
八大排序演算法Java
概述
排序有內部排序和外部排序,內部排序是資料記錄在記憶體中進行排序,而外部排序是因排序的資料很大,一次不能容納全部的排序記錄,在排序過程中需要訪問外存。
我們這裡說說八大排序就是內部排序。
當n較大,則應採用時間複雜度為O(nlog2n)的排序方法:快速排序、堆排序或歸併排序序。
快速排序:是目前基於比較的內部排序中被認為是最好的方法,當待排序的關鍵字是隨機分佈時,快速排序的平均時間最短;
1.插入排序—直接插入排序(Straight Insertion Sort)
基本思想:
將一個記錄插入到已排序好的有序表中,從而得到一個新,記錄數增1的有序表。即:先將序列的第1個記錄看成是一個有序的子序列,然後從第2個記錄逐個進行插入,直至整個序列有序為止。
要點:設立哨兵,作為臨時儲存和判斷陣列邊界之用。
直接插入排序示例:
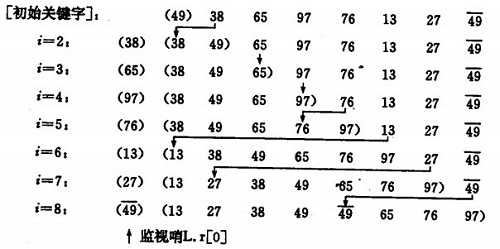
如果碰見一個和插入元素相等的,那麼插入元素把想插入的元素放在相等元素的後面。所以,相等元素的前後順序沒有改變,從原無序序列出去的順序就是排好序後的順序,所以插入排序是穩定的。
演算法的實現:
package sortPractice; public class InsertSort { public static void main(String[] args) { int a[] = {3,1,5,7,2,4,9,6,10,8}; InsertSort obj=new InsertSort(); System.out.println("初始值:"); obj.print(a); obj.insertSort(a); System.out.println("\n排序後:"); obj.print(a); } public void print(int a[]){ for(int i=0;i<a.length;i++){ System.out.print(a[i]+" "); } } public void insertSort(int[] a) { for(int i=1;i<a.length;i++){//從頭部第一個當做已經排好序的,把後面的一個一個的插到已經排好的列表中去。 int j; int x=a[i];//x為待插入元素 for( j=i; j>0 && x<a[j-1];j--){//通過迴圈,逐個後移一位找到要插入的位置。 a[j]=a[j-1]; } a[j]=x;//插入 } } }
//2017.10.15對程式碼進行優化(時間複雜度O(n^2))效率:
時間複雜度:O(n^2).
其他的插入排序有二分插入排序,2-路插入排序。
2. 插入排序—希爾排序(Shell`s Sort)
希爾排序是1959 年由D.L.Shell 提出來的,相對直接排序有較大的改進。希爾排序又叫縮小增量排序
基本思想:
先將整個待排序的記錄序列分割成為若干子序列分別進行直接插入排序,待整個序列中的記錄“基本有序”時,再對全體記錄進行依次直接插入排序。
操作方法:
- 選擇一個增量序列t1,t2,…,tk,其中ti>tj,tk=1;
- 按增量序列個數k,對序列進行k 趟排序;
- 每趟排序,根據對應的增量ti,將待排序列分割成若干長度為m 的子序列,分別對各子表進行直接插入排序。僅增量因子為1 時,整個序列作為一個表來處理,表長度即為整個序列的長度。
希爾排序的示例:
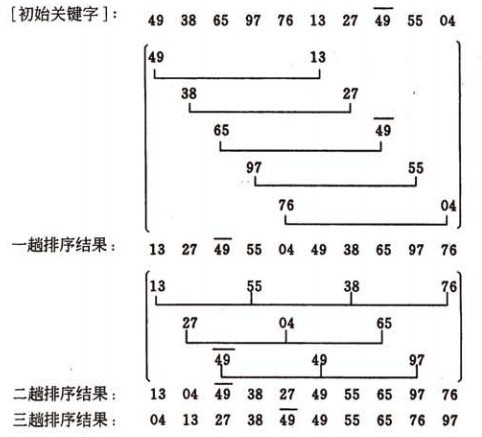
演算法實現:
我們簡單處理增量序列:增量序列d = {n/2 ,n/4, n/8 .....1} n為要排序數的個數
即:先將要排序的一組記錄按某個增量d(n/2,n為要排序數的個數)分成若干組子序列,每組中記錄的下標相差d.對每組中全部元素進行直接插入排序,然後再用一個較小的增量(d/2)對它進行分組,在每組中再進行直接插入排序。繼續不斷縮小增量直至為1,最後使用直接插入排序完成排序。
package com;
/*
* Java實現希爾排序(縮小增量排序)
* author:wyr
* 2016-7-14
