
kafka配置引數說明及工作原理
阿新 • • 發佈:2019-01-10
訊息佇列的效能好壞,其檔案儲存機制設計是衡量一個訊息佇列服務技術水平和最關鍵指標之一。下面將從Kafka檔案儲存機制和物理結構角度,分析Kafka是如何實現高效檔案儲存,及實際應用效果。 1.1 Kafka的特性:- 高吞吐量、低延遲:kafka每秒可以處理幾十萬條訊息,它的延遲最低只有幾毫秒,每個topic可以分多個partition, consumer group 對partition進行consume操作。- 可擴充套件性:kafka叢集支援熱擴充套件- 永續性、可靠性:訊息被持久化到本地磁碟,並且支援資料備份防止資料丟失- 容錯性:允許叢集中節點失敗(若副本數量為n,則允許n-1個節點失敗) 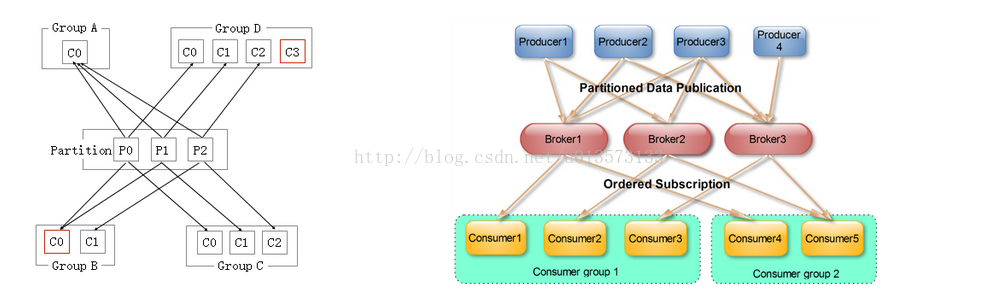 - Delivery Mode : Kafka producer 傳送message不用維護message的offsite資訊,因為這個時候,offsite就相當於一個自增id,producer就儘管傳送message就好了。而且Kafka與AMQ不同,AMQ大都用在處理業務邏輯上,而Kafka大都是日誌,所以Kafka的producer一般都是大批量的batch傳送message,向這個topic一次性發送一大批message,load balance到一個partition上,一起插進去,offsite作為自增id自己增加就好。但是Consumer端是需要維護這個partition當前消費到哪個message的offsite資訊的,這個offsite資訊,high level api是維護在Zookeeper上,low level api是自己的程式維護。(Kafka管理介面上只能顯示high level api的consumer部分,因為low level api的partition offsite資訊是程式自己維護,kafka是不知道的,無法在管理介面上展示 )當使用high level api的時候,先拿message處理,再定時自動commit offsite+1(也可以改成手動), 並且kakfa處理message是沒有鎖操作的。因此如果處理message失敗,此時還沒有commit offsite+1,當consumer thread重啟後會重複消費這個message。但是作為高吞吐量高併發的實時處理系統,at least once的情況下,至少一次會被處理到,是可以容忍的。如果無法容忍,就得使用low level api來自己程式維護這個offsite資訊,那麼想什麼時候commit offsite+1就自己搞定了。- Topic & Partition:Topic相當於傳統訊息系統MQ中的一個佇列queue,producer端傳送的message必須指定是傳送到哪個topic,但是不需要指定topic下的哪個partition,因為kafka會把收到的message進行load balance,均勻的分佈在這個topic下的不同的partition上( hash(message) % [broker數量] )。物理上儲存上,這個topic會分成一個或多個partition,每個partiton相當於是一個子queue。在物理結構上,每個partition對應一個物理的目錄(資料夾),資料夾命名是[topicname]_[partition]_[序號],一個topic可以有無數多的partition,根據業務需求和資料量來設定。在kafka配置檔案中可隨時更高num.partitions引數來配置更改topic的partition數量,在建立Topic時通過引數指定parittion數量。Topic建立之後通過Kafka提供的工具也可以修改partiton數量。 一般來說,(1)一個Topic的Partition數量大於等於Broker的數量,可以提高吞吐率。(2)同一個Partition的Replica儘量分散到不同的機器,高可用。 當add a new partition的時候,partition裡面的message不會重新進行分配,原來的partition裡面的message資料不會變,新加的這個partition剛開始是空的,隨後進入這個topic的message就會重新參與所有partition的load balance- Partition Replica:每個partition可以在其他的kafka broker節點上存副本,以便某個kafka broker節點宕機不會影響這個kafka叢集。存replica副本的方式是按照kafka broker的順序存。例如有5個kafka broker節點,某個topic有3個partition,每個partition存2個副本,那麼partition1存broker1,broker2,partition2存broker2,broker3。。。以此類推(replica副本數目不能大於kafka broker節點的數目,否則報錯。這裡的replica數其實就是partition的副本總數,其中包括一個leader,其他的就是copy副本)。這樣如果某個broker宕機,其實整個kafka內資料依然是完整的。