遙感影象分類總概
部落格轉載自:https://blog.csdn.net/qq_40116035/article/details/81414835 傳統的分類方法分兩種:監督分類和非監督分類。監督分類要求對所要分類的地區必須要有先驗的類別知識,即先要從所研究地區中選擇出所有要區分的各類地物的訓練區,用於建立
深度學習之五:序列模型與詞向量
1 迴圈序列模型 1.1 序列模型的適用範圍 序列模型是一種用於處理序列資料的模型,它可以用於語音識別,音樂生成,情感分類,機器翻譯,命名實體識別等。模型的輸出也可能是一個序列。 1.2 相關的符號約定 x<k>x<k>
深度學習---MRI醫學影象分類
深度學習現在越來越火,也越來越多的研究工作人員用深度學習研究生物醫學影象。 以上三張圖片是成年人的大腦核磁共振影象,從左至右分別表示正常人、輕微某病、嚴重某病。 現在我在用深度學習(BP神經網路、CNN卷積神經網路、遷移學習等)在研究如何分類。 我會將我的最新研究結
深度學習之(十一)Deep learning中的優化方法:隨機梯度下降、受限的BFGS、共軛梯度法
三種常見優化演算法:SGD(隨機梯度下降),LBFGS(受限的BFGS),CG(共軛梯度法)。 1.SGD(隨機梯度下降) 隨機梯度下降(Stochastic Gradient Descent, SGD)是隨機和優化相結合的產物,是一種很神奇的優化方法,屬於
強化學習之猜猜我是誰--- Deep Q-Network ^_^
導致 line d+ callbacks ima new div pan dense Deep Q-Network和Q-Learning怎麽長得這麽像,難道它們有關系? 沒錯,Deep Q-Network其實是Q-Learning融合了神經網絡的一種方法 這次我們以打飛機的
深度學習FPGA實現基礎知識6(Deep Learning(深度學習)學習資料大全及CSDN大牛部落格推薦)
Deep Learning(深度學習) Machine Learning(機器學習): Computer Vision(計算機視覺): OpenCV相關: 2012年7月4日隨著opencv2.4.2版本的釋出,opencv更
深度學習FPGA實現基礎知識10(Deep Learning(深度學習)卷積神經網路(Convolutional Neural Network,CNN))
第一點,在學習Deep learning和CNN之前,總以為它們是很了不得的知識,總以為它們能解決很多問題,學習了之後,才知道它們不過與其他機器學習演算法如svm等相似,仍然可以把它當做一個分類器,仍然可以像使用一個黑盒子那樣使用它。 第二點,Deep Learning強大的地方就是可以利用網路中間某一
論文閱讀筆記之——《DN-ResNet: Efficient Deep Residual Network for Image Denoising》
本文提出的DN-ResNet,就是a deep convolutional neural network (CNN) consisting of several residual blocks (ResBlocks).感覺有點類似於SRResNet的思路。並且對於訓練這個作者所提出的網路,作者還
[caffe]深度學習之影象分類模型VGG解讀
一、簡介 vgg和googlenet是2014年imagenet競賽的雙雄,這兩類模型結構有一個共同特點是go deeper。跟googlenet不同的是,vgg繼承了lenet以及alexnet的一些框架,尤其是跟alexnet框架非常像,vgg也是5個group的卷積、
深度學習之影象分類模型AlexNet解讀
版權宣告:本文為博主原創文章 https://blog.csdn.net/sunbaigui/article/details/39938097 在imagenet上的影象分類challenge上Alex提出的alexnet網路結構模型贏得了2012屆的冠軍。要研究CNN型別
深度學習之影象分類模型AlexNet結構分析和tensorflow實現
在ImageNet上的影象分類challenge上,Hinton和他的學生Alex Krizhevsky提出的AlexNet網路結構模型贏得了2012屆的冠軍,重新整理了Image Classification的機率。因此,要研究CNN型別深度學習模型在影象分
深度學習核心技術實戰——影象分類模型
影象分類模型1.LeNet-5: 每一個卷積核都會形成一個特徵圖,3個通道則是每個通道是不同的卷積核,但是最後是將三通道
【深度學習之Caffe】將模型測試Classification過程生成動態連結庫dll以方便其他專案呼叫
#include "caffe_classify.h" #include "head.h" Classifier::Classifier(const string& model_file,const string& trained_file,const string& mean
深度學習之文字分類模型-前饋神經網路(Feed-Forward Neural Networks)
目錄DAN(Deep Average Network)Fasttextfasttext文字分類fasttext的n-gram模型Doc2vec DAN(Deep Average Network) MLP(Multi-Layer Perceptrons)叫做多層感知機,即由多層網路簡單堆疊而成,進而我們可以在輸
深度學習之模型構建
water ssi sum sta eat rom col ffffff oss 標準模型 from keras.utils import plot_model from keras.models import Model from keras.layers import
深度學習之影象的資料增強方法彙總
參考:https://www.jianshu.com/p/99450dbdadcf 在深度學習專案中,尋找資料花費了相當多的時間。但在很多實際的專案中,我們難以找到充足的資料來完成任務。為了要保證完美地完成專案,有兩件事情需要做好:1、尋找更多的資料;2、資料增強。本篇主要描述資料增強。 有
深度學習之影象的資料增強
本文轉載自:http://www.cnblogs.com/gongxijun/p/6117588.html 在影象的深度學習中,為了豐富影象訓練集,更好的提取影象特徵,泛化模型(防止模型過擬合),一般都會對資料影象進行資料增強,資料增強,常用的方式,就是:旋轉影象,剪下影象,改變影象色差,扭
深度學習之儲存和讀取tensorflow模型
儲存和讀取 TensorFlow 模型 儲存變數 載入變數 訓練一個模型並儲存它的權重 載入訓練好的模型 訓練一個模型的時間很長。但是你一旦關閉了 TensorFlow session,你所有訓練的權重和偏置項都丟失了。如果你計劃在之