*兩個步驟:1,建堆 2,對頂與堆的最後一個元素交換位置
*/
public class ShellSort {
public static void main(String[] args) {
int a[] = {3,1,5,7,2,4,9,6,10,8};
ShellSort obj=new ShellSort();
System.out.println("初始值:");
obj.print(a);
obj.shellSort(a);
System.out.println("\n排序後:");
obj.print(a);
}
private void shellSort(int[] a) {
int dk = a.length/2;
while( dk >= 1 ){
ShellInsertSort(a, dk);
dk = dk/2;
}
}
private void ShellInsertSort(int[] a, int dk) {//類似插入排序,只是插入排序增量是1,這裡增量是dk,把1換成dk就可以了
for(int i=dk;i<a.length;i++){
if(a[i]<a[i-dk]){
int j;
int x=a[i];//x為待插入元素
a[i]=a[i-dk];
for(j=i-dk; j>=0 && x<a[j];j=j-dk){//通過迴圈,逐個後移一位找到要插入的位置。
a[j+dk]=a[j];
}
a[j+dk]=x;//插入
}
}
}
public void print(int a[]){
for(int i=0;i<a.length;i++){
System.out.print(a[i]+" ");
}
}
}
希爾排序時效分析很難,關鍵碼的比較次數與記錄移動次數依賴於增量因子序列d的選取,特定情況下可以準確估算出關鍵碼的比較次數和記錄的移動次數。目前還沒有人給出選取最好的增量因子序列的方法。增量因子序列可以有各種取法,有取奇數的,也有取質數的,但需要注意:增量因子中除1 外沒有公因子,且最後一個增量因子必須為1。希爾排序方法是一個不穩定的排序方法。
3. 選擇排序—簡單選擇排序(Simple Selection Sort)
基本思想:
在要排序的一組數中,選出最小(或者最大)的一個數與第1個位置的數交換;然後在剩下的數當中再找最小(或者最大)的與第2個位置的數交換,依次類推,直到第n-1個元素(倒數第二個數)和第n個元素(最後一個數)比較為止。
簡單選擇排序的示例:
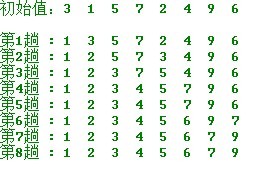
操作方法:
第一趟,從n 個記錄中找出關鍵碼最小的記錄與第一個記錄交換;
第二趟,從第二個記錄開始的n-1 個記錄中再選出關鍵碼最小的記錄與第二個記錄交換;
以此類推.....
第i 趟,則從第i 個記錄開始的n-i+1 個記錄中選出關鍵碼最小的記錄與第i 個記錄交換,
直到整個序列按關鍵碼有序。
演算法實現:
package com;
/*
* Java實現希爾排序(縮小增量排序)
* author:wyr
* 2016-7-14
*兩個步驟:1,建堆 2,對頂與堆的最後一個元素交換位置
*/
public class SimpleSelectSort {
public static void main(String[] args) {
int a[] = {3,1,5,7,2,4,9,6,10,8};
SimpleSelectSort obj=new SimpleSelectSort();
System.out.println("初始值:");
obj.print(a);
obj.selectSort(a);
System.out.println("\n排序後:");
obj.print(a);
}
private void selectSort(int[] a) {
for(int i=0;i<a.length;i++){
int k=i;//k存放最小值下標。每次迴圈最小值下標+1
for(int j=i+1;j<a.length;j++){//找到最小值下標