但是,replica副本數越高,系統雖然越穩定,但是回來帶資源和效能上的下降;replica副本少的話,也會造成系統丟資料的風險。 (1)怎樣傳送訊息:producer先把message傳送到partition leader,再由leader傳送給其他partition follower。(如果讓producer傳送給每個replica那就太慢了) (2)在向Producer傳送ACK前需要保證有多少個Replica已經收到該訊息:根據ack配的個數而定 (3)怎樣處理某個Replica不工作的情況:如果這個部工作的partition replica不在ack列表中,就是producer在傳送訊息到partition leader上,partition leader向partition follower傳送message沒有響應而已,這個不會影響整個系統,也不會有什麼問題。如果這個不工作的partition replica在ack列表中的話,producer傳送的message的時候會等待這個不工作的partition replca寫message成功,但是會等到time out,然後返回失敗因為某個ack列表中的partition replica沒有響應,此時kafka會自動的把這個部工作的partition replica從ack列表中移除,以後的producer傳送message的時候就不會有這個ack列表下的這個部工作的partition replica了。 (4)怎樣處理Failed Replica恢復回來的情況:如果這個partition replica之前不在ack列表中,那麼啟動後重新受Zookeeper管理即可,之後producer傳送message的時候,partition leader會繼續傳送message到這個partition follower上。如果這個partition replica之前在ack列表中,此時重啟後,需要把這個partition replica再手動加到ack列表中。(ack列表是手動新增的,出現某個部工作的partition replica的時候自動從ack列表中移除的)- Partition leader與follower:partition也有leader和follower之分。leader是主partition,producer寫kafka的時候先寫partition leader,再由partition leader push給其他的partition follower。partition leader與follower的資訊受Zookeeper控制,一旦partition leader所在的broker節點宕機,zookeeper會衝其他的broker的partition follower上選擇follower變為parition leader。- Topic分配partition和partition replica的演算法:(1)將Broker(size=n)和待分配的Partition排序。(2)將第i個Partition分配到第(i%n)個Broker上。(3)將第i個Partition的第j個Replica分配到第((i + j) % n)個Broker上- 訊息投遞可靠性一個訊息如何算投遞成功,Kafka提供了三種模式:- 第一種是啥都不管,傳送出去就當作成功,這種情況當然不能保證訊息成功投遞到broker;- 第二種是Master-Slave模型,只有當Master和所有Slave都接收到訊息時,才算投遞成功,這種模型提供了最高的投遞可靠性,但是損傷了效能;- 第三種模型,即只要Master確認收到訊息就算投遞成功;實際使用時,根據應用特性選擇,絕大多數情況下都會中和可靠性和效能選擇第三種模型 訊息在broker上的可靠性,因為訊息會持久化到磁碟上,所以如果正常stop一個broker,其上的資料不會丟失;但是如果不正常stop,可能會使存在頁面快取來不及寫入磁碟的訊息丟失,這可以通過配置flush頁面快取的週期、閾值緩解,但是同樣會頻繁的寫磁碟會影響效能,又是一個選擇題,根據實際情況配置。 訊息消費的可靠性,Kafka提供的是“At least once”模型,因為訊息的讀取進度由offset提供,offset可以由消費者自己維護也可以維護在zookeeper裡,但是當訊息消費後consumer掛掉,offset沒有即時寫回,就有可能發生重複讀的情況,這種情況同樣可以通過調整commit offset週期、閾值緩解,甚至消費者自己把消費和commit offset做成一個事務解決,但是如果你的應用不在乎重複消費,那就乾脆不要解決,以換取最大的效能。- Partition ack:當ack=1,表示producer寫partition leader成功後,broker就返回成功,無論其他的partition follower是否寫成功。當ack=2,表示producer寫partition leader和其他一個follower成功的時候,broker就返回成功,無論其他的partition follower是否寫成功。當ack=-1[parition的數量]的時候,表示只有producer全部寫成功的時候,才算成功,kafka broker才返回成功資訊。這裡需要注意的是,如果ack=1的時候,一旦有個broker宕機導致partition的follower和leader切換,會導致丟資料。
