用caffe訓練好的lenet_iter_10000.caffemodel測試單張mnist圖片
阿新 • • 發佈:2019-01-10
準備一張手寫數字圖片

注意在depoy.prototxt檔案中指定正確的該圖片的通道數。
準備一個均值檔案
因為classify.py中的測試介面caffe.Classifier需要訓練圖片的均值檔案作為輸入引數,而實際lenet-5訓練時並未計算均值檔案,所以這裡建立一個全0的均值檔案輸入。編寫一個zeronp.py檔案如下

執行
python zeronp.py修改classify.py儲存為classifymnist.py檔案
#!/usr/bin/env python
"""
classify.py is an out-of-the-box image classifer callable from the command line.
By default it configures and runs the Caffe reference ImageNet model.
""" 修改完成後執行如下命令:
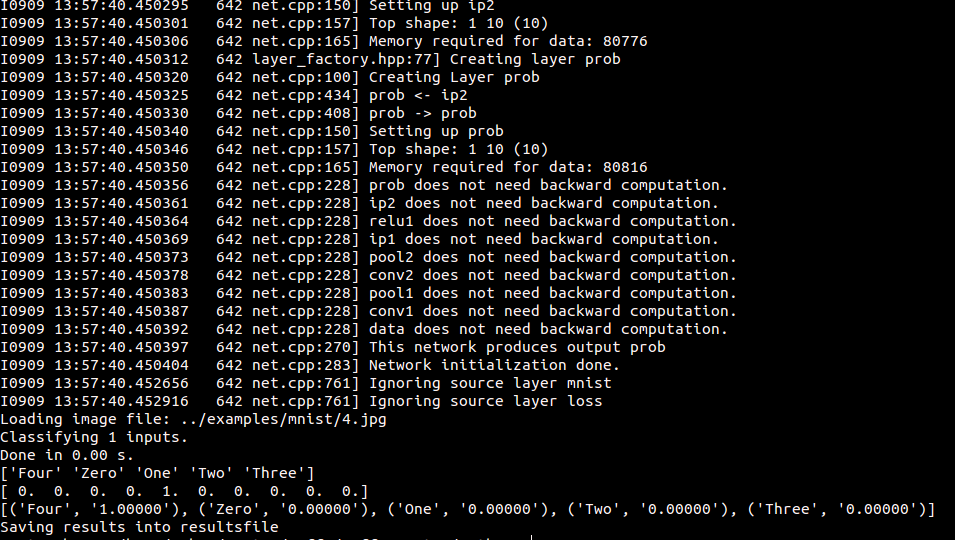
python classifymnist.py --print_results --force_grayscale --center_only --labels_file ../examples/mnist/synset_words.txt ../examples/mnist/4.jpg resultsfile得到結果如下::