if(a[k]>a[j])
k=j;
}
swap(a,k,i);//把最小值放到它該放的位置上
}
}
public void print(int a[]){
for(int i=0;i<a.length;i++){
System.out.print(a[i]+" ");
}
}
public void swap(int[] data, int i, int j) {
if (i == j) {
return;
}
data[i] = data[i] + data[j];
data[j] = data[i] - data[j];
data[i] = data[i] - data[j];
}
}
簡單選擇排序的改進——二元選擇排序
簡單選擇排序,每趟迴圈只能確定一個元素排序後的定位。我們可以考慮改進為每趟迴圈確定兩個元素(當前趟最大和最小記錄)的位置,從而減少排序所需的迴圈次數。改進後對n個數據進行排序,最多隻需進行[n/2]趟迴圈即可。具體實現如下:
[cpp] view plain copy print?- void SelectSort(int r[],int n) {
- int i ,j , min ,max, tmp;
- for (i=1 ;i <= n/2;i++) {
- // 做不超過n/2趟選擇排序
- min = i; max = i ; //分別記錄最大和最小關鍵字記錄位置
- for (j= i+1; j<= n-i; j++) {
- if (r[j] > r[max]) {
- max = j ; continue ;
- }
- if (r[j]< r[min]) {
- min = j ;
- }
- }
- //該交換操作還可分情況討論以提高效率
- tmp = r[i-1]; r[i-1] = r[min]; r[min] = tmp;
- tmp = r[n-i]; r[n-i] = r[max]; r[max] = tmp;
- }
- }
4. 選擇排序—堆排序(Heap Sort)
堆排序是一種樹形選擇排序,是對直接選擇排序的有效改進。基本思想:
堆的定義如下:具有n個元素的序列(k1,k2,...,kn),當且僅當滿足
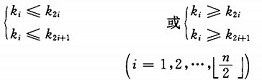
時稱之為堆。由堆的定義可以看出,堆頂元素(即第一個元素)必為最小項(小頂堆)。
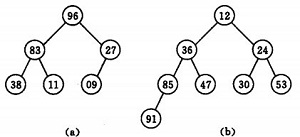
若以一維陣列儲存一個堆,則堆對應一棵完全二叉樹,且所有非葉結點的值均不大於(或不小於)其子女的值,根結點(堆頂元素)的值是最小(或最大)的。如:
(a)大頂堆序列:(96, 83,27,38,11,09)
(b) 小頂堆序列:(12,36,24,85,47,30,53,91)
初始時把要排序的n個數的序列看作是一棵順序儲存的二叉樹(一維陣列儲存二叉樹),調整它們的儲存序,使之成為一個堆,將堆頂元素輸出,得到n 個元素中最小(或最大)的元素,這時堆的根節點的數最小(或者最大)。然後對前面(n-1)個元素重新調整使之成為堆,輸出堆頂元素,得到n 個元素中次小(或次大)的元素。依此類推,直到只有兩個節點的堆,並對它們作交換,最後得到有n個節點的有序序列。稱這個過程為堆排序。
因此,實現堆排序需解決兩個問題:
1. 如何將n 個待排序的數建成堆;
2. 輸出堆頂元素後,怎樣調整剩餘n-1 個元素,使其成為一個新堆。
首先討論第二個問題:輸出堆頂元素後,對剩餘n-1元素重新建成堆的調整過程。
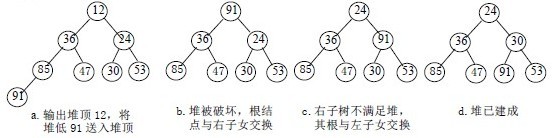
調整小頂堆的方法:
1)設有m 個元素的堆,輸出堆頂元素後,剩下m-1 個元素。將堆底元素送入堆頂((最後一個元素與堆頂進行交換),堆被破壞,其原因僅是根結點不滿足堆的性質。
2)將根結點與左、右子樹中較小元素的進行交換。
3)若與左子樹交換:如果左子樹堆被破壞,即左子樹的根結點不滿足堆的性質,則重複方法 (2).
4)若與右子樹交換,如果右子樹堆被破壞,即右子樹的根結點不滿足堆的性質。則重複方法 (2).