- Delivery Mode : Kafka producer 傳送message不用維護message的offsite資訊,因為這個時候,offsite就相當於一個自增id,producer就儘管傳送message就好了。而且Kafka與AMQ不同,AMQ大都用在處理業務邏輯上,而Kafka大都是日誌,所以Kafka的producer一般都是大批量的batch傳送message,向這個topic一次性發送一大批message,load balance到一個partition上,一起插進去,offsite作為自增id自己增加就好。但是Consumer端是需要維護這個partition當前消費到哪個message的offsite資訊的,這個offsite資訊,high level api是維護在Zookeeper上,low level api是自己的程式維護。(Kafka管理介面上只能顯示high level api的consumer部分,因為low level api的partition offsite資訊是程式自己維護,kafka是不知道的,無法在管理介面上展示 )當使用high level api的時候,先拿message處理,再定時自動commit offsite+1(也可以改成手動), 並且kakfa處理message是沒有鎖操作的。因此如果處理message失敗,此時還沒有commit offsite+1,當consumer thread重啟後會重複消費這個message。但是作為高吞吐量高併發的實時處理系統,at least once的情況下,至少一次會被處理到,是可以容忍的。如果無法容忍,就得使用low level api來自己程式維護這個offsite資訊,那麼想什麼時候commit offsite+1就自己搞定了。- Topic & Partition:Topic相當於傳統訊息系統MQ中的一個佇列queue,producer端傳送的message必須指定是傳送到哪個topic,但是不需要指定topic下的哪個partition,因為kafka會把收到的message進行load balance,均勻的分佈在這個topic下的不同的partition上( hash(message) % [broker數量] )。物理上儲存上,這個topic會分成一個或多個partition,每個partiton相當於是一個子queue。在物理結構上,每個partition對應一個物理的目錄(資料夾),資料夾命名是[topicname]_[partition]_[序號],一個topic可以有無數多的partition,根據業務需求和資料量來設定。在kafka配置檔案中可隨時更高num.partitions引數來配置更改topic的partition數量,在建立Topic時通過引數指定parittion數量。Topic建立之後通過Kafka提供的工具也可以修改partiton數量。 一般來說,(1)一個Topic的Partition數量大於等於Broker的數量,可以提高吞吐率。(2)同一個Partition的Replica儘量分散到不同的機器,高可用。 當add a new partition的時候,partition裡面的message不會重新進行分配,原來的partition裡面的message資料不會變,新加的這個partition剛開始是空的,隨後進入這個topic的message就會重新參與所有partition的load balance- Partition Replica:每個partition可以在其他的kafka broker節點上存副本,以便某個kafka broker節點宕機不會影響這個kafka叢集。存replica副本的方式是按照kafka broker的順序存。例如有5個kafka broker節點,某個topic有3個partition,每個partition存2個副本,那麼partition1存broker1,broker2,partition2存broker2,broker3。。。以此類推(replica副本數目不能大於kafka broker節點的數目,否則報錯。這裡的replica數其實就是partition的副本總數,其中包括一個leader,其他的就是copy副本)。這樣如果某個broker宕機,其實整個kafka內資料依然是完整的。但是,replica副本數越高,系統雖然越穩定,但是回來帶資源和效能上的下降;replica副本少的話,也會造成系統丟資料的風險。 (1)怎樣傳送訊息:producer先把message傳送到partition leader,再由leader傳送給其他partition follower。(如果讓producer傳送給每個replica那就太慢了) (2)在向Producer傳送ACK前需要保證有多少個Replica已經收到該訊息:根據ack配的個數而定 (3)怎樣處理某個Replica不工作的情況:如果這個部工作的partition replica不在ack列表中,就是producer在傳送訊息到partition leader上,partition leader向partition follower傳送message沒有響應而已,這個不會影響整個系統,也不會有什麼問題。如果這個不工作的partition replica在ack列表中的話,producer傳送的message的時候會等待這個不工作的partition replca寫message成功,但是會等到time out,然後返回失敗因為某個ack列表中的partition replica沒有響應,此時kafka會自動的把這個部工作的partition replica從ack列表中移除,以後的producer傳送message的時候就不會有這個ack列表下的這個部工作的partition replica了。 (4)怎樣處理Failed Replica恢復回來的情況:如果這個partition replica之前不在ack列表中,那麼啟動後重新受Zookeeper管理即可,之後producer傳送message的時候,partition leader會繼續傳送message到這個partition follower上。如果這個partition replica之前在ack列表中,此時重啟後,需要把這個partition replica再手動加到ack列表中。(ack列表是手動新增的,出現某個部工作的partition replica的時候自動從ack列表中移除的)- Partition leader與follower:partition也有leader和follower之分。leader是主partition,producer寫kafka的時候先寫partition leader,再由partition leader push給其他的partition follower。partition leader與follower的資訊受Zookeeper控制,一旦partition leader所在的broker節點宕機,zookeeper會衝其他的broker的partition follower上選擇follower變為parition leader。- Topic分配partition和partition replica的演算法:(1)將Broker(size=n)和待分配的Partition排序。(2)將第i個Partition分配到第(i%n)個Broker上。(3)將第i個Partition的第j個Replica分配到第((i + j) % n)個Broker上- 訊息投遞可靠性一個訊息如何算投遞成功,Kafka提供了三種模式:- 第一種是啥都不管,傳送出去就當作成功,這種情況當然不能保證訊息成功投遞到broker;- 第二種是Master-Slave模型,只有當Master和所有Slave都接收到訊息時,才算投遞成功,這種模型提供了最高的投遞可靠性,但是損傷了效能;- 第三種模型,即只要Master確認收到訊息就算投遞成功;實際使用時,根據應用特性選擇,絕大多數情況下都會中和可靠性和效能選擇第三種模型 訊息在broker上的可靠性,因為訊息會持久化到磁碟上,所以如果正常stop一個broker,其上的資料不會丟失;但是如果不正常stop,可能會使存在頁面快取來不及寫入磁碟的訊息丟失,這可以通過配置flush頁面快取的週期、閾值緩解,但是同樣會頻繁的寫磁碟會影響效能,又是一個選擇題,根據實際情況配置。 訊息消費的可靠性,Kafka提供的是“At least once”模型,因為訊息的讀取進度由offset提供,offset可以由消費者自己維護也可以維護在zookeeper裡,但是當訊息消費後consumer掛掉,offset沒有即時寫回,就有可能發生重複讀的情況,這種情況同樣可以通過調整commit offset週期、閾值緩解,甚至消費者自己把消費和commit offset做成一個事務解決,但是如果你的應用不在乎重複消費,那就乾脆不要解決,以換取最大的效能。- Partition ack:當ack=1,表示producer寫partition leader成功後,broker就返回成功,無論其他的partition follower是否寫成功。當ack=2,表示producer寫partition leader和其他一個follower成功的時候,broker就返回成功,無論其他的partition follower是否寫成功。當ack=-1[parition的數量]的時候,表示只有producer全部寫成功的時候,才算成功,kafka broker才返回成功資訊。這裡需要注意的是,如果ack=1的時候,一旦有個broker宕機導致partition的follower和leader切換,會導致丟資料。 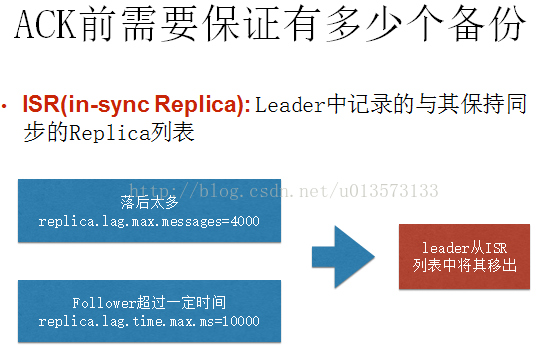