5)繼續對不滿足堆性質的子樹進行上述交換操作,直到葉子結點,堆被建成。
稱這個自根結點到葉子結點的調整過程為篩選。如圖:
再討論對n 個元素初始建堆的過程。
建堆方法:對初始序列建堆的過程,就是一個反覆進行篩選的過程。
1)n 個結點的完全二叉樹,則最後一個結點是第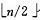 個結點的子樹。
個結點的子樹。
2)篩選從第個結點為根的子樹開始,該子樹成為堆。
3)之後向前依次對各結點為根的子樹進行篩選,使之成為堆,直到根結點。
如圖建堆初始過程:無序序列:(49,38,65,97,76,13,27,49)
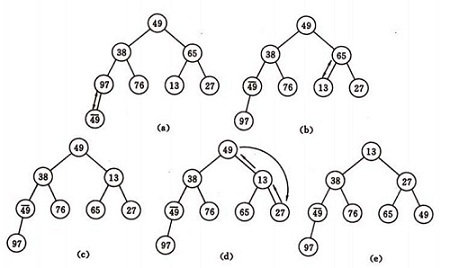

演算法的實現:
從演算法描述來看,堆排序需要兩個過程,一是建立堆,二是堆頂與堆的最後一個元素交換位置。所以堆排序有兩個函式組成。一是建堆的滲透函式,二是反覆呼叫滲透函式實現排序的函式。
package com;
/*
* Java實現快速排序演算法
* 由大到小排序
* author:wyr
* 2016-7-14
*兩個步驟:1,建堆 2,對頂與堆的最後一個元素交換位置
*/
public class HeapSort {
public static void main(String[] args) {
int a[] = {3,1,5,7,2,4,9,6,10,8};
HeapSort obj=new HeapSort();
System.out.println("初始值:");
obj.print(a);
for(int i=0;i<a.length;i++){
obj.createLittleHeap(a,a.length-1-i);//建立堆,建立的是小頂堆。每次迴圈完,二叉樹的根節點都是最小值,所以與此時的未排好部分最後一個值交換位置
obj.swap(a, 0, a.length - 1 - i);//與最後一個值交換位置,最小值找到了位置
obj.print(a);
System.out.println();
}
System.out.println("\n排序後:");
obj.print(a);
}
/*
* 建立小頂堆:雙親節點小於子節點的值。從葉子節點開始,直到根節點。這樣建立的堆定位最小值
*/
private void createLittleHeap(int[] data, int last) {
for (int i = (last- 1) / 2; i >= 0; i--) { //找到最後一個葉子節點的雙親節點
// 儲存當前正在判斷的節點
int parent = i;
// 若當前節點的左子節點存在,即子節點存在
while (2 * parent + 1 <= last) {
// biggerIndex總是記錄較大節點的值,先賦值為當前判斷節點的左子節點
int bigger = 2 * parent + 1;//bigger指向左子節點
if (bigger < last) { //說明存在右子節點
if (data[bigger] > data[bigger+ 1]) { //右子節點>左子節點時
bigger=bigger+1;
}
}
if (data[parent] > data[bigger]) { //若雙親節點值大於子節點中最大的
// 若當前節點值比子節點最大值小,則交換2者得值,交換後將biggerIndex值賦值給k
swap(data, parent, bigger);
parent = bigger;
} else {
break;
}
}
}
}
public void print(int a[]){
for(int i=0;i<a.length;i++){
System.out.print(a[i]+" ");
}
}
public void swap(int[] data, int i, int j) {
if (i == j) {
return;
}
data[i] = data[i] + data[j];
data[j] = data[i] - data[j];
data[i] = data[i] - data[j];
}
}
堆排序需要雙層迴圈,第一層控制迴圈多少次,第二層得到每次的最小值(小頂堆)
package arrayTest;
import java.util.ArrayList;
public class Solution32 {
/* 輸入n個整數,找出其中最小的K個數。
* 例如輸入4,5,1,6,2,7,3,8這8個數字,
* 則最小的4個數字是1,2,3,4,。
* */
public ArrayList<Integer> GetLeastNumbers_Solution(int [] input, int k) {
ArrayList<Integer> result = new ArrayList<Integer>();
if(k > input.length) return result;
for(int i = 0; i < k ; i ++){//只排前k次
heapSort(input,i,input.length);//進行第i次排序
result.add(input[i]);
}
return result;
}
private void heapSort( int [] input, int root, int end){//小頂堆實現
for(int j = end -1; j >= root; j --){
int parent = (j + root -1)/2;//算出j節點的雙親節點的序號
if(input[parent] > input[j]){//雙親節點大於當前節點,交換位置。
int temp = input[j];
input[j] = input[parent];