- message狀態:在Kafka中,訊息的狀態被儲存在consumer中,broker不會關心哪個訊息被消費了被誰消費了,只記錄一個offset值(指向partition中下一個要被消費的訊息位置),這就意味著如果consumer處理不好的話,broker上的一個訊息可能會被消費多次。- message持久化:Kafka中會把訊息持久化到本地檔案系統中,並且保持o(1)極高的效率。我們眾所周知IO讀取是非常耗資源的效能也是最慢的,這就是為了資料庫的瓶頸經常在IO上,需要換SSD硬碟的原因。但是Kafka作為吞吐量極高的MQ,卻可以非常高效的message持久化到檔案。這是因為Kafka是順序寫入o(1)的時間複雜度,速度非常快。也是高吞吐量的原因。由於message的寫入持久化是順序寫入的,因此message在被消費的時候也是按順序被消費的,保證partition的message是順序消費的。一般的機器,單機每秒100k條資料。- message有效期:Kafka會長久保留其中的訊息,以便consumer可以多次消費,當然其中很多細節是可配置的。- Produer : Producer向Topic傳送message,不需要指定partition,直接傳送就好了。kafka通過partition ack來控制是否傳送成功並把資訊返回給producer,producer可以有任意多的thread,這些kafka伺服器端是不care的。Producer端的delivery guarantee預設是At least once的。也可以設定Producer非同步傳送實現At most once。Producer可以用主鍵冪等性實現Exactly once- Kafka高吞吐量: Kafka的高吞吐量體現在讀寫上,分散式併發的讀和寫都非常快,寫的效能體現在以o(1)的時間複雜度進行順序寫入。讀的效能體現在以o(1)的時間複雜度進行順序讀取, 對topic進行partition分割槽,consume group中的consume執行緒可以以很高能效能進行順序讀。- Kafka delivery guarantee(message傳送保證):(1)At most once訊息可能會丟,絕對不會重複傳輸;(2)At least once 訊息絕對不會丟,但是可能會重複傳輸;(3)Exactly once每條資訊肯定會被傳輸一次且僅傳輸一次,這是使用者想要的。- 批量傳送:Kafka支援以訊息集合為單位進行批量傳送,以提高push效率。- push-and-pull : Kafka中的Producer和consumer採用的是push-and-pull模式,即Producer只管向broker push訊息,consumer只管從broker pull訊息,兩者對訊息的生產和消費是非同步的。- Kafka叢集中broker之間的關係:不是主從關係,各個broker在叢集中地位一樣,我們可以隨意的增加或刪除任何一個broker節點。- 負載均衡方面: Kafka提供了一個 metadata API來管理broker之間的負載(對Kafka0.8.x而言,對於0.7.x主要靠zookeeper來實現負載均衡)。- 同步非同步:Producer採用非同步push方式,極大提高Kafka系統的吞吐率(可以通過引數控制是採用同步還是非同步方式)。- 分割槽機制partition:Kafka的broker端支援訊息分割槽partition,Producer可以決定把訊息發到哪個partition,在一個partition 中message的順序就是Producer傳送訊息的順序,一個topic中可以有多個partition,具體partition的數量是可配置的。partition的概念使得kafka作為MQ可以橫向擴充套件,吞吐量巨大。partition可以設定replica副本,replica副本存在不同的kafka broker節點上,第一個partition是leader,其他的是follower,message先寫到partition leader上,再由partition leader push到parition follower上。所以說kafka可以水平擴充套件,也就是擴充套件partition。- 離線資料裝載:Kafka由於對可拓展的資料持久化的支援,它也非常適合向Hadoop或者資料倉庫中進行資料裝載。- 實時資料與離線資料:kafka既支援離線資料也支援實時資料,因為kafka的message持久化到檔案,並可以設定有效期,因此可以把kafka作為一個高效的儲存來使用,可以作為離線資料供後面的分析。當然作為分散式實時訊息系統,大多數情況下還是用於實時的資料處理的,但是當cosumer消費能力下降的時候可以通過message的持久化在淤積資料在kafka。- 外掛支援:現在不少活躍的社群已經開發出不少外掛來拓展Kafka的功能,如用來配合Storm、Hadoop、flume相關的外掛。- 解耦: 相當於一個MQ,使得Producer和Consumer之間非同步的操作,系統之間解耦- 冗餘: replica有多個副本,保證一個broker node宕機後不會影響整個服務- 擴充套件性: broker節點可以水平擴充套件,partition也可以水平增加,partition replica也可以水平增加- 峰值: 在訪問量劇增的情況下,kafka水平擴充套件, 應用仍然需要繼續發揮作用- 可恢復性: 系統的一部分元件失效時,由於有partition的replica副本,不會影響到整個系統。- 順序保證性:由於kafka的producer的寫message與consumer去讀message都是順序的讀寫,保證了高效的效能。- 緩衝:由於producer那面可能業務很簡單,而後端consumer業務會很複雜並有資料庫的操作,因此肯定是producer會比consumer處理速度快,如果沒有kafka,producer直接呼叫consumer,那麼就會造成整個系統的處理速度慢,加一層kafka作為MQ,可以起到緩衝的作用。- 非同步通訊:作為MQ,Producer與Consumer非同步通訊
- Delivery Mode : Kafka producer 傳送message不用維護message的offsite資訊,因為這個時候,offsite就相當於一個自增id,producer就儘管傳送message就好了。而且Kafka與AMQ不同,AMQ大都用在處理業務邏輯上,而Kafka大都是日誌,所以Kafka的producer一般都是大批量的batch傳送message,向這個topic一次性發送一大批message,load balance到一個partition上,一起插進去,offsite作為自增id自己增加就好。但是Consumer端是需要維護這個partition當前消費到哪個message的offsite資訊的,這個offsite資訊,high level api是維護在Zookeeper上,low level api是自己的程式維護。(Kafka管理介面上只能顯示high level api的consumer部分,因為low level api的partition offsite資訊是程式自己維護,kafka是不知道的,無法在管理介面上展示 )當使用high level api的時候,先拿message處理,再定時自動commit offsite+1(也可以改成手動), 並且kakfa處理message是沒有鎖操作的。因此如果處理message失敗,此時還沒有commit offsite+1,當consumer thread重啟後會重複消費這個message。但是作為高吞吐量高併發的實時處理系統,at least once的情況下,至少一次會被處理到,是可以容忍的。如果無法容忍,就得使用low level api來自己程式維護這個offsite資訊,那麼想什麼時候commit offsite+1就自己搞定了。- Topic & Partition:Topic相當於傳統訊息系統MQ中的一個佇列queue,producer端傳送的message必須指定是傳送到哪個topic,但是不需要指定topic下的哪個partition,因為kafka會把收到的message進行load balance,均勻的分佈在這個topic下的不同的partition上( hash(message) % [broker數量] )。物理上儲存上,這個topic會分成一個或多個partition,每個partiton相當於是一個子queue。在物理結構上,每個partition對應一個物理的目錄(資料夾),資料夾命名是[topicname]_[partition]_[序號],一個topic可以有無數多的partition,根據業務需求和資料量來設定。在kafka配置檔案中可隨時更高num.partitions引數來配置更改topic的partition數量,在建立Topic時通過引數指定parittion數量。Topic建立之後通過Kafka提供的工具也可以修改partiton數量。 一般來說,(1)一個Topic的Partition數量大於等於Broker的數量,可以提高吞吐率。(2)同一個Partition的Replica儘量分散到不同的機器,高可用。 當add a new partition的時候,partition裡面的message不會重新進行分配,原來的partition裡面的message資料不會變,新加的這個partition剛開始是空的,隨後進入這個topic的message就會重新參與所有partition的load balance- Partition Replica:每個partition可以在其他的kafka broker節點上存副本,以便某個kafka broker節點宕機不會影響這個kafka叢集。存replica副本的方式是按照kafka broker的順序存。例如有5個kafka broker節點,某個topic有3個partition,每個partition存2個副本,那麼partition1存broker1,broker2,partition2存broker2,broker3。。。以此類推(replica副本數目不能大於kafka broker節點的數目,否則報錯。這裡的replica數其實就是partition的副本總數,其中包括一個leader,其他的就是copy副本)。這樣如果某個broker宕機,其實整個kafka內資料依然是完整的。但是,replica副本數越高,系統雖然越穩定,但是回來帶資源和效能上的下降;replica副本少的話,也會造成系統丟資料的風險。 (1)怎樣傳送訊息:producer先把message傳送到partition leader,再由leader傳送給其他partition follower。(如果讓producer傳送給每個replica那就太慢了) (2)在向Producer傳送ACK前需要保證有多少個Replica已經收到該訊息:根據ack配的個數而定 (3)怎樣處理某個Replica不工作的情況:如果這個部工作的partition replica不在ack列表中,就是producer在傳送訊息到partition leader上,partition leader向partition follower傳送message沒有響應而已,這個不會影響整個系統,也不會有什麼問題。