input[parent] = temp;
}
}
}
public static void main(String[] args) {
int [] str={4,5,1,6,2,7,3,8};
Solution32 s=new Solution32();
System.out.print(s.GetLeastNumbers_Solution(str,4));
}
}
package com.wuyanru.sort;
/*
* Java實現堆排序演算法(改進)
* 由大到小排序
* author:wyr
* 2017-10-24
*兩個步驟:1,建堆 2,對頂與堆的最後一個元素交換位置
*/
public class HeapSort {
public static void main(String[] args) {
int a[] = {3,1,5,7,2,4,9,6,10,8};
HeapSort obj=new HeapSort();
System.out.println("初始值:");
obj.print(a);
for(int i=0;i<a.length;i++){
obj.createLittleHeap(a,a.length-1-i);//建立堆,建立的是小頂堆。每次迴圈完,二叉樹的根節點都是最小值,所以與此時的未排好部分最後一個值交換位置
obj.swap(a, 0, a.length - 1 - i);//與最後一個值交換位置,最小值找到了位置
obj.print(a);
System.out.println();
}
System.out.println("\n排序後:");
obj.print(a);
}
/*
* 建立小頂堆:雙親節點小於子節點的值。從葉子節點開始,直到根節點。這樣建立的堆定位最小值
*/
private void createLittleHeap(int[] data, int last) {
for(int i=last;i>0;i--){
int parent=(i-1)/2;//當前節點的雙親節點
if(data[parent]> data[i])
swap(data, parent, i);
}
}
public void print(int a[]){
for(int i=0;i<a.length;i++){
System.out.print(a[i]+" ");
}
}
public void swap(int[] data, int i, int j) {
if (i == j) {
return;
}
data[i] = data[i] + data[j];
data[j] = data[i] - data[j];
data[i] = data[i] - data[j];
}
}
分析:
設樹深度為k,![]() 。從根到葉的篩選,元素比較次數至多2(k-1)次,交換記錄至多k 次。所以,在建好堆後,排序過程中的篩選次數不超過下式:
。從根到葉的篩選,元素比較次數至多2(k-1)次,交換記錄至多k 次。所以,在建好堆後,排序過程中的篩選次數不超過下式:
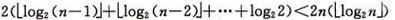
而建堆時的比較次數不超過4n 次,因此堆排序最壞情況下,時間複雜度也為:O(nlogn )。
5. 交換排序—氣泡排序(Bubble Sort)
基本思想:
在要排序的一組數中,對當前還未排好序的範圍內的全部數,自上而下對相鄰的兩個數依次進行比較和調整,讓較大的數往下沉,較小的往上冒。即:每當兩相鄰的數比較後發現它們的排序與排序要求相反時,就將它們互換。
氣泡排序的示例:
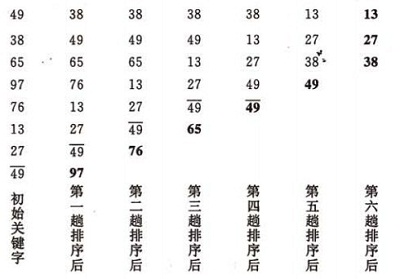
演算法的實現:
[cpp] view plain copy print?- void bubbleSort(int a[], int n){
- for(int i =0 ; i< n-1; ++i) {
- for(int j = 0; j < n-i-1; ++j) {
- if(a[j] > a[j+1])
- {
- int tmp = a[j] ; a[j] = a[j+1] ; a[j+1] = tmp;
- }
- }
- }
- }
氣泡排序演算法的改進
對氣泡排序常見的改進方法是加入一標誌性變數exchange,用於標誌某一趟排序過程中是否有資料交換,如果進行某一趟排序時並沒有進行資料交換,則說明資料已經按要求排列好,可立即結束排序,避免不必要的比較過程。本文再提供以下兩種改進演算法:
1.設定一標誌性變數pos,用於記錄每趟排序中最後一次進行交換的位置。由於pos位置之後的記錄均已交換到位,故在進行下一趟排序時只要掃描到pos位置即可。
改進後演算法如下:
[cpp] view plain copy print?- void Bubble_1 ( int r[], int n) {
- int i= n -1; //初始時,最後位置保持不變
- while ( i> 0) {
- int pos= 0; //每趟開始時,無記錄交換
- for (int j= 0; j< i; j++)
- if (r[j]> r[j+1]) {
- pos= j; //記錄交換的位置
- int tmp = r[j]; r[j]=r[j+1];r[j+1]=tmp;
- }
- i= pos; //為下一趟排序作準備
- }
- }
2.傳統氣泡排序中每一趟排序操作只能找到一個最大值或最小值,我們考慮利用在每趟排序中進行正向和反向兩遍冒泡的方法一次可以得到兩個最終值(最大者和最小者) , 從而使排序趟數幾乎減少了一半。
改進後的演算法實現為:
[cpp] view plain copy print?- void Bubble_2 ( int r[], int n){
- int low = 0;