如果這個不工作的partition replica在ack列表中的話,producer傳送的message的時候會等待這個不工作的partition replca寫message成功,但是會等到time out,然後返回失敗因為某個ack列表中的partition replica沒有響應,此時kafka會自動的把這個部工作的partition replica從ack列表中移除,以後的producer傳送message的時候就不會有這個ack列表下的這個部工作的partition replica了。 (4)怎樣處理Failed Replica恢復回來的情況:如果這個partition replica之前不在ack列表中,那麼啟動後重新受Zookeeper管理即可,之後producer傳送message的時候,partition leader會繼續傳送message到這個partition follower上。如果這個partition replica之前在ack列表中,此時重啟後,需要把這個partition replica再手動加到ack列表中。(ack列表是手動新增的,出現某個部工作的partition replica的時候自動從ack列表中移除的)- Partition leader與follower:partition也有leader和follower之分。leader是主partition,producer寫kafka的時候先寫partition leader,再由partition leader push給其他的partition follower。partition leader與follower的資訊受Zookeeper控制,一旦partition leader所在的broker節點宕機,zookeeper會衝其他的broker的partition follower上選擇follower變為parition leader。- Topic分配partition和partition replica的演算法:(1)將Broker(size=n)和待分配的Partition排序。(2)將第i個Partition分配到第(i%n)個Broker上。(3)將第i個Partition的第j個Replica分配到第((i + j) % n)個Broker上- 訊息投遞可靠性一個訊息如何算投遞成功,Kafka提供了三種模式:- 第一種是啥都不管,傳送出去就當作成功,這種情況當然不能保證訊息成功投遞到broker;- 第二種是Master-Slave模型,只有當Master和所有Slave都接收到訊息時,才算投遞成功,這種模型提供了最高的投遞可靠性,但是損傷了效能;- 第三種模型,即只要Master確認收到訊息就算投遞成功;實際使用時,根據應用特性選擇,絕大多數情況下都會中和可靠性和效能選擇第三種模型 訊息在broker上的可靠性,因為訊息會持久化到磁碟上,所以如果正常stop一個broker,其上的資料不會丟失;但是如果不正常stop,可能會使存在頁面快取來不及寫入磁碟的訊息丟失,這可以通過配置flush頁面快取的週期、閾值緩解,但是同樣會頻繁的寫磁碟會影響效能,又是一個選擇題,根據實際情況配置。 訊息消費的可靠性,Kafka提供的是“At least once”模型,因為訊息的讀取進度由offset提供,offset可以由消費者自己維護也可以維護在zookeeper裡,但是當訊息消費後consumer掛掉,offset沒有即時寫回,就有可能發生重複讀的情況,這種情況同樣可以通過調整commit offset週期、閾值緩解,甚至消費者自己把消費和commit offset做成一個事務解決,但是如果你的應用不在乎重複消費,那就乾脆不要解決,以換取最大的效能。- Partition ack:當ack=1,表示producer寫partition leader成功後,broker就返回成功,無論其他的partition follower是否寫成功。當ack=2,表示producer寫partition leader和其他一個follower成功的時候,broker就返回成功,無論其他的partition follower是否寫成功。當ack=-1[parition的數量]的時候,表示只有producer全部寫成功的時候,才算成功,kafka broker才返回成功資訊。這裡需要注意的是,如果ack=1的時候,一旦有個broker宕機導致partition的follower和leader切換,會導致丟資料。 - message狀態:在Kafka中,訊息的狀態被儲存在consumer中,broker不會關心哪個訊息被消費了被誰消費了,只記錄一個offset值(指向partition中下一個要被消費的訊息位置),這就意味著如果consumer處理不好的話,broker上的一個訊息可能會被消費多次。- message持久化:Kafka中會把訊息持久化到本地檔案系統中,並且保持o(1)極高的效率。我們眾所周知IO讀取是非常耗資源的效能也是最慢的,這就是為了資料庫的瓶頸經常在IO上,需要換SSD硬碟的原因。但是Kafka作為吞吐量極高的MQ,卻可以非常高效的message持久化到檔案。這是因為Kafka是順序寫入o(1)的時間複雜度,速度非常快。也是高吞吐量的原因。由於message的寫入持久化是順序寫入的,因此message在被消費的時候也是按順序被消費的,保證partition的message是順序消費的。一般的機器,單機每秒100k條資料。- message有效期:Kafka會長久保留其中的訊息,以便consumer可以多次消費,當然其中很多細節是可配置的。- Produer : Producer向Topic傳送message,不需要指定partition,直接傳送就好了。kafka通過partition ack來控制是否傳送成功並把資訊返回給producer,producer可以有任意多的thread,這些kafka伺服器端是不care的。Producer端的delivery guarantee預設是At least once的。也可以設定Producer非同步傳送實現At most once。Producer可以用主鍵冪等性實現Exactly once- Kafka高吞吐量: Kafka的高吞吐量體現在讀寫上,分散式併發的讀和寫都非常快,寫的效能體現在以o(1)的時間複雜度進行順序寫入。讀的效能體現在以o(1)的時間複雜度進行順序讀取, 對topic進行partition分割槽,consume group中的consume執行緒可以以很高能效能進行順序讀。- Kafka delivery guarantee(message傳送保證):(1)At most once訊息可能會丟,絕對不會重複傳輸;(2)At least once 訊息絕對不會丟,但是可能會重複傳輸;(3)Exactly once每條資訊肯定會被傳輸一次且僅傳輸一次,這是使用者想要的。- 批量傳送:Kafka支援以訊息集合為單位進行批量傳送,以提高push效率。- push-and-pull : Kafka中的Producer和consumer採用的是push-and-pull模式,即Producer只管向broker push訊息,consumer只管從broker pull訊息,兩者對訊息的生產和消費是非同步的。- Kafka叢集中broker之間的關係:不是主從關係,各個broker在叢集中地位一樣,我們可以隨意的增加或刪除任何一個broker節點。- 負載均衡方面: Kafka提供了一個 metadata API來管理broker之間的負載(對Kafka0.8.x而言,對於0.7.x主要靠zookeeper來實現負載均衡)。- 同步非同步:Producer採用非同步push方式,極大提高Kafka系統的吞吐率(可以通過引數控制是採用同步還是非同步方式)。- 分割槽機制partition:Kafka的broker端支援訊息分割槽partition,Producer可以決定把訊息發到哪個partition,在一個partition 中message的順序就是Producer傳送訊息的順序,一個topic中可以有多個partition,具體partition的數量是可配置的。partition的概念使得kafka作為MQ可以橫向擴充套件,吞吐量巨大。partition可以設定replica副本,replica副本存在不同的kafka broker節點上,第一個partition是leader,其他的是follower,message先寫到partition leader上,再由partition leader push到parition follower上。所以說kafka可以水平擴充套件,也就是擴充套件partition。- 離線資料裝載:Kafka由於對可拓展的資料持久化的支援,它也非常適合向Hadoop或者資料倉庫中進行資料裝載。- 實時資料與離線資料:kafka既支援離線資料也支援實時資料,因為kafka的message持久化到檔案,並可以設定有效期,因此可以把kafka作為一個高效的儲存來使用,可以作為離線資料供後面的分析。當然作為分散式實時訊息系統,大多數情況下還是用於實時的資料處理的,但是當cosumer消費能力下降的時候可以通過message的持久化在淤積資料在kafka。- 外掛支援:現在不少活躍的社群已經開發出不少外掛來拓展Kafka的功能,如用來配合Storm、Hadoop、flume相關的外掛。- 解耦: 相當於一個MQ,使得Producer和Consumer之間非同步的操作,系統之間解耦- 冗餘: replica有多個副本,保證一個broker node宕機後不會影響整個服務- 擴充套件性: broker節點可以水平擴充套件,partition也可以水平增加,partition replica也可以水平增加- 峰值: 在訪問量劇增的情況下,kafka水平擴充套件, 應用仍然需要繼續發揮作用- 可恢復性: 系統的一部分元件失效時,由於有partition的replica副本,不會影響到整個系統。- 順序保證性:由於kafka的producer的寫message與consumer去讀message都是順序的讀寫,保證了高效的效能。- 緩衝:由於producer那面可能業務很簡單,而後端consumer業務會很複雜並有資料庫的操作,因此肯定是producer會比consumer處理速度快,如果沒有kafka,producer直接呼叫consumer,那麼就會造成整個系統的處理速度慢,加一層kafka作為MQ,可以起到緩衝的作用。- 非同步通訊:作為MQ,Producer與Consumer非同